 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADET: Context-Conditioned Ads CTR Prediction With a Decoder-Only Transformer
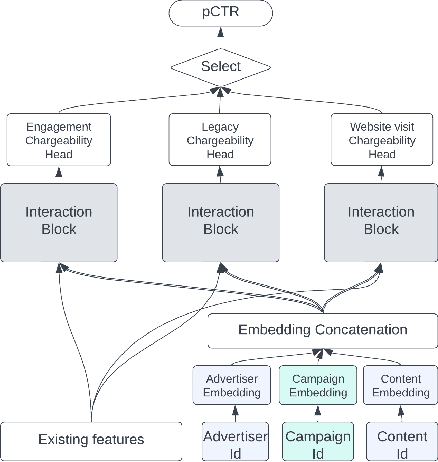
Feb 11, 2026Click-through rate (CTR) prediction is fundamental to online advertising systems. While Deep Learning Recommendation Models (DLRMs) with explicit feature interactions have long dominated this domain, recent advances in generative recommenders have shown promising results in content recommendation. However, adapting these transformer-based architectures to ads CTR prediction still presents unique challenges, including handling post-scoring contextual signals, maintaining offline-online consistency, and scaling to industrial workloads. We present CADET (Context-Conditioned Ads Decoder-Only Transformer), an end-to-end decoder-only transformer for ads CTR prediction deployed at LinkedIn. Our approach introduces several key innovations: (1) a context-conditioned decoding architecture with multi-tower prediction heads that explicitly model post-scoring signals such as ad position, resolving the chicken-and-egg problem between predicted CTR and ranking; (2) a self-gated attention mechanism that stabilizes training by adaptively regulating information flow at both representation and interaction levels; (3) a timestamp-based variant of Rotary Position Embedding (RoPE) that captures temporal relationships across timescales from seconds to months; (4) session masking strategies that prevent the model from learning dependencies on unavailable in-session events, addressing train-serve skew; and (5) production engineering techniques including tensor packing, sequence chunking, and custom Flash Attention kernels that enable efficient training and serving at scale. In online A/B testing, CADET achieves a 11.04\% CTR lift compared to the production LiRank baseline model, a hybrid ensemble of DCNv2 and sequential encoders. The system has been successfully deployed on LinkedIn's advertising platform, serving the main traffic for homefeed sponsored updates.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
Efficient user history modeling with amortized inference for deep learning recommendation models
Dec 09, 2024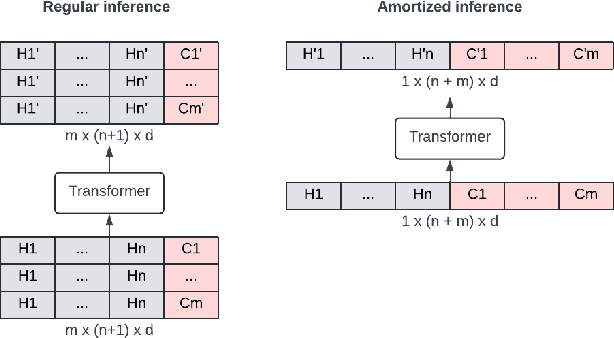
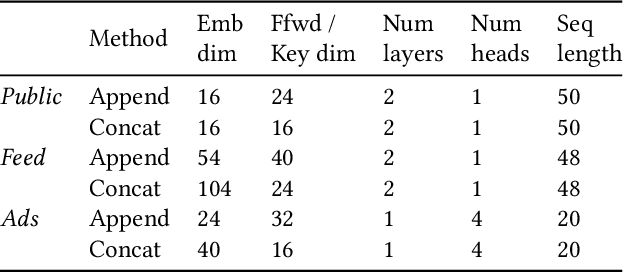
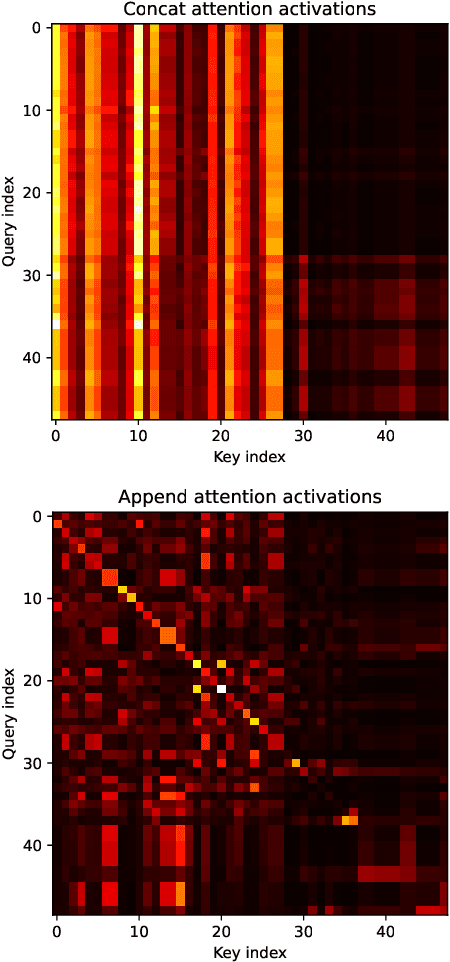
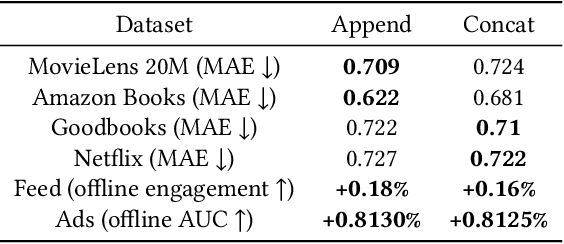
We study user history modeling via Transformer encoders in deep learning recommendation models (DLRM). Such architectures can significantly improve recommendation quality, but usually incur high latency cost necessitating infrastructure upgrades or very small Transformer models. An important part of user history modeling is early fusion of the candidate item and various methods have been studied. We revisit early fusion and compare concatenation of the candidate to each history item against appending it to the end of the list as a separate item. Using the latter method, allows us to reformulate the recently proposed amortized history inference algorithm M-FALCON \cite{zhai2024actions} for the case of DLRM models. We show via experimental results that appending with cross-attention performs on par with concatenation and that amortization significantly reduces inference costs. We conclude with results from deploying this model on the LinkedIn Feed and Ads surfaces, where amortization reduces latency by 30\% compared to non-amortized inference.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024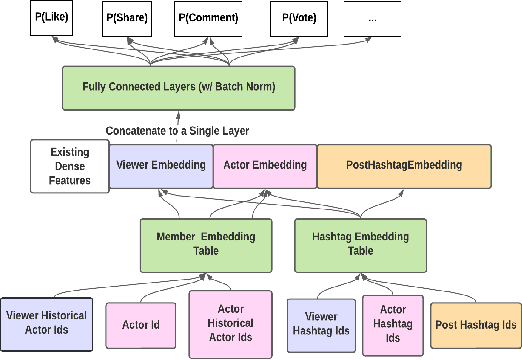


We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.