 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient user history modeling with amortized inference for deep learning recommendation models
Paper and Code
Dec 09, 2024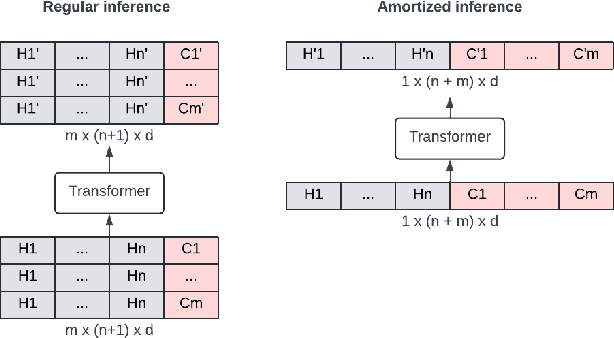
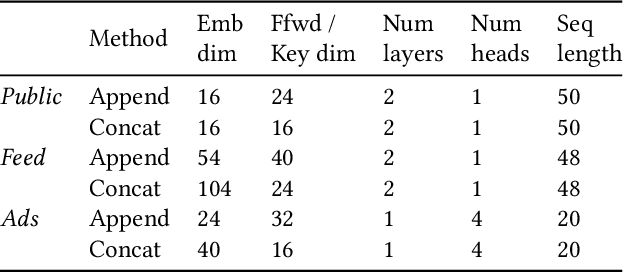
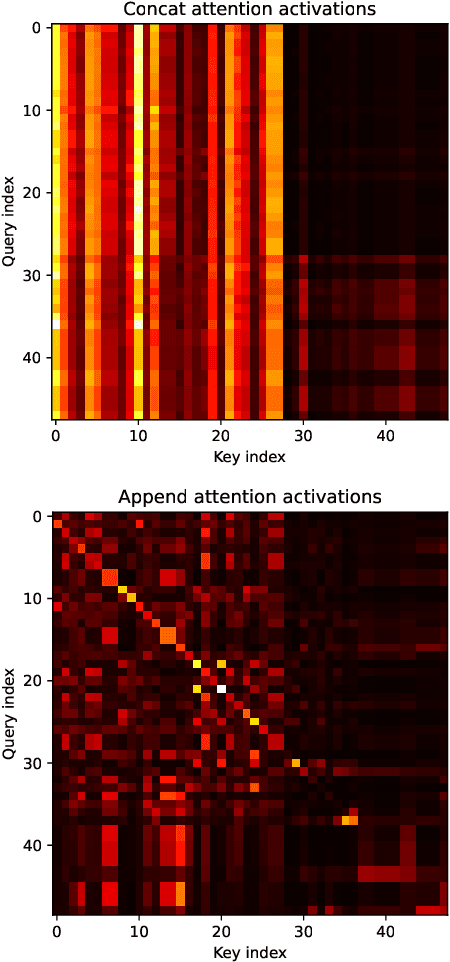
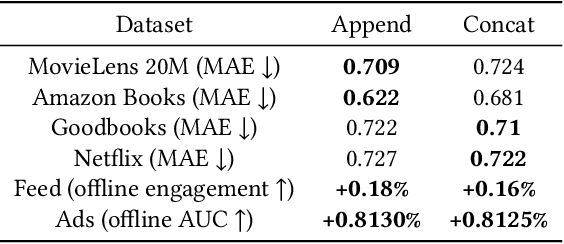
We study user history modeling via Transformer encoders in deep learning recommendation models (DLRM). Such architectures can significantly improve recommendation quality, but usually incur high latency cost necessitating infrastructure upgrades or very small Transformer models. An important part of user history modeling is early fusion of the candidate item and various methods have been studied. We revisit early fusion and compare concatenation of the candidate to each history item against appending it to the end of the list as a separate item. Using the latter method, allows us to reformulate the recently proposed amortized history inference algorithm M-FALCON \cite{zhai2024actions} for the case of DLRM models. We show via experimental results that appending with cross-attention performs on par with concatenation and that amortization significantly reduces inference costs. We conclude with results from deploying this model on the LinkedIn Feed and Ads surfaces, where amortization reduces latency by 30\% compared to non-amortized inference.