 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024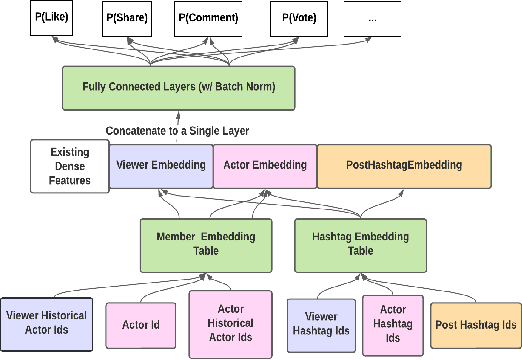

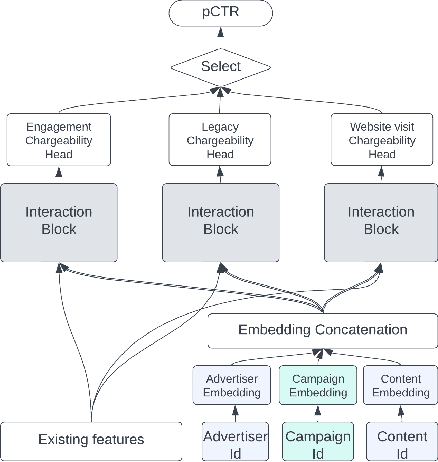

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching
Aug 05, 2023We study a particular matching task we call Music Cold-Start Matching. In short, given a cold-start song request, we expect to retrieve songs with similar audiences and then fastly push the cold-start song to the audiences of the retrieved songs to warm up it. However, there are hardly any studies done on this task. Therefore, in this paper, we will formalize the problem of Music Cold-Start Matching detailedly and give a scheme. During the offline training, we attempt to learn high-quality song representations based on song content features. But, we find supervision signals typically follow power-law distribution causing skewed representation learning. To address this issue, we propose a novel contrastive learning paradigm named Bootstrapping Contrastive Learning (BCL) to enhance the quality of learned representations by exerting contrastive regularization. During the online serving, to locate the target audiences more accurately, we propose Clustering-based Audience Targeting (CAT) that clusters audience representations to acquire a few cluster centroids and then locate the target audiences by measuring the relevance between the audience representations and the cluster centroids. Extensive experiments on the offline dataset and online system demonstrate the effectiveness and efficiency of our method. Currently, we have deployed it on NetEase Cloud Music, affecting millions of users. Code will be released in the future.
* Accepted by WWW'2023