 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinkage Initialization for Smooth Learning of Neural Networks
Apr 12, 2025The successes of intelligent systems have quite relied on the artificial learning of information, which lead to the broad applications of neural learning solutions. As a common sense, the training of neural networks can be largely improved by specifically defined initialization, neuron layers as well as the activation functions. Though there are sequential layer based initialization available, the generalized solution to initial stages is still desired. In this work, an improved approach to initialization of neural learning is presented, which adopts the shrinkage approach to initialize the transformation of each layer of networks. It can be universally adapted for the structures of any networks with random layers, while stable performance can be attained. Furthermore, the smooth learning of networks is adopted in this work, due to the diverse influence on neural learning. Experimental results on several artificial data sets demonstrate that, the proposed method is able to present robust results with the shrinkage initialization, and competent for smooth learning of neural networks.
Privacy-Preserving Race/Ethnicity Estimation for Algorithmic Bias Measurement in the U.S
Sep 06, 2024AI fairness measurements, including tests for equal treatment, often take the form of disaggregated evaluations of AI systems. Such measurements are an important part of Responsible AI operations. These measurements compare system performance across demographic groups or sub-populations and typically require member-level demographic signals such as gender, race, ethnicity, and location. However, sensitive member-level demographic attributes like race and ethnicity can be challenging to obtain and use due to platform choices, legal constraints, and cultural norms. In this paper, we focus on the task of enabling AI fairness measurements on race/ethnicity for \emph{U.S. LinkedIn members} in a privacy-preserving manner. We present the Privacy-Preserving Probabilistic Race/Ethnicity Estimation (PPRE) method for performing this task. PPRE combines the Bayesian Improved Surname Geocoding (BISG) model, a sparse LinkedIn survey sample of self-reported demographics, and privacy-enhancing technologies like secure two-party computation and differential privacy to enable meaningful fairness measurements while preserving member privacy. We provide details of the PPRE method and its privacy guarantees. We then illustrate sample measurement operations. We conclude with a review of open research and engineering challenges for expanding our privacy-preserving fairness measurement capabilities.
Leachable Component Clustering
Aug 28, 2022

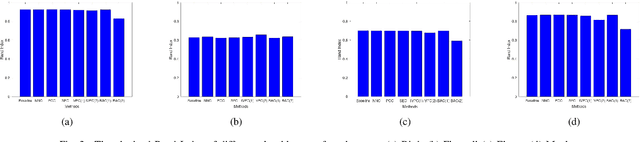
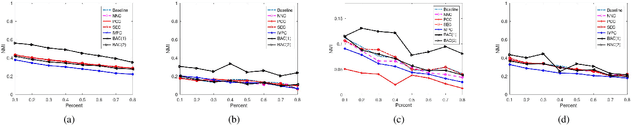
Clustering attempts to partition data instances into several distinctive groups, while the similarities among data belonging to the common partition can be principally reserved. Furthermore, incomplete data frequently occurs in many realworld applications, and brings perverse influence on pattern analysis. As a consequence, the specific solutions to data imputation and handling are developed to conduct the missing values of data, and independent stage of knowledge exploitation is absorbed for information understanding. In this work, a novel approach to clustering of incomplete data, termed leachable component clustering, is proposed. Rather than existing methods, the proposed method handles data imputation with Bayes alignment, and collects the lost patterns in theory. Due to the simple numeric computation of equations, the proposed method can learn optimized partitions while the calculation efficiency is held. Experiments on several artificial incomplete data sets demonstrate that, the proposed method is able to present superior performance compared with other state-of-the-art algorithms.
Multi-similarity based Hyperrelation Network for few-shot segmentation
Mar 23, 2022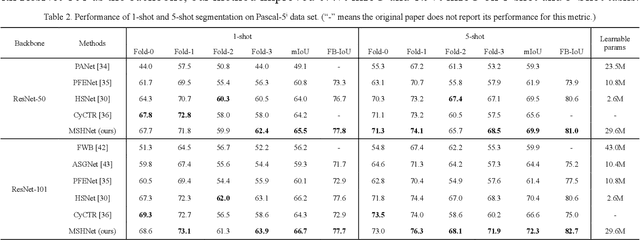
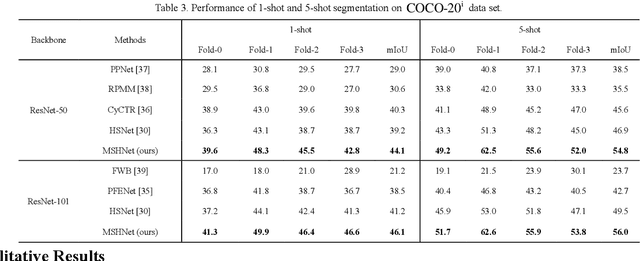

Few-shot semantic segmentation aims at recognizing the object regions of unseen categories with only a few annotated examples as supervision. The key to few-shot segmentation is to establish a robust semantic relationship between the support and query images and to prevent overfitting. In this paper, we propose an effective Multi-similarity Hyperrelation Network (MSHNet) to tackle the few-shot semantic segmentation problem. In MSHNet, we propose a new Generative Prototype Similarity (GPS), which together with cosine similarity can establish a strong semantic relation between the support and query images. The locally generated prototype similarity based on global feature is logically complementary to the global cosine similarity based on local feature, and the relationship between the query image and the supported image can be expressed more comprehensively by using the two similarities simultaneously. In addition, we propose a Symmetric Merging Block (SMB) in MSHNet to efficiently merge multi-layer, multi-shot and multi-similarity hyperrelational features. MSHNet is built on the basis of similarity rather than specific category features, which can achieve more general unity and effectively reduce overfitting. On two benchmark semantic segmentation datasets Pascal-5i and COCO-20i, MSHNet achieves new state-of-the-art performances on 1-shot and 5-shot semantic segmentation tasks.
Offline Reinforcement Learning for Mobile Notifications
Feb 04, 2022
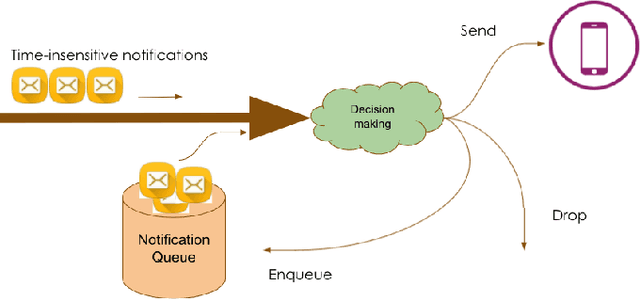
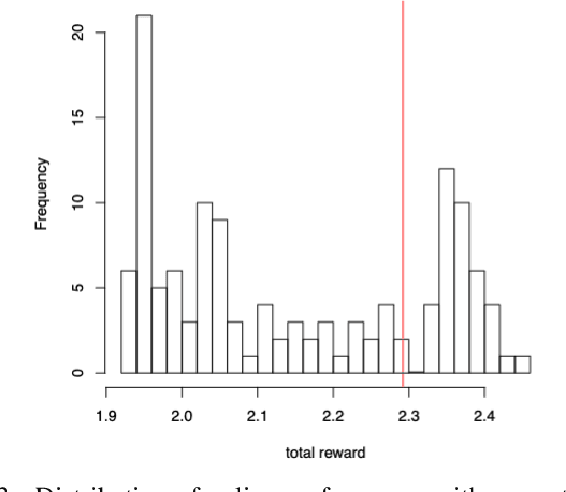
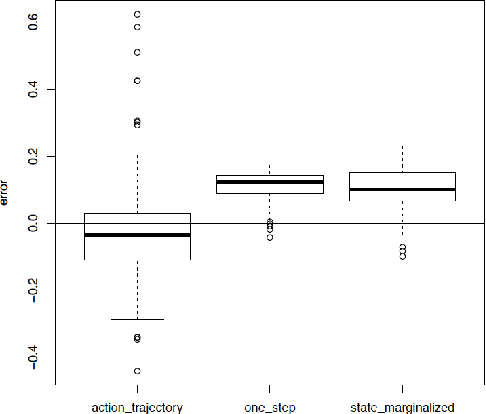
Mobile notification systems have taken a major role in driving and maintaining user engagement for online platforms. They are interesting recommender systems to machine learning practitioners with more sequential and long-term feedback considerations. Most machine learning applications in notification systems are built around response-prediction models, trying to attribute both short-term impact and long-term impact to a notification decision. However, a user's experience depends on a sequence of notifications and attributing impact to a single notification is not always accurate, if not impossible. In this paper, we argue that reinforcement learning is a better framework for notification systems in terms of performance and iteration speed. We propose an offline reinforcement learning framework to optimize sequential notification decisions for driving user engagement. We describe a state-marginalized importance sampling policy evaluation approach, which can be used to evaluate the policy offline and tune learning hyperparameters. Through simulations that approximate the notifications ecosystem, we demonstrate the performance and benefits of the offline evaluation approach as a part of the reinforcement learning modeling approach. Finally, we collect data through online exploration in the production system, train an offline Double Deep Q-Network and launch a successful policy online. We also discuss the practical considerations and results obtained by deploying these policies for a large-scale recommendation system use-case.
Adaptive Matching of Kernel Means
Nov 16, 2020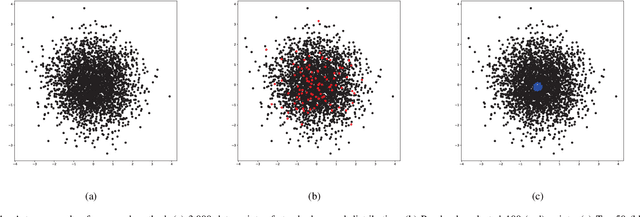
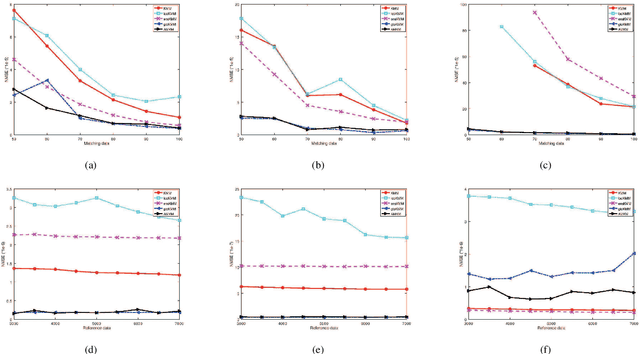


As a promising step, the performance of data analysis and feature learning are able to be improved if certain pattern matching mechanism is available. One of the feasible solutions can refer to the importance estimation of instances, and consequently, kernel mean matching (KMM) has become an important method for knowledge discovery and novelty detection in kernel machines. Furthermore, the existing KMM methods have focused on concrete learning frameworks. In this work, a novel approach to adaptive matching of kernel means is proposed, and selected data with high importance are adopted to achieve calculation efficiency with optimization. In addition, scalable learning can be conducted in proposed method as a generalized solution to matching of appended data. The experimental results on a wide variety of real-world data sets demonstrate the proposed method is able to give outstanding performance compared with several state-of-the-art methods, while calculation efficiency can be preserved.
CRH: A Simple Benchmark Approach to Continuous Hashing
Oct 10, 2018


In recent years, the distinctive advancement of handling huge data promotes the evolution of ubiquitous computing and analysis technologies. With the constantly upward system burden and computational complexity, adaptive coding has been a fascinating topic for pattern analysis, with outstanding performance. In this work, a continuous hashing method, termed continuous random hashing (CRH), is proposed to encode sequential data stream, while ignorance of previously hashing knowledge is possible. Instead, a random selection idea is adopted to adaptively approximate the differential encoding patterns of data stream, e.g., streaming media, and iteration is avoided for stepwise learning. Experimental results demonstrate our method is able to provide outstanding performance, as a benchmark approach to continuous hashing.
A Family of Maximum Margin Criterion for Adaptive Learning
Oct 09, 2018
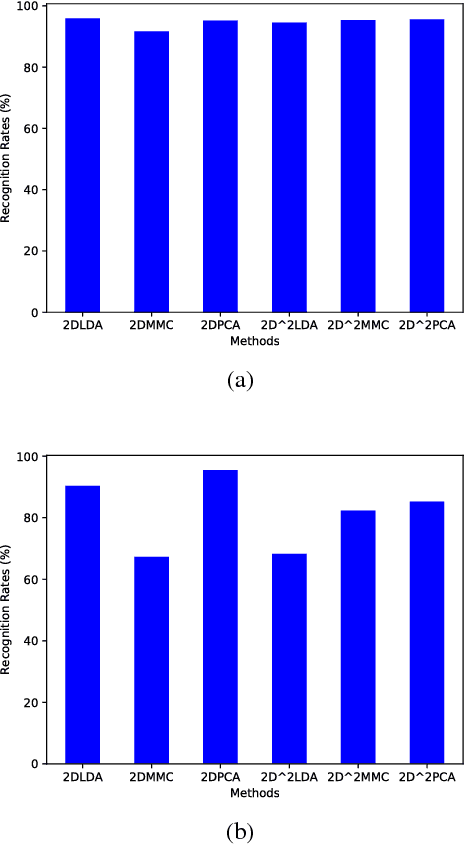
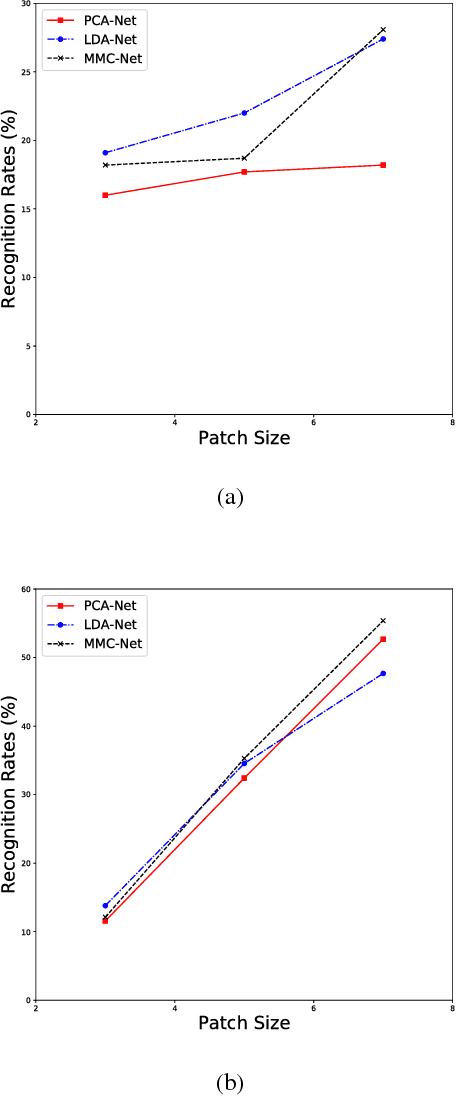
In recent years, pattern analysis plays an important role in data mining and recognition, and many variants have been proposed to handle complicated scenarios. In the literature, it has been quite familiar with high dimensionality of data samples, but either such characteristics or large data have become usual sense in real-world applications. In this work, an improved maximum margin criterion (MMC) method is introduced firstly. With the new definition of MMC, several variants of MMC, including random MMC, layered MMC, 2D^2 MMC, are designed to make adaptive learning applicable. Particularly, the MMC network is developed to learn deep features of images in light of simple deep networks. Experimental results on a diversity of data sets demonstrate the discriminant ability of proposed MMC methods are compenent to be adopted in complicated application scenarios.
Adaptive Training of Random Mapping for Data Quantization
May 26, 2017

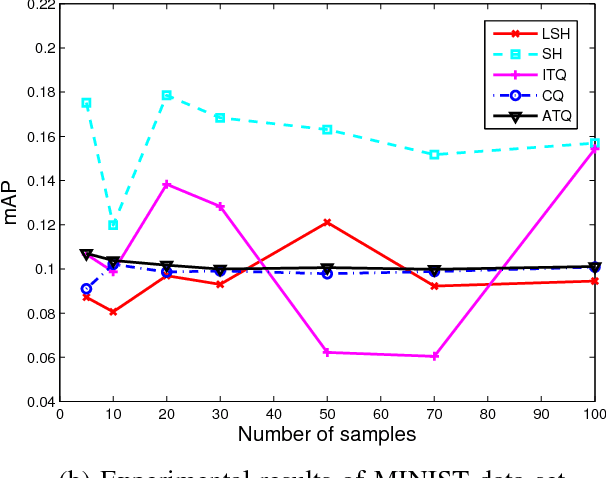
Data quantization learns encoding results of data with certain requirements, and provides a broad perspective of many real-world applications to data handling. Nevertheless, the results of encoder is usually limited to multivariate inputs with the random mapping, and side information of binary codes are hardly to mostly depict the original data patterns as possible. In the literature, cosine based random quantization has attracted much attentions due to its intrinsic bounded results. Nevertheless, it usually suffers from the uncertain outputs, and information of original data fails to be fully preserved in the reduced codes. In this work, a novel binary embedding method, termed adaptive training quantization (ATQ), is proposed to learn the ideal transform of random encoder, where the limitation of cosine random mapping is tackled. As an adaptive learning idea, the reduced mapping is adaptively calculated with idea of data group, while the bias of random transform is to be improved to hold most matching information. Experimental results show that the proposed method is able to obtain outstanding performance compared with other random quantization methods.
Fractal Dimension Pattern Based Multiresolution Analysis for Rough Estimator of Person-Dependent Audio Emotion Recognition
Dec 02, 2016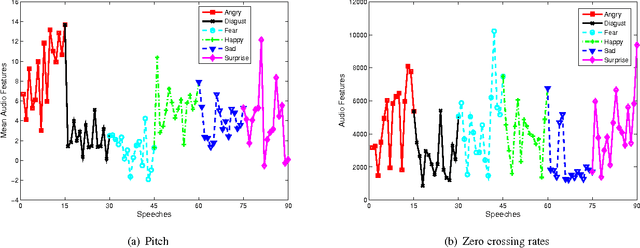
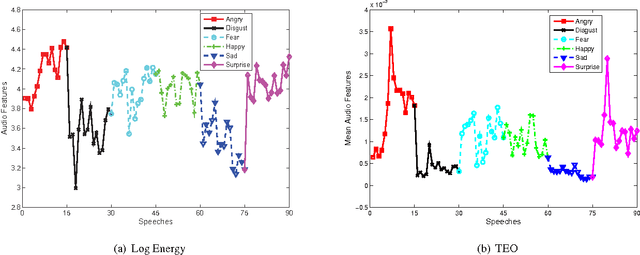
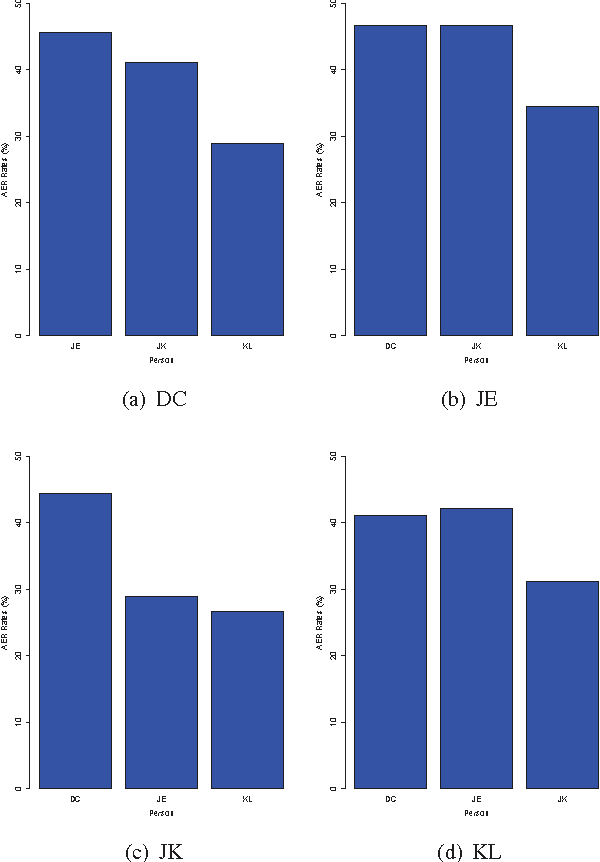
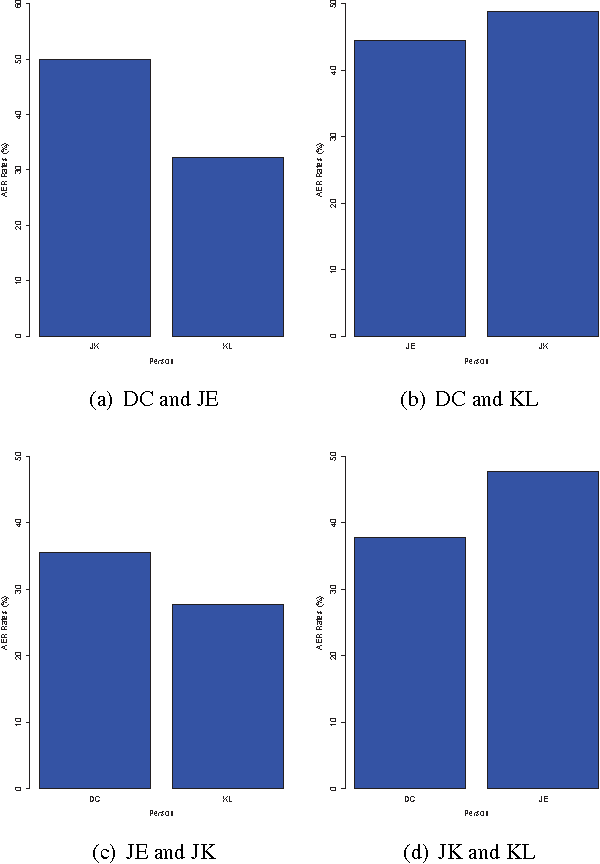
As a general means of expression, audio analysis and recognition has attracted much attentions for its wide applications in real-life world. Audio emotion recognition (AER) attempts to understand emotional states of human with the given utterance signals, and has been studied abroad for its further development on friendly human-machine interfaces. Distinguish from other existing works, the person-dependent patterns of audio emotions are conducted, and fractal dimension features are calculated for acoustic feature extraction. Furthermore, it is able to efficiently learn intrinsic characteristics of auditory emotions, while the utterance features are learned from fractal dimensions of each sub-bands. Experimental results show the proposed method is able to provide comparative performance for audio emotion recognition.