 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shallow Waters to Mariana Trench: A Survey of Bio-inspired Underwater Soft Robots
Jan 18, 2026Sample Exploring the ocean environment holds profound significance in areas such as resource exploration and ecological protection. Underwater robots struggle with extreme water pressure and often cause noise and damage to the underwater ecosystem, while bio-inspired soft robots draw inspiration from aquatic creatures to address these challenges. These bio-inspired approaches enable robots to withstand high water pressure, minimize drag, operate with efficient manipulation and sensing systems, and interact with the environment in an eco-friendly manner. Consequently, bio-inspired soft robots have emerged as a promising field for ocean exploration. This paper reviews recent advancements in underwater bio-inspired soft robots, analyses their design considerations when facing different desired functions, bio-inspirations, ambient pressure, temperature, light, and biodiversity , and finally explores the progression from bio-inspired principles to practical applications in the field and suggests potential directions for developing the next generation of underwater soft robots.
Enhancing Conversational Recommender Systems with Tree-Structured Knowledge and Pretrained Language Models
Nov 16, 2025



Recent advances in pretrained language models (PLMs) have significantly improved conversational recommender systems (CRS), enabling more fluent and context-aware interactions. To further enhance accuracy and mitigate hallucination, many methods integrate PLMs with knowledge graphs (KGs), but face key challenges: failing to fully exploit PLM reasoning over graph relationships, indiscriminately incorporating retrieved knowledge without context filtering, and neglecting collaborative preferences in multi-turn dialogues. To this end, we propose PCRS-TKA, a prompt-based framework employing retrieval-augmented generation to integrate PLMs with KGs. PCRS-TKA constructs dialogue-specific knowledge trees from KGs and serializes them into texts, enabling structure-aware reasoning while capturing rich entity semantics. Our approach selectively filters context-relevant knowledge and explicitly models collaborative preferences using specialized supervision signals. A semantic alignment module harmonizes heterogeneous inputs, reducing noise and enhancing accuracy. Extensive experiments demonstrate that PCRS-TKA consistently outperforms all baselines in both recommendation and conversational quality.
Large Scalable Cross-Domain Graph Neural Networks for Personalized Notification at LinkedIn
Jun 15, 2025



Notification recommendation systems are critical to driving user engagement on professional platforms like LinkedIn. Designing such systems involves integrating heterogeneous signals across domains, capturing temporal dynamics, and optimizing for multiple, often competing, objectives. Graph Neural Networks (GNNs) provide a powerful framework for modeling complex interactions in such environments. In this paper, we present a cross-domain GNN-based system deployed at LinkedIn that unifies user, content, and activity signals into a single, large-scale graph. By training on this cross-domain structure, our model significantly outperforms single-domain baselines on key tasks, including click-through rate (CTR) prediction and professional engagement. We introduce architectural innovations including temporal modeling and multi-task learning, which further enhance performance. Deployed in LinkedIn's notification system, our approach led to a 0.10% lift in weekly active users and a 0.62% improvement in CTR. We detail our graph construction process, model design, training pipeline, and both offline and online evaluations. Our work demonstrates the scalability and effectiveness of cross-domain GNNs in real-world, high-impact applications.
QAMA: Quantum annealing multi-head attention operator with classical deep learning framework
Apr 15, 2025As large language models scale up, the conventional attention mechanism faces critical challenges of exponential growth in memory consumption and energy costs. Quantum annealing computing, with its inherent advantages in computational efficiency and low energy consumption, offers an innovative direction for constructing novel deep learning architectures. This study proposes the first Quantum Annealing-based Multi-head Attention (QAMA) mechanism, achieving seamless compatibility with classical attention architectures through quadratic unconstrained binary optimization (QUBO) modeling of forward propagation and energy-based backpropagation. The method innovatively leverages the quantum bit interaction characteristics of Ising models to optimize the conventional $O(n^2)$ spatiotemporal complexity into linear resource consumption. Integrated with the optical computing advantages of coherent Ising machines (CIM), the system maintains millisecond-level real-time responsiveness while significantly reducing energy consumption. Our key contributions include: Theoretical proofs establish QAMA mathematical equivalence to classical attention mechanisms; Dual optimization of multi-head specificity and long-range information capture via QUBO constraints; Explicit gradient proofs for the Ising energy equation are utilized to implement gradient conduction as the only path in the computational graph as a layer; Proposed soft selection mechanism overcoming traditional binary attention limitations to approximate continuous weights. Experiments on QBoson CPQC quantum computer show QAMA achieves comparable accuracy to classical operators while reducing inference time to millisecond level and improving solution quality. This work pioneers architectural-level integration of quantum computing and deep learning, applicable to any attention-based model, driving paradigm innovation in AI foundational computing.
Sell It Before You Make It: Revolutionizing E-Commerce with Personalized AI-Generated Items
Mar 28, 2025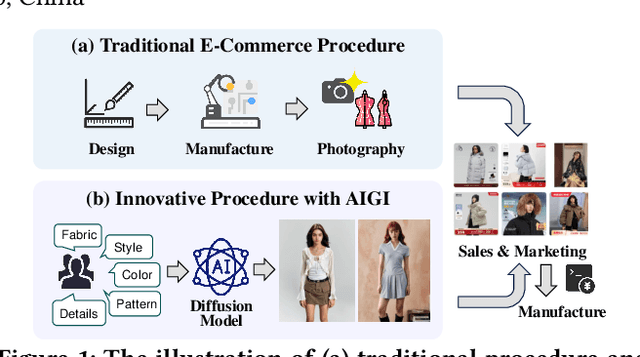
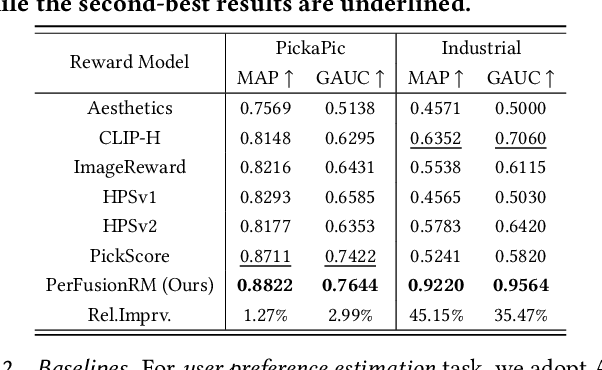
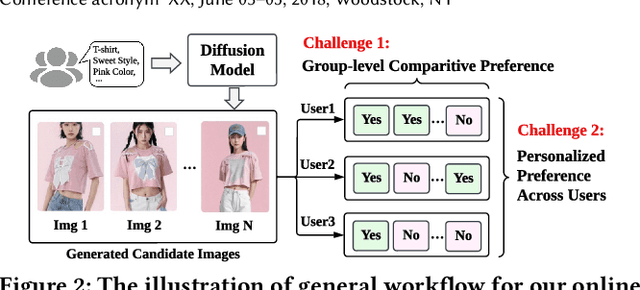
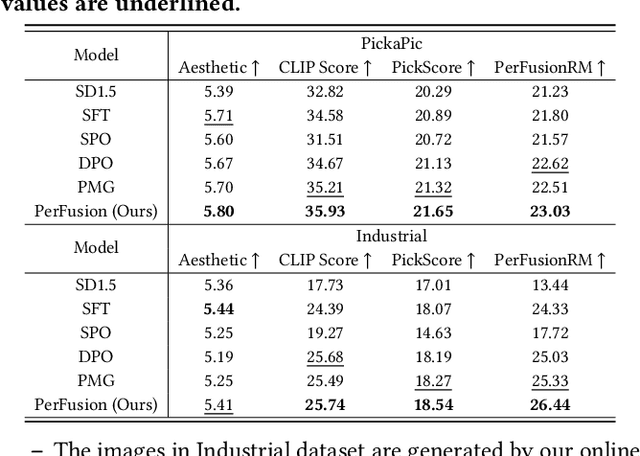
E-commerce has revolutionized retail, yet its traditional workflows remain inefficient, with significant time and resource costs tied to product design and manufacturing inventory. This paper introduces a novel system deployed at Alibaba that leverages AI-generated items (AIGI) to address these challenges with personalized text-to-image generation for e-commercial product design. AIGI enables an innovative business mode called "sell it before you make it", where merchants can design fashion items and generate photorealistic images with digital models based on textual descriptions. Only when the items have received a certain number of orders, do the merchants start to produce them, which largely reduces reliance on physical prototypes and thus accelerates time to market. For such a promising application, we identify the underlying key scientific challenge, i.e., capturing the users' group-level personalized preferences towards multiple generated candidate images. To this end, we propose a Personalized Group-Level Preference Alignment Framework for Diffusion Models (i.e., PerFusion). We first design PerFusion Reward Model for user preference estimation with a feature-crossing-based personalized plug-in. Then we develop PerFusion with a personalized adaptive network to model diverse preferences across users, and meanwhile derive the group-level preference optimization objective to capture the comparative behaviors among multiple candidates. Both offline and online experiments demonstrate the effectiveness of our proposed algorithm. The AI-generated items have achieved over 13% relative improvements for both click-through rate and conversion rate compared to their human-designed counterparts, validating the revolutionary potential of AI-generated items for e-commercial platforms.
RLCAD: Reinforcement Learning Training Gym for Revolution Involved CAD Command Sequence Generation
Mar 24, 2025A CAD command sequence is a typical parametric design paradigm in 3D CAD systems where a model is constructed by overlaying 2D sketches with operations such as extrusion, revolution, and Boolean operations. Although there is growing academic interest in the automatic generation of command sequences, existing methods and datasets only support operations such as 2D sketching, extrusion,and Boolean operations. This limitation makes it challenging to represent more complex geometries. In this paper, we present a reinforcement learning (RL) training environment (gym) built on a CAD geometric engine. Given an input boundary representation (B-Rep) geometry, the policy network in the RL algorithm generates an action. This action, along with previously generated actions, is processed within the gym to produce the corresponding CAD geometry, which is then fed back into the policy network. The rewards, determined by the difference between the generated and target geometries within the gym, are used to update the RL network. Our method supports operations beyond sketches, Boolean, and extrusion, including revolution operations. With this training gym, we achieve state-of-the-art (SOTA) quality in generating command sequences from B-Rep geometries. In addition, our method can significantly improve the efficiency of command sequence generation by a factor of 39X compared with the previous training gym.
A Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
TruePose: Human-Parsing-guided Attention Diffusion for Full-ID Preserving Pose Transfer
Feb 05, 2025Pose-Guided Person Image Synthesis (PGPIS) generates images that maintain a subject's identity from a source image while adopting a specified target pose (e.g., skeleton). While diffusion-based PGPIS methods effectively preserve facial features during pose transformation, they often struggle to accurately maintain clothing details from the source image throughout the diffusion process. This limitation becomes particularly problematic when there is a substantial difference between the source and target poses, significantly impacting PGPIS applications in the fashion industry where clothing style preservation is crucial for copyright protection. Our analysis reveals that this limitation primarily stems from the conditional diffusion model's attention modules failing to adequately capture and preserve clothing patterns. To address this limitation, we propose human-parsing-guided attention diffusion, a novel approach that effectively preserves both facial and clothing appearance while generating high-quality results. We propose a human-parsing-aware Siamese network that consists of three key components: dual identical UNets (TargetNet for diffusion denoising and SourceNet for source image embedding extraction), a human-parsing-guided fusion attention (HPFA), and a CLIP-guided attention alignment (CAA). The HPFA and CAA modules can embed the face and clothes patterns into the target image generation adaptively and effectively. Extensive experiments on both the in-shop clothes retrieval benchmark and the latest in-the-wild human editing dataset demonstrate our method's significant advantages over 13 baseline approaches for preserving both facial and clothes appearance in the source image.
ZSL-RPPO: Zero-Shot Learning for Quadrupedal Locomotion in Challenging Terrains using Recurrent Proximal Policy Optimization
Mar 04, 2024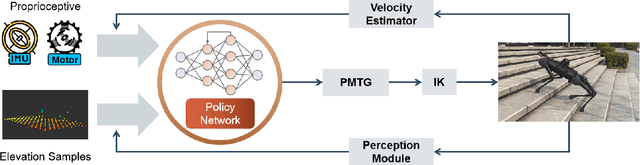
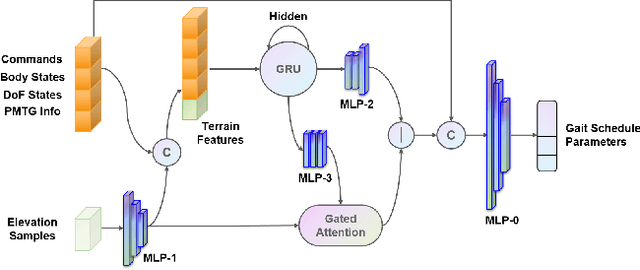
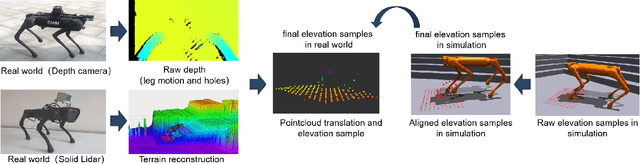
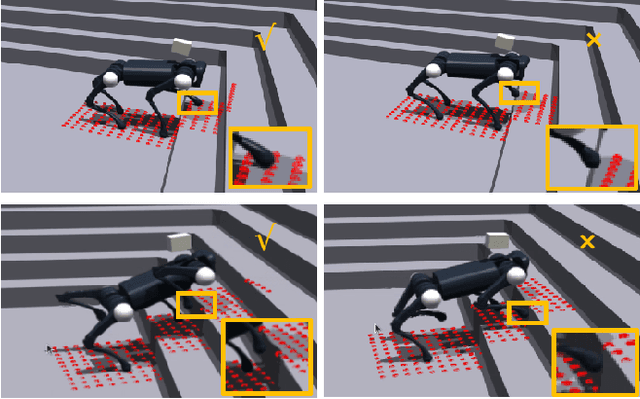
We present ZSL-RPPO, an improved zero-shot learning architecture that overcomes the limitations of teacher-student neural networks and enables generating robust, reliable, and versatile locomotion for quadrupedal robots in challenging terrains. We propose a new algorithm RPPO (Recurrent Proximal Policy Optimization) that directly trains recurrent neural network in partially observable environments and results in more robust training using domain randomization. Our locomotion controller supports extensive perturbation across simulation-to-reality transfer for both intrinsic and extrinsic physical parameters without further fine-tuning. This can avoid the significant decline of student's performance during simulation-to-reality transfer and therefore enhance the robustness and generalization of the locomotion controller. We deployed our controller on the Unitree A1 and Aliengo robots in real environment and exteroceptive perception is provided by either a solid-state Lidar or a depth camera. Our locomotion controller was tested in various challenging terrains like slippery surfaces, Grassy Terrain, and stairs. Our experiment results and comparison show that our approach significantly outperforms the state-of-the-art.