 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024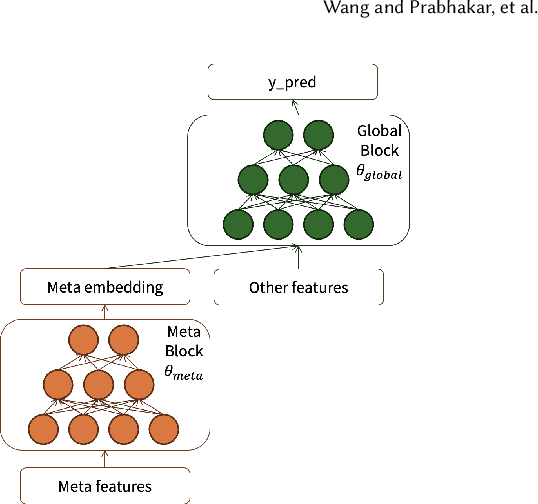

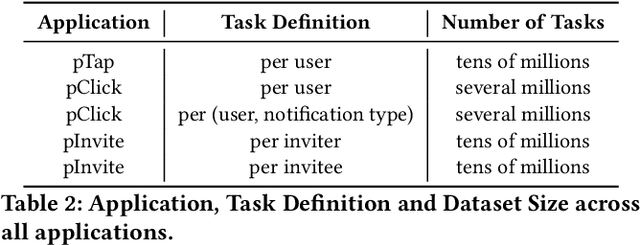

In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
MultiSlot ReRanker: A Generic Model-based Re-Ranking Framework in Recommendation Systems
Jan 11, 2024In this paper, we propose a generic model-based re-ranking framework, MultiSlot ReRanker, which simultaneously optimizes relevance, diversity, and freshness. Specifically, our Sequential Greedy Algorithm (SGA) is efficient enough (linear time complexity) for large-scale production recommendation engines. It achieved a lift of $+6\%$ to $ +10\%$ offline Area Under the receiver operating characteristic Curve (AUC) which is mainly due to explicitly modeling mutual influences among items of a list, and leveraging the second pass ranking scores of multiple objectives. In addition, we have generalized the offline replay theory to multi-slot re-ranking scenarios, with trade-offs among multiple objectives. The offline replay results can be further improved by Pareto Optimality. Moreover, we've built a multi-slot re-ranking simulator based on OpenAI Gym integrated with the Ray framework. It can be easily configured for different assumptions to quickly benchmark both reinforcement learning and supervised learning algorithms.
Multi-objective Optimization of Notifications Using Offline Reinforcement Learning
Jul 07, 2022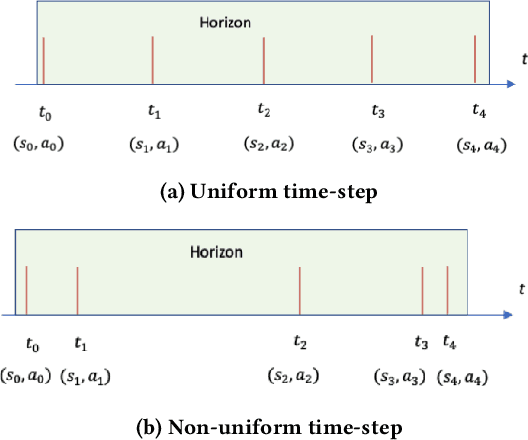

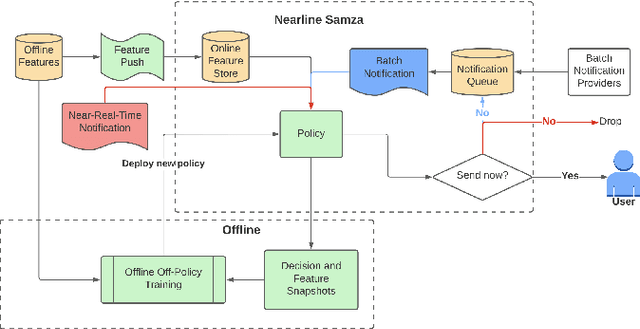
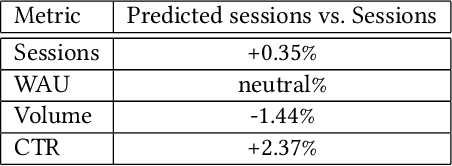
Mobile notification systems play a major role in a variety of applications to communicate, send alerts and reminders to the users to inform them about news, events or messages. In this paper, we formulate the near-real-time notification decision problem as a Markov Decision Process where we optimize for multiple objectives in the rewards. We propose an end-to-end offline reinforcement learning framework to optimize sequential notification decisions. We address the challenge of offline learning using a Double Deep Q-network method based on Conservative Q-learning that mitigates the distributional shift problem and Q-value overestimation. We illustrate our fully-deployed system and demonstrate the performance and benefits of the proposed approach through both offline and online experiments.
Offline Reinforcement Learning for Mobile Notifications
Feb 04, 2022
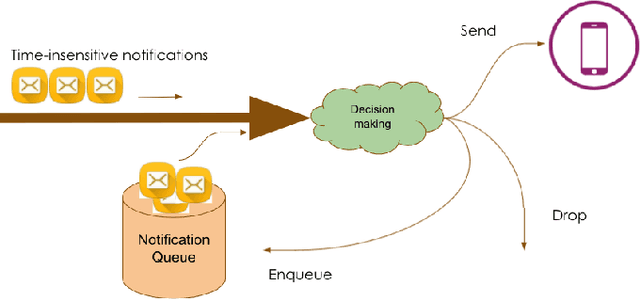
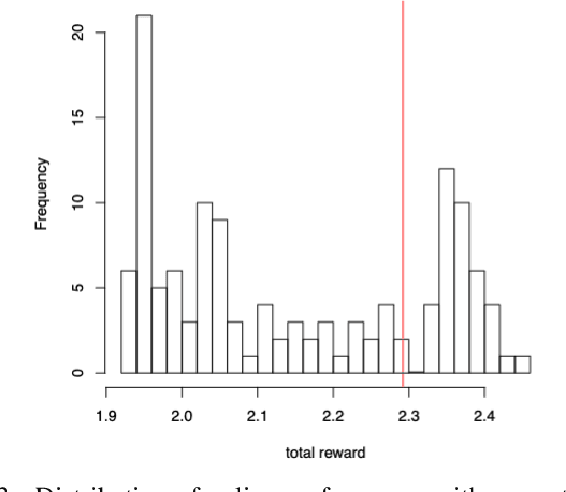
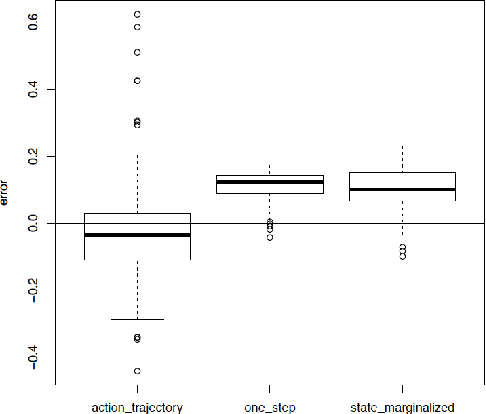
Mobile notification systems have taken a major role in driving and maintaining user engagement for online platforms. They are interesting recommender systems to machine learning practitioners with more sequential and long-term feedback considerations. Most machine learning applications in notification systems are built around response-prediction models, trying to attribute both short-term impact and long-term impact to a notification decision. However, a user's experience depends on a sequence of notifications and attributing impact to a single notification is not always accurate, if not impossible. In this paper, we argue that reinforcement learning is a better framework for notification systems in terms of performance and iteration speed. We propose an offline reinforcement learning framework to optimize sequential notification decisions for driving user engagement. We describe a state-marginalized importance sampling policy evaluation approach, which can be used to evaluate the policy offline and tune learning hyperparameters. Through simulations that approximate the notifications ecosystem, we demonstrate the performance and benefits of the offline evaluation approach as a part of the reinforcement learning modeling approach. Finally, we collect data through online exploration in the production system, train an offline Double Deep Q-Network and launch a successful policy online. We also discuss the practical considerations and results obtained by deploying these policies for a large-scale recommendation system use-case.