 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
LiNR: Model Based Neural Retrieval on GPUs at LinkedIn
Jul 18, 2024



This paper introduces LiNR, LinkedIn's large-scale, GPU-based retrieval system. LiNR supports a billion-sized index on GPU models. We discuss our experiences and challenges in creating scalable, differentiable search indexes using TensorFlow and PyTorch at production scale. In LiNR, both items and model weights are integrated into the model binary. Viewing index construction as a form of model training, we describe scaling our system for large indexes, incorporating full scans and efficient filtering. A key focus is on enabling attribute-based pre-filtering for exhaustive GPU searches, addressing the common challenge of post-filtering in KNN searches that often reduces system quality. We further provide multi-embedding retrieval algorithms and strategies for tackling cold start issues in retrieval. Our advancements in supporting larger indexes through quantization are also discussed. We believe LiNR represents one of the industry's first Live-updated model-based retrieval indexes. Applied to out-of-network post recommendations on LinkedIn Feed, LiNR has contributed to a 3% relative increase in professional daily active users. We envisage LiNR as a step towards integrating retrieval and ranking into a single GPU model, simplifying complex infrastructures and enabling end-to-end optimization of the entire differentiable infrastructure through gradient descent.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024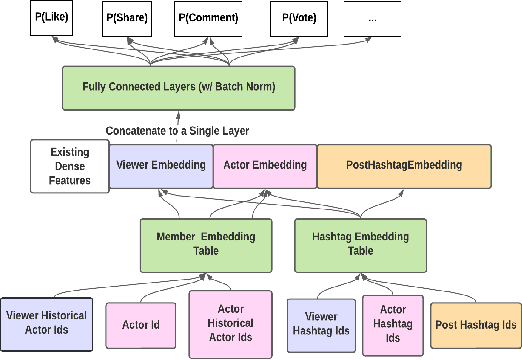

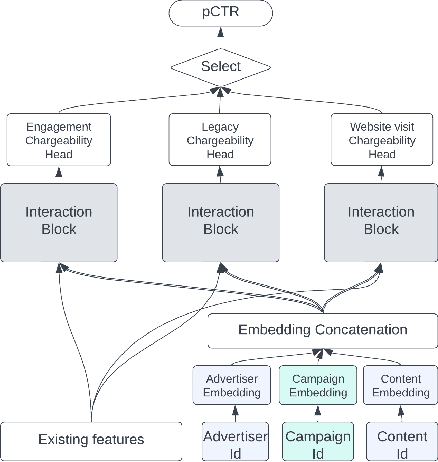

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.