 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024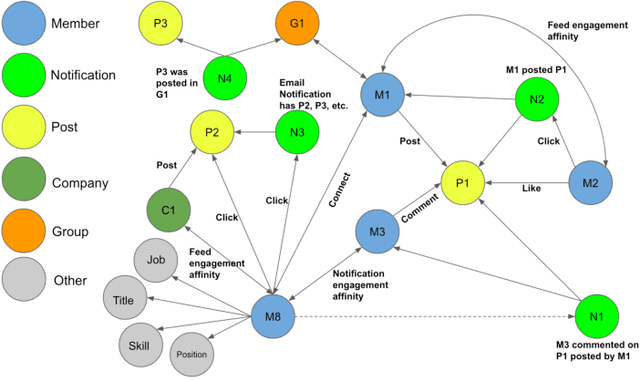


In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
Learn Locally, Correct Globally: A Distributed Algorithm for Training Graph Neural Networks
Dec 07, 2021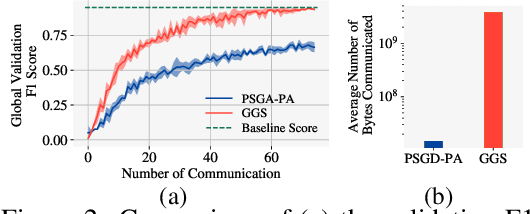

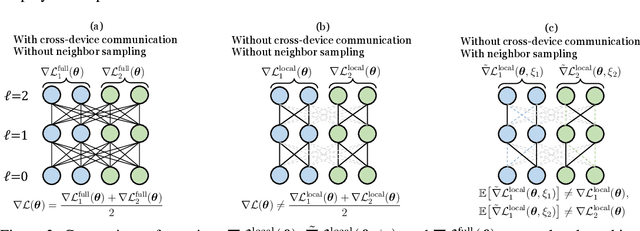
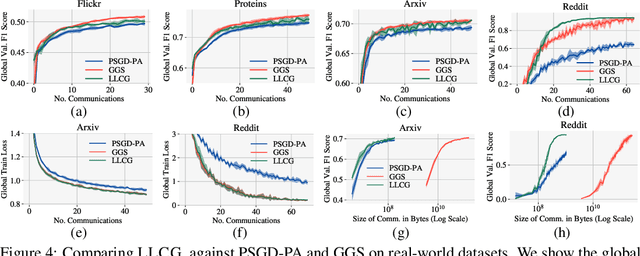
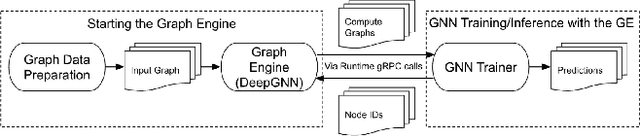
Despite the recent success of Graph Neural Networks (GNNs), training GNNs on large graphs remains challenging. The limited resource capacities of the existing servers, the dependency between nodes in a graph, and the privacy concern due to the centralized storage and model learning have spurred the need to design an effective distributed algorithm for GNN training. However, existing distributed GNN training methods impose either excessive communication costs or large memory overheads that hinders their scalability. To overcome these issues, we propose a communication-efficient distributed GNN training technique named $\text{{Learn Locally, Correct Globally}}$ (LLCG). To reduce the communication and memory overhead, each local machine in LLCG first trains a GNN on its local data by ignoring the dependency between nodes among different machines, then sends the locally trained model to the server for periodic model averaging. However, ignoring node dependency could result in significant performance degradation. To solve the performance degradation, we propose to apply $\text{{Global Server Corrections}}$ on the server to refine the locally learned models. We rigorously analyze the convergence of distributed methods with periodic model averaging for training GNNs and show that naively applying periodic model averaging but ignoring the dependency between nodes will suffer from an irreducible residual error. However, this residual error can be eliminated by utilizing the proposed global corrections to entail fast convergence rate. Extensive experiments on real-world datasets show that LLCG can significantly improve the efficiency without hurting the performance.
On Provable Benefits of Depth in Training Graph Convolutional Networks
Oct 28, 2021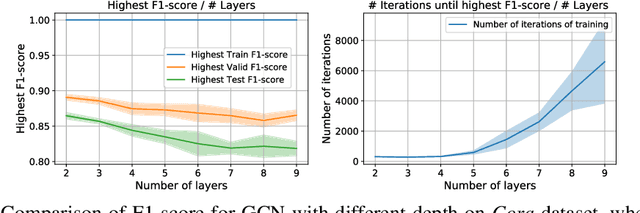

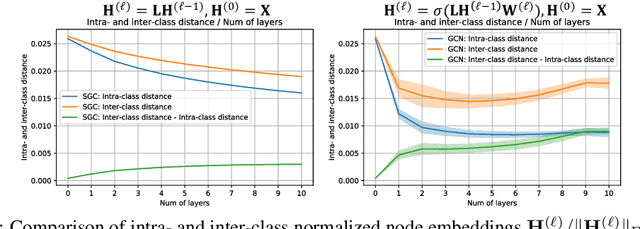
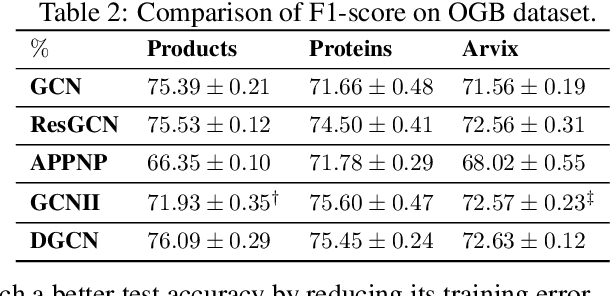
Graph Convolutional Networks (GCNs) are known to suffer from performance degradation as the number of layers increases, which is usually attributed to over-smoothing. Despite the apparent consensus, we observe that there exists a discrepancy between the theoretical understanding of over-smoothing and the practical capabilities of GCNs. Specifically, we argue that over-smoothing does not necessarily happen in practice, a deeper model is provably expressive, can converge to global optimum with linear convergence rate, and achieve very high training accuracy as long as properly trained. Despite being capable of achieving high training accuracy, empirical results show that the deeper models generalize poorly on the testing stage and existing theoretical understanding of such behavior remains elusive. To achieve better understanding, we carefully analyze the generalization capability of GCNs, and show that the training strategies to achieve high training accuracy significantly deteriorate the generalization capability of GCNs. Motivated by these findings, we propose a decoupled structure for GCNs that detaches weight matrices from feature propagation to preserve the expressive power and ensure good generalization performance. We conduct empirical evaluations on various synthetic and real-world datasets to validate the correctness of our theory.
On the Importance of Sampling in Learning Graph Convolutional Networks
Mar 03, 2021
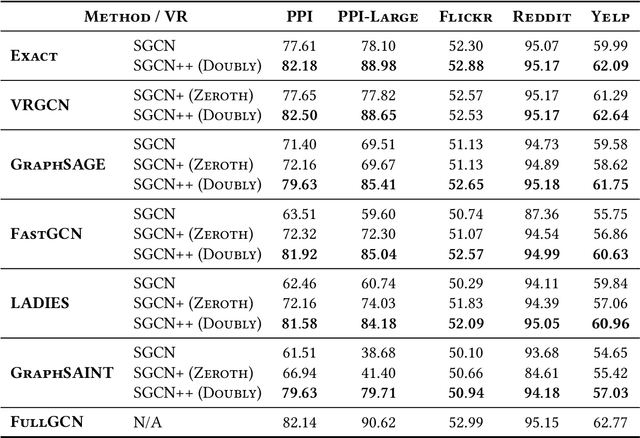
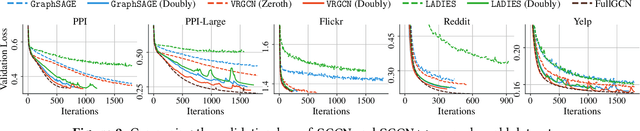

Graph Convolutional Networks (GCNs) have achieved impressive empirical advancement across a wide variety of graph-related applications. Despite their great success, training GCNs on large graphs suffers from computational and memory issues. A potential path to circumvent these obstacles is sampling-based methods, where at each layer a subset of nodes is sampled. Although recent studies have empirically demonstrated the effectiveness of sampling-based methods, these works lack theoretical convergence guarantees under realistic settings and cannot fully leverage the information of evolving parameters during optimization. In this paper, we describe and analyze a general \textbf{\textit{doubly variance reduction}} schema that can accelerate any sampling method under the memory budget. The motivating impetus for the proposed schema is a careful analysis for the variance of sampling methods where it is shown that the induced variance can be decomposed into node embedding approximation variance (\emph{zeroth-order variance}) during forward propagation and layerwise-gradient variance (\emph{first-order variance}) during backward propagation. We theoretically analyze the convergence of the proposed schema and show that it enjoys an $\mathcal{O}(1/T)$ convergence rate. We complement our theoretical results by integrating the proposed schema in different sampling methods and applying them to different large real-world graphs. Code is public available at~\url{https://github.com/CongWeilin/SGCN.git}.