 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractal Dimension Pattern Based Multiresolution Analysis for Rough Estimator of Person-Dependent Audio Emotion Recognition
Paper and Code
Dec 02, 2016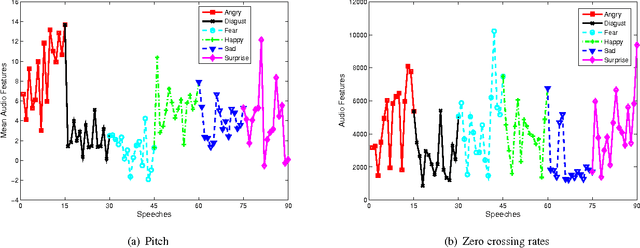
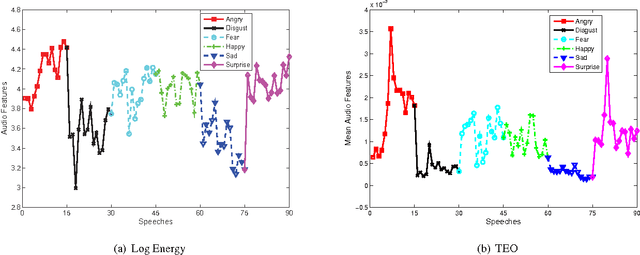
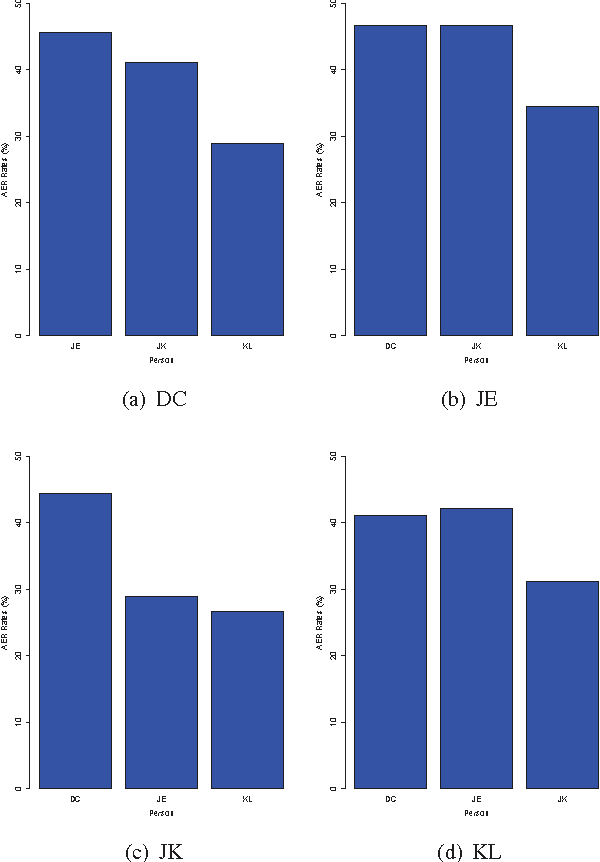
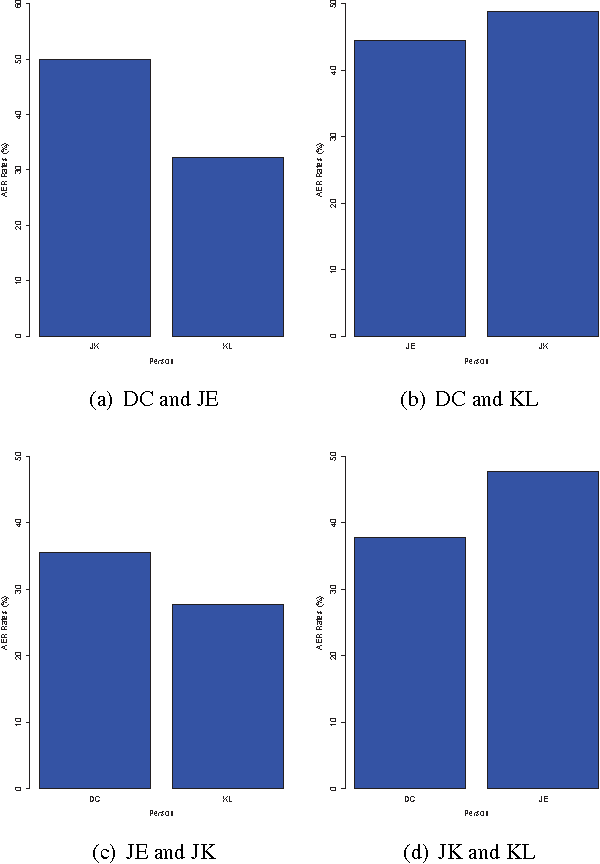
As a general means of expression, audio analysis and recognition has attracted much attentions for its wide applications in real-life world. Audio emotion recognition (AER) attempts to understand emotional states of human with the given utterance signals, and has been studied abroad for its further development on friendly human-machine interfaces. Distinguish from other existing works, the person-dependent patterns of audio emotions are conducted, and fractal dimension features are calculated for acoustic feature extraction. Furthermore, it is able to efficiently learn intrinsic characteristics of auditory emotions, while the utterance features are learned from fractal dimensions of each sub-bands. Experimental results show the proposed method is able to provide comparative performance for audio emotion recognition.