 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinkSAGE: Optimizing Job Matching Using Graph Neural Networks
Feb 20, 2024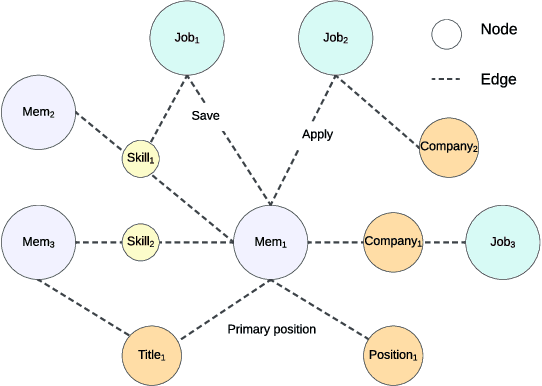


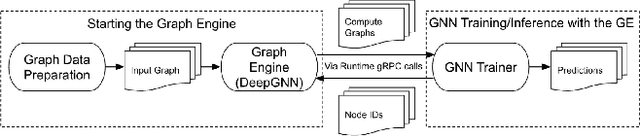
We present LinkSAGE, an innovative framework that integrates Graph Neural Networks (GNNs) into large-scale personalized job matching systems, designed to address the complex dynamics of LinkedIns extensive professional network. Our approach capitalizes on a novel job marketplace graph, the largest and most intricate of its kind in industry, with billions of nodes and edges. This graph is not merely extensive but also richly detailed, encompassing member and job nodes along with key attributes, thus creating an expansive and interwoven network. A key innovation in LinkSAGE is its training and serving methodology, which effectively combines inductive graph learning on a heterogeneous, evolving graph with an encoder-decoder GNN model. This methodology decouples the training of the GNN model from that of existing Deep Neural Nets (DNN) models, eliminating the need for frequent GNN retraining while maintaining up-to-date graph signals in near realtime, allowing for the effective integration of GNN insights through transfer learning. The subsequent nearline inference system serves the GNN encoder within a real-world setting, significantly reducing online latency and obviating the need for costly real-time GNN infrastructure. Validated across multiple online A/B tests in diverse product scenarios, LinkSAGE demonstrates marked improvements in member engagement, relevance matching, and member retention, confirming its generalizability and practical impact.
LiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024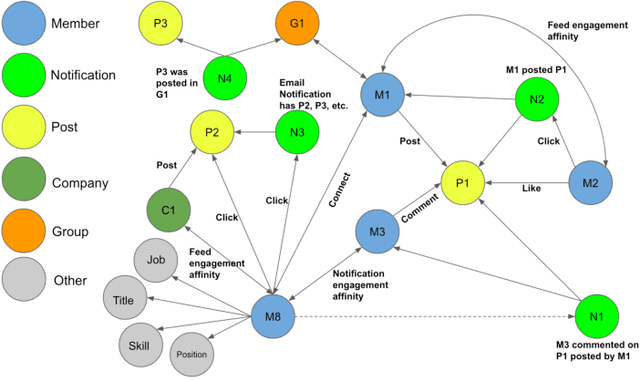


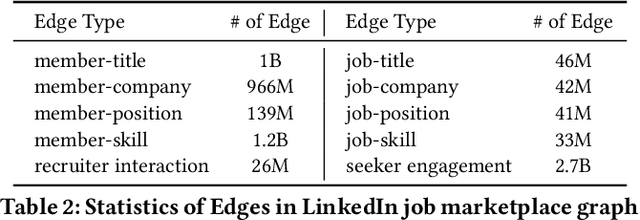
In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024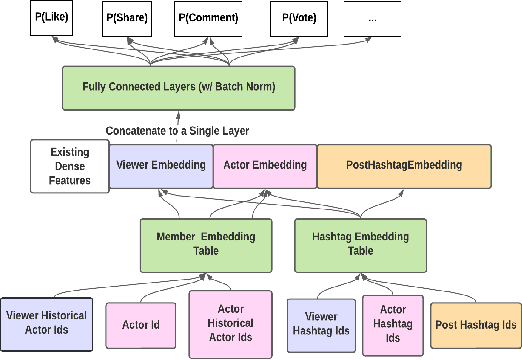

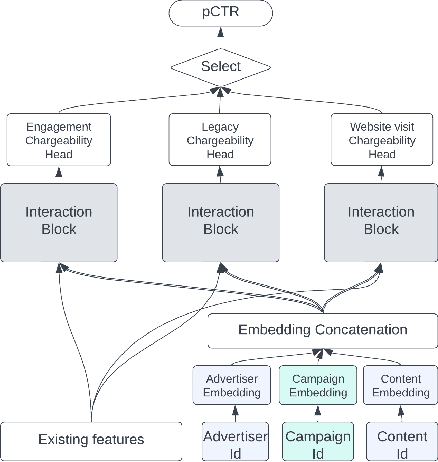

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.