 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
An Industrial-Scale Sequential Recommender for LinkedIn Feed Ranking
Feb 12, 2026LinkedIn Feed enables professionals worldwide to discover relevant content, build connections, and share knowledge at scale. We present Feed Sequential Recommender (Feed-SR), a transformer-based sequential ranking model for LinkedIn Feed that replaces a DCNv2-based ranker and meets strict production constraints. We detail the modeling choices, training techniques, and serving optimizations that enable deployment at LinkedIn scale. Feed-SR is currently the primary member experience on LinkedIn's Feed and shows significant improvements in member engagement (+2.10% time spent) in online A/B tests compared to the existing production model. We also describe our deployment experience with alternative sequential and LLM-based ranking architectures and why Feed-SR provided the best combination of online metrics and production efficiency.
CADET: Context-Conditioned Ads CTR Prediction With a Decoder-Only Transformer
Feb 11, 2026Click-through rate (CTR) prediction is fundamental to online advertising systems. While Deep Learning Recommendation Models (DLRMs) with explicit feature interactions have long dominated this domain, recent advances in generative recommenders have shown promising results in content recommendation. However, adapting these transformer-based architectures to ads CTR prediction still presents unique challenges, including handling post-scoring contextual signals, maintaining offline-online consistency, and scaling to industrial workloads. We present CADET (Context-Conditioned Ads Decoder-Only Transformer), an end-to-end decoder-only transformer for ads CTR prediction deployed at LinkedIn. Our approach introduces several key innovations: (1) a context-conditioned decoding architecture with multi-tower prediction heads that explicitly model post-scoring signals such as ad position, resolving the chicken-and-egg problem between predicted CTR and ranking; (2) a self-gated attention mechanism that stabilizes training by adaptively regulating information flow at both representation and interaction levels; (3) a timestamp-based variant of Rotary Position Embedding (RoPE) that captures temporal relationships across timescales from seconds to months; (4) session masking strategies that prevent the model from learning dependencies on unavailable in-session events, addressing train-serve skew; and (5) production engineering techniques including tensor packing, sequence chunking, and custom Flash Attention kernels that enable efficient training and serving at scale. In online A/B testing, CADET achieves a 11.04\% CTR lift compared to the production LiRank baseline model, a hybrid ensemble of DCNv2 and sequential encoders. The system has been successfully deployed on LinkedIn's advertising platform, serving the main traffic for homefeed sponsored updates.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
High Fidelity Textual User Representation over Heterogeneous Sources via Reinforcement Learning
Feb 07, 2026Effective personalization on large-scale job platforms requires modeling members based on heterogeneous textual sources, including profiles, professional data, and search activity logs. As recommender systems increasingly adopt Large Language Models (LLMs), creating unified, interpretable, and concise representations from heterogeneous sources becomes critical, especially for latency-sensitive online environments. In this work, we propose a novel Reinforcement Learning (RL) framework to synthesize a unified textual representation for each member. Our approach leverages implicit user engagement signals (e.g., clicks, applies) as the primary reward to distill salient information. Additionally, the framework is complemented by rule-based rewards that enforce formatting and length constraints. Extensive offline experiments across multiple LinkedIn products, one of the world's largest job platforms, demonstrate significant improvements in key downstream business metrics. This work provides a practical, labeling-free, and scalable solution for constructing interpretable user representations that are directly compatible with LLM-based systems.
Large Scalable Cross-Domain Graph Neural Networks for Personalized Notification at LinkedIn
Jun 15, 2025



Notification recommendation systems are critical to driving user engagement on professional platforms like LinkedIn. Designing such systems involves integrating heterogeneous signals across domains, capturing temporal dynamics, and optimizing for multiple, often competing, objectives. Graph Neural Networks (GNNs) provide a powerful framework for modeling complex interactions in such environments. In this paper, we present a cross-domain GNN-based system deployed at LinkedIn that unifies user, content, and activity signals into a single, large-scale graph. By training on this cross-domain structure, our model significantly outperforms single-domain baselines on key tasks, including click-through rate (CTR) prediction and professional engagement. We introduce architectural innovations including temporal modeling and multi-task learning, which further enhance performance. Deployed in LinkedIn's notification system, our approach led to a 0.10% lift in weekly active users and a 0.62% improvement in CTR. We detail our graph construction process, model design, training pipeline, and both offline and online evaluations. Our work demonstrates the scalability and effectiveness of cross-domain GNNs in real-world, high-impact applications.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
Efficient user history modeling with amortized inference for deep learning recommendation models
Dec 09, 2024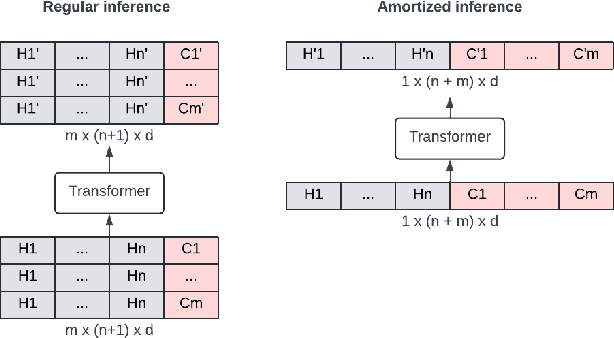
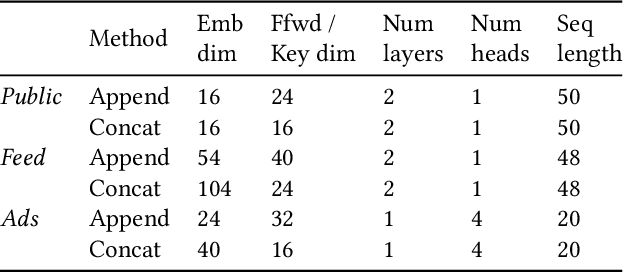
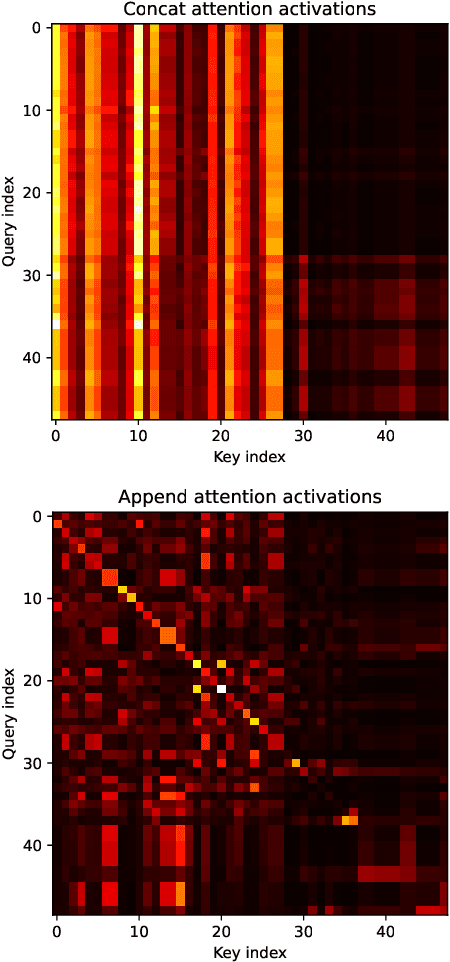
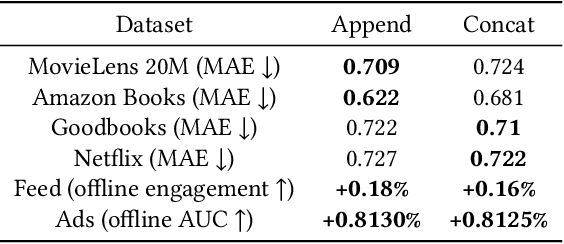
We study user history modeling via Transformer encoders in deep learning recommendation models (DLRM). Such architectures can significantly improve recommendation quality, but usually incur high latency cost necessitating infrastructure upgrades or very small Transformer models. An important part of user history modeling is early fusion of the candidate item and various methods have been studied. We revisit early fusion and compare concatenation of the candidate to each history item against appending it to the end of the list as a separate item. Using the latter method, allows us to reformulate the recently proposed amortized history inference algorithm M-FALCON \cite{zhai2024actions} for the case of DLRM models. We show via experimental results that appending with cross-attention performs on par with concatenation and that amortization significantly reduces inference costs. We conclude with results from deploying this model on the LinkedIn Feed and Ads surfaces, where amortization reduces latency by 30\% compared to non-amortized inference.
LiNR: Model Based Neural Retrieval on GPUs at LinkedIn
Jul 18, 2024



This paper introduces LiNR, LinkedIn's large-scale, GPU-based retrieval system. LiNR supports a billion-sized index on GPU models. We discuss our experiences and challenges in creating scalable, differentiable search indexes using TensorFlow and PyTorch at production scale. In LiNR, both items and model weights are integrated into the model binary. Viewing index construction as a form of model training, we describe scaling our system for large indexes, incorporating full scans and efficient filtering. A key focus is on enabling attribute-based pre-filtering for exhaustive GPU searches, addressing the common challenge of post-filtering in KNN searches that often reduces system quality. We further provide multi-embedding retrieval algorithms and strategies for tackling cold start issues in retrieval. Our advancements in supporting larger indexes through quantization are also discussed. We believe LiNR represents one of the industry's first Live-updated model-based retrieval indexes. Applied to out-of-network post recommendations on LinkedIn Feed, LiNR has contributed to a 3% relative increase in professional daily active users. We envisage LiNR as a step towards integrating retrieval and ranking into a single GPU model, simplifying complex infrastructures and enabling end-to-end optimization of the entire differentiable infrastructure through gradient descent.