 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024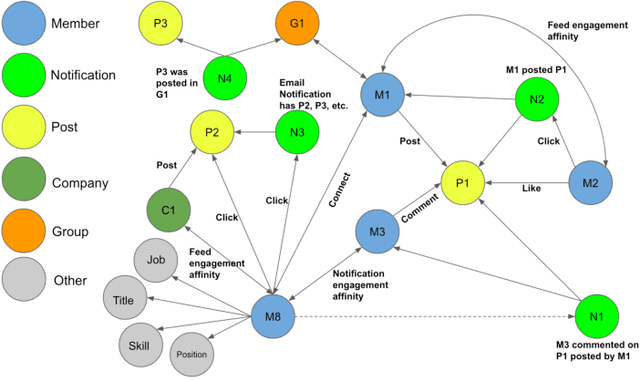

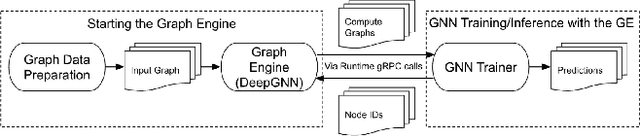

In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024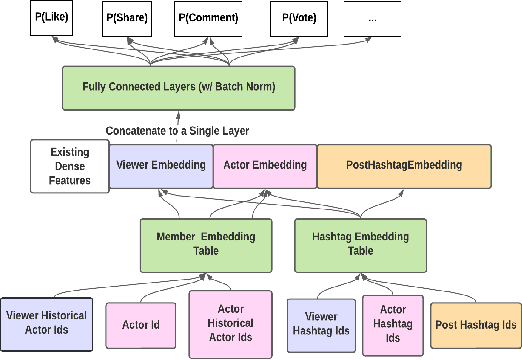

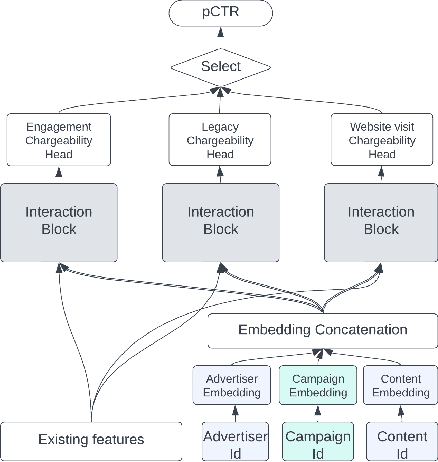

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
MultiSlot ReRanker: A Generic Model-based Re-Ranking Framework in Recommendation Systems
Jan 11, 2024In this paper, we propose a generic model-based re-ranking framework, MultiSlot ReRanker, which simultaneously optimizes relevance, diversity, and freshness. Specifically, our Sequential Greedy Algorithm (SGA) is efficient enough (linear time complexity) for large-scale production recommendation engines. It achieved a lift of $+6\%$ to $ +10\%$ offline Area Under the receiver operating characteristic Curve (AUC) which is mainly due to explicitly modeling mutual influences among items of a list, and leveraging the second pass ranking scores of multiple objectives. In addition, we have generalized the offline replay theory to multi-slot re-ranking scenarios, with trade-offs among multiple objectives. The offline replay results can be further improved by Pareto Optimality. Moreover, we've built a multi-slot re-ranking simulator based on OpenAI Gym integrated with the Ray framework. It can be easily configured for different assumptions to quickly benchmark both reinforcement learning and supervised learning algorithms.
Personalization and Optimization of Decision Parameters via Heterogenous Causal Effects
Feb 04, 2019


Randomized experimentation (also known as A/B testing or bucket testing) is very commonly used in the internet industry to measure the effect of a new treatment. Often, the decision on the basis of such A/B testing is to ramp the treatment variant that did best for the entire population. However, the effect of any given treatment varies across experimental units, and choosing a single variant to ramp to the whole population can be quite suboptimal. In this work, we propose a method which automatically identifies the collection of cohorts exhibiting heterogeneous treatment effect (using causal trees). We then use stochastic optimization to identify the optimal treatment variant in each cohort. We use two real-life examples - one related to serving notifications and the other related to modulating ads density on feed. In both examples, using offline simulation and online experimentation, we demonstrate the benefits of our approach. At the time of writing this paper, the method described has been deployed on the LinkedIn Ads and Notifications system.
Measuring Long-term Impact of Ads on LinkedIn Feed
Jan 29, 2019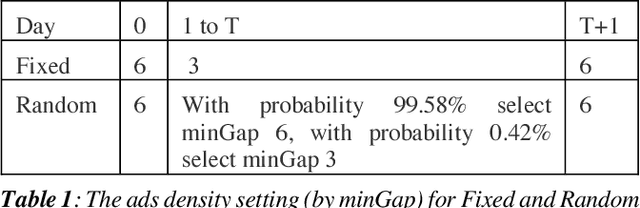
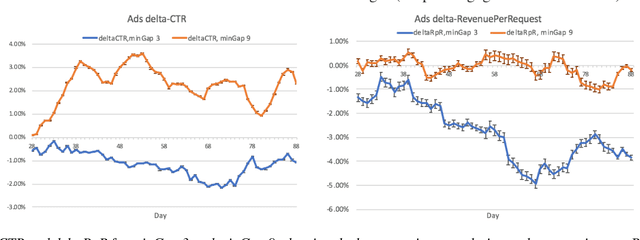
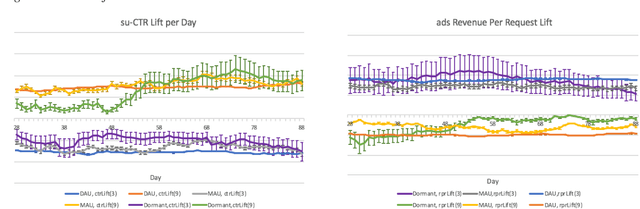
Organic updates (from a member's network) and sponsored updates (or ads, from advertisers) together form the newsfeed on LinkedIn. The newsfeed, the default homepage for members, attracts them to engage, brings them value and helps LinkedIn grow. Engagement and Revenue on feed are two critical, yet often conflicting objectives. Hence, it is important to design a good Revenue-Engagement Tradeoff (RENT) mechanism to blend ads in the feed. In this paper, we design experiments to understand how members' behavior evolve over time given different ads experiences. These experiences vary on ads density, while the quality of ads (ensured by relevance models) is held constant. Our experiments have been conducted on randomized member buckets and we use two experimental designs to measure the short term and long term effects of the various treatments. Based on the first three months' data, we observe that the long term impact is at a much smaller scale than the short term impact in our application. Furthermore, we observe different member cohorts (based on user activity level) adapt and react differently over time.