 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign Language Translation with Hierarchical Spatio-TemporalGraph Neural Network
Nov 14, 2021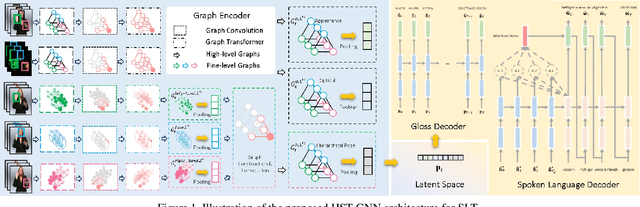
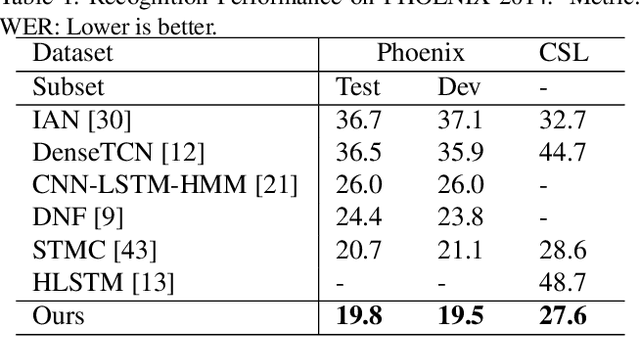
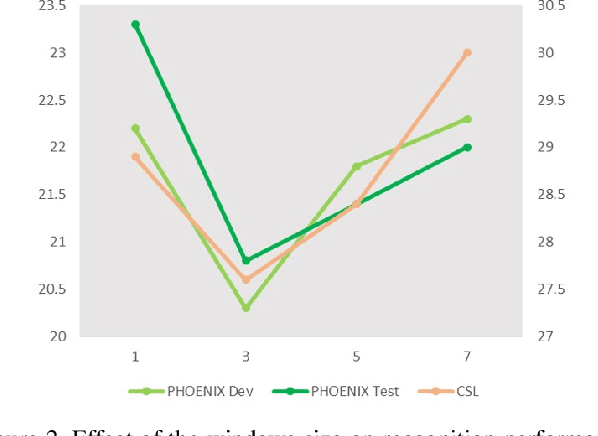
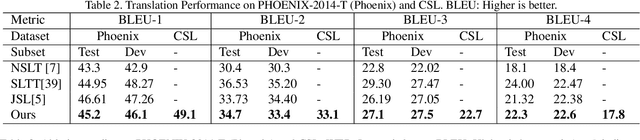
Sign language translation (SLT), which generates text in a spoken language from visual content in a sign language, is important to assist the hard-of-hearing community for their communications. Inspired by neural machine translation (NMT), most existing SLT studies adopted a general sequence to sequence learning strategy. However, SLT is significantly different from general NMT tasks since sign languages convey messages through multiple visual-manual aspects. Therefore, in this paper, these unique characteristics of sign languages are formulated as hierarchical spatio-temporal graph representations, including high-level and fine-level graphs of which a vertex characterizes a specified body part and an edge represents their interactions. Particularly, high-level graphs represent the patterns in the regions such as hands and face, and fine-level graphs consider the joints of hands and landmarks of facial regions. To learn these graph patterns, a novel deep learning architecture, namely hierarchical spatio-temporal graph neural network (HST-GNN), is proposed. Graph convolutions and graph self-attentions with neighborhood context are proposed to characterize both the local and the global graph properties. Experimental results on benchmark datasets demonstrated the effectiveness of the proposed method.
Embedding of FRPN in CNN architecture
Dec 27, 2019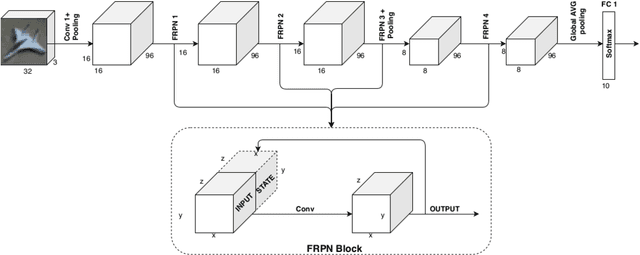
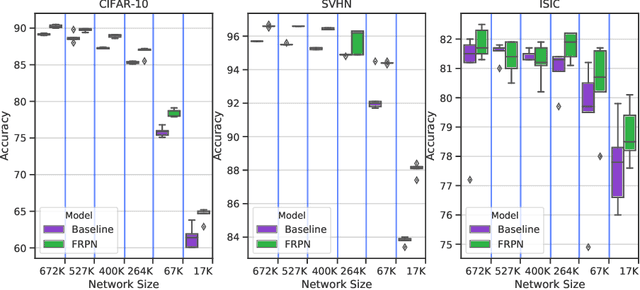
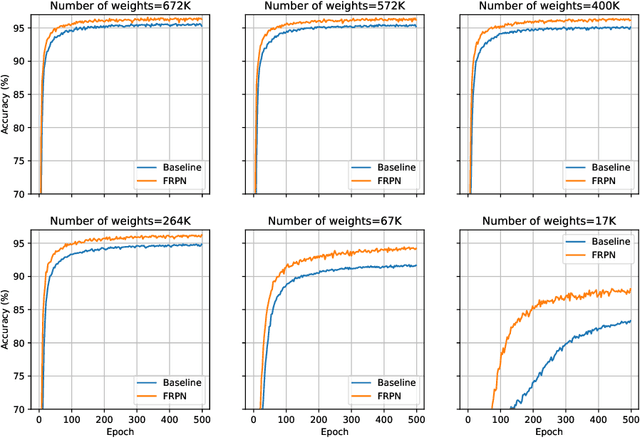
This paper extends the fully recursive perceptron network (FRPN) model for vectorial inputs to include deep convolutional neural networks (CNNs) which can accept multi-dimensional inputs. A FRPN consists of a recursive layer, which, given a fixed input, iteratively computes an equilibrium state. The unfolding realized with this kind of iterative mechanism allows to simulate a deep neural network with any number of layers. The extension of the FRPN to CNN results in an architecture, which we call convolutional-FRPN (C-FRPN), where the convolutional layers are recursive. The method is evaluated on several image classification benchmarks. It is shown that the C-FRPN consistently outperforms standard CNNs having the same number of parameters. The gap in performance is particularly large for small networks, showing that the C-FRPN is a very powerful architecture, since it allows to obtain equivalent performance with fewer parameters when compared with deep CNNs.
CRH: A Simple Benchmark Approach to Continuous Hashing
Oct 10, 2018


In recent years, the distinctive advancement of handling huge data promotes the evolution of ubiquitous computing and analysis technologies. With the constantly upward system burden and computational complexity, adaptive coding has been a fascinating topic for pattern analysis, with outstanding performance. In this work, a continuous hashing method, termed continuous random hashing (CRH), is proposed to encode sequential data stream, while ignorance of previously hashing knowledge is possible. Instead, a random selection idea is adopted to adaptively approximate the differential encoding patterns of data stream, e.g., streaming media, and iteration is avoided for stepwise learning. Experimental results demonstrate our method is able to provide outstanding performance, as a benchmark approach to continuous hashing.
A Family of Maximum Margin Criterion for Adaptive Learning
Oct 09, 2018
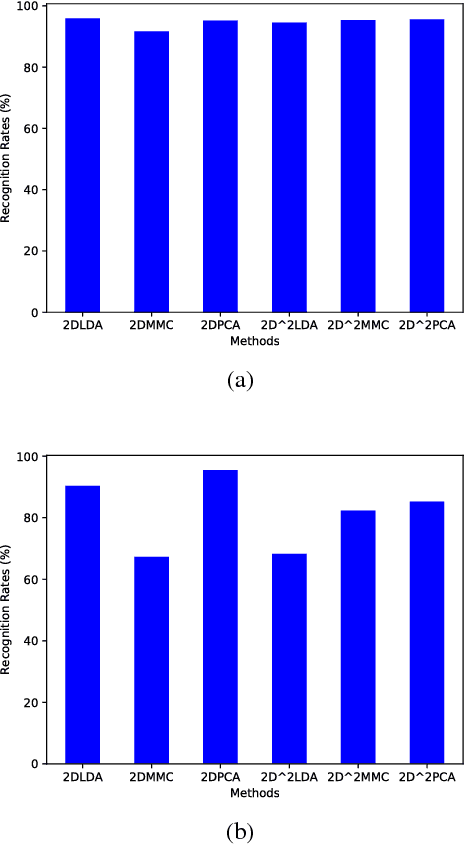
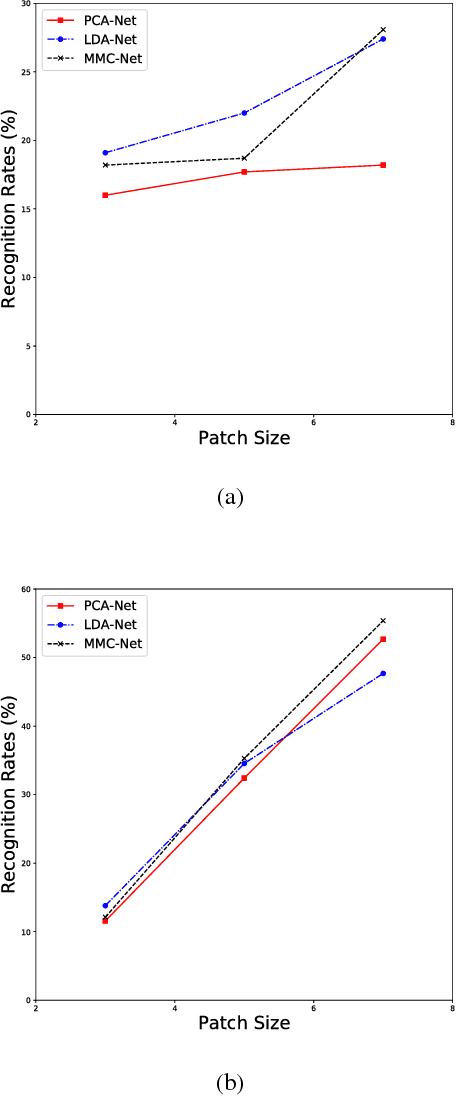
In recent years, pattern analysis plays an important role in data mining and recognition, and many variants have been proposed to handle complicated scenarios. In the literature, it has been quite familiar with high dimensionality of data samples, but either such characteristics or large data have become usual sense in real-world applications. In this work, an improved maximum margin criterion (MMC) method is introduced firstly. With the new definition of MMC, several variants of MMC, including random MMC, layered MMC, 2D^2 MMC, are designed to make adaptive learning applicable. Particularly, the MMC network is developed to learn deep features of images in light of simple deep networks. Experimental results on a diversity of data sets demonstrate the discriminant ability of proposed MMC methods are compenent to be adopted in complicated application scenarios.
Adaptive Training of Random Mapping for Data Quantization
May 26, 2017

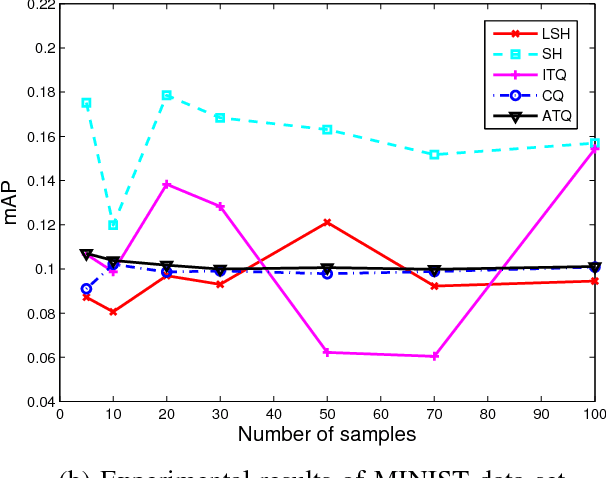
Data quantization learns encoding results of data with certain requirements, and provides a broad perspective of many real-world applications to data handling. Nevertheless, the results of encoder is usually limited to multivariate inputs with the random mapping, and side information of binary codes are hardly to mostly depict the original data patterns as possible. In the literature, cosine based random quantization has attracted much attentions due to its intrinsic bounded results. Nevertheless, it usually suffers from the uncertain outputs, and information of original data fails to be fully preserved in the reduced codes. In this work, a novel binary embedding method, termed adaptive training quantization (ATQ), is proposed to learn the ideal transform of random encoder, where the limitation of cosine random mapping is tackled. As an adaptive learning idea, the reduced mapping is adaptively calculated with idea of data group, while the bias of random transform is to be improved to hold most matching information. Experimental results show that the proposed method is able to obtain outstanding performance compared with other random quantization methods.
Fractal Dimension Pattern Based Multiresolution Analysis for Rough Estimator of Person-Dependent Audio Emotion Recognition
Dec 02, 2016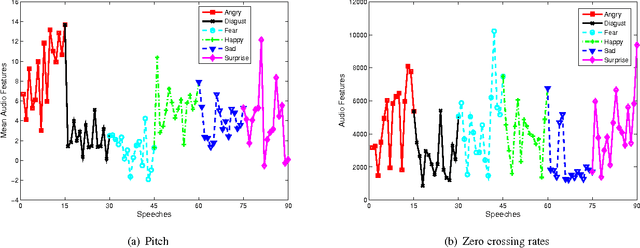
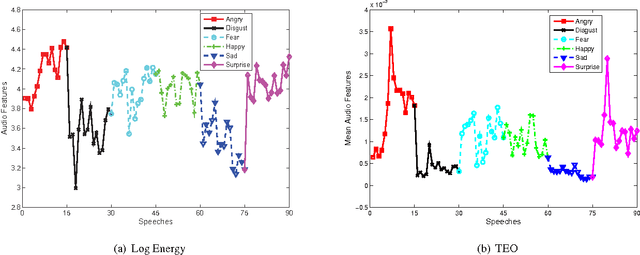
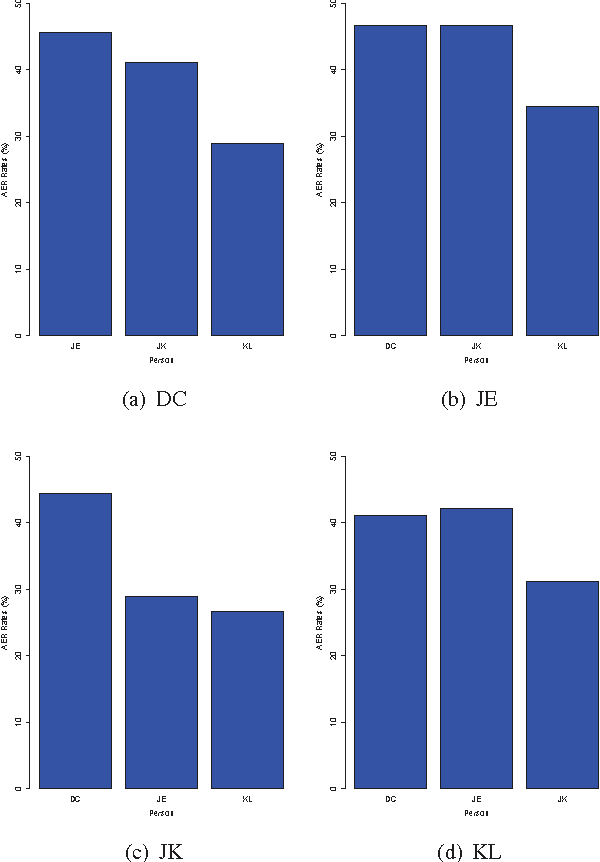
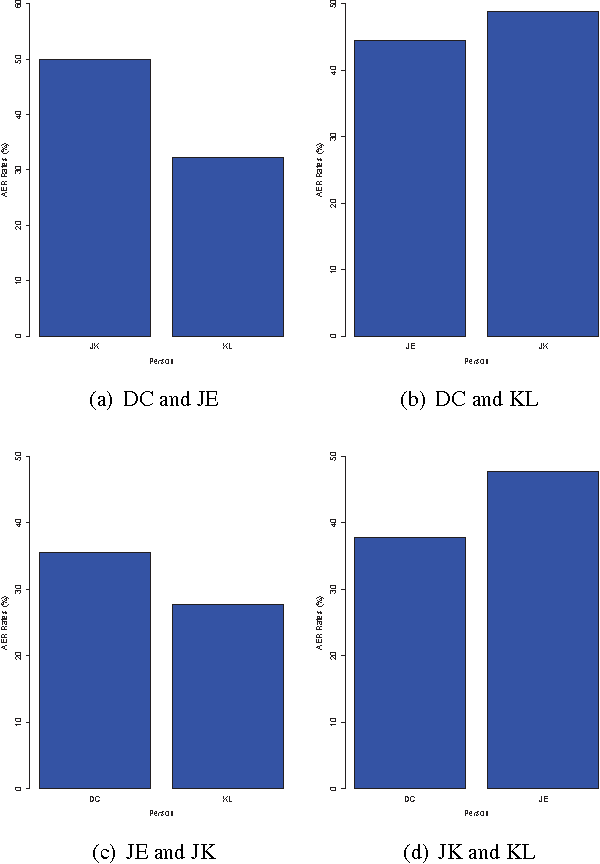
As a general means of expression, audio analysis and recognition has attracted much attentions for its wide applications in real-life world. Audio emotion recognition (AER) attempts to understand emotional states of human with the given utterance signals, and has been studied abroad for its further development on friendly human-machine interfaces. Distinguish from other existing works, the person-dependent patterns of audio emotions are conducted, and fractal dimension features are calculated for acoustic feature extraction. Furthermore, it is able to efficiently learn intrinsic characteristics of auditory emotions, while the utterance features are learned from fractal dimensions of each sub-bands. Experimental results show the proposed method is able to provide comparative performance for audio emotion recognition.