 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign Language Translation with Hierarchical Spatio-TemporalGraph Neural Network
Nov 14, 2021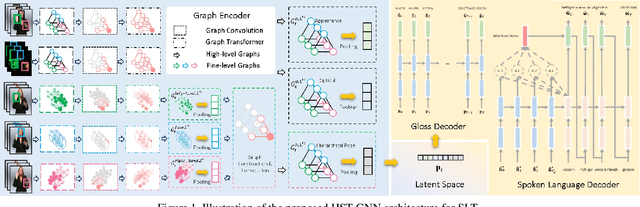
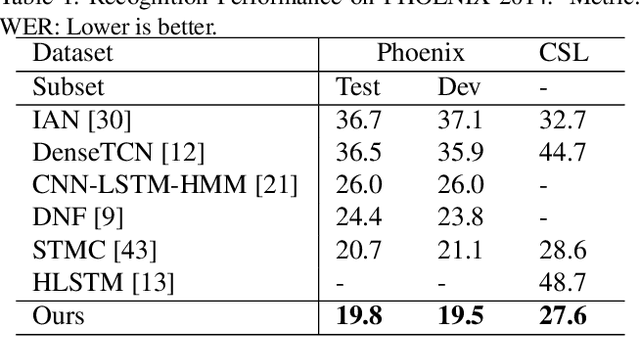
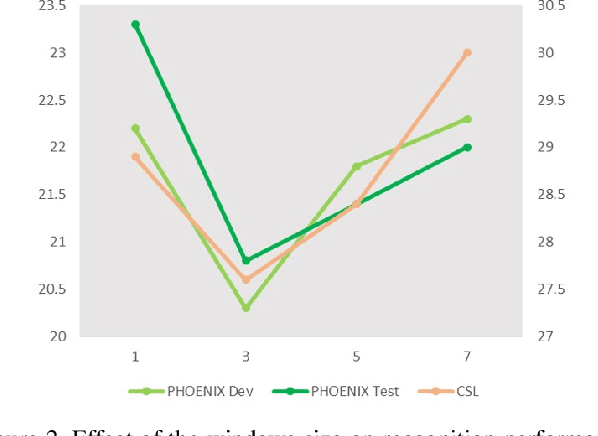
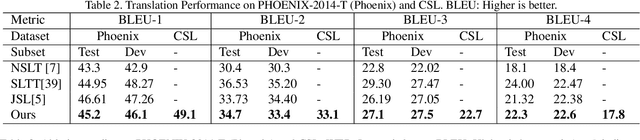
Sign language translation (SLT), which generates text in a spoken language from visual content in a sign language, is important to assist the hard-of-hearing community for their communications. Inspired by neural machine translation (NMT), most existing SLT studies adopted a general sequence to sequence learning strategy. However, SLT is significantly different from general NMT tasks since sign languages convey messages through multiple visual-manual aspects. Therefore, in this paper, these unique characteristics of sign languages are formulated as hierarchical spatio-temporal graph representations, including high-level and fine-level graphs of which a vertex characterizes a specified body part and an edge represents their interactions. Particularly, high-level graphs represent the patterns in the regions such as hands and face, and fine-level graphs consider the joints of hands and landmarks of facial regions. To learn these graph patterns, a novel deep learning architecture, namely hierarchical spatio-temporal graph neural network (HST-GNN), is proposed. Graph convolutions and graph self-attentions with neighborhood context are proposed to characterize both the local and the global graph properties. Experimental results on benchmark datasets demonstrated the effectiveness of the proposed method.
Embedding of FRPN in CNN architecture
Dec 27, 2019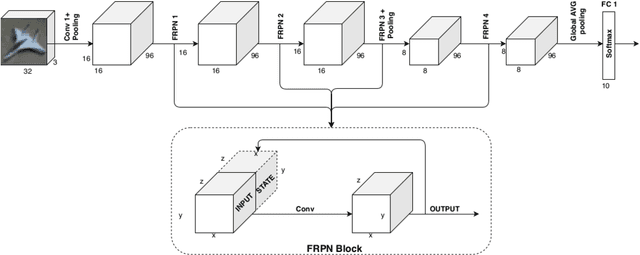
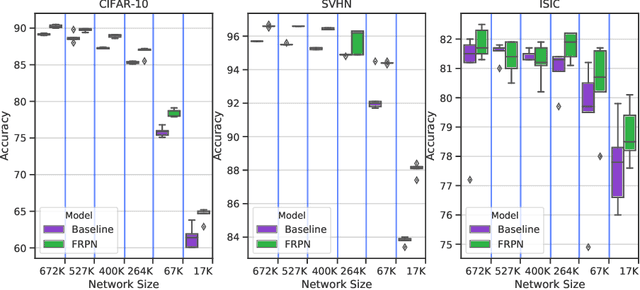
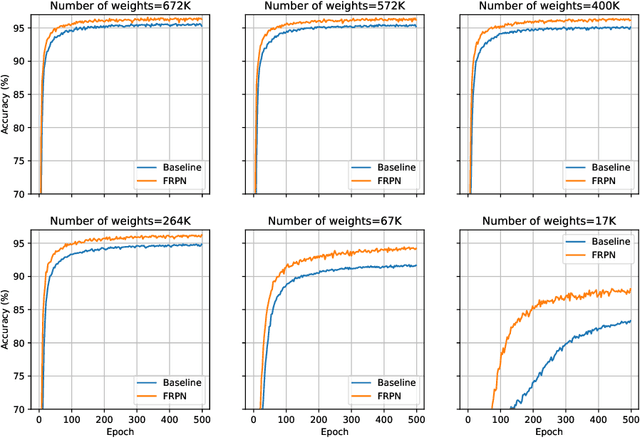
This paper extends the fully recursive perceptron network (FRPN) model for vectorial inputs to include deep convolutional neural networks (CNNs) which can accept multi-dimensional inputs. A FRPN consists of a recursive layer, which, given a fixed input, iteratively computes an equilibrium state. The unfolding realized with this kind of iterative mechanism allows to simulate a deep neural network with any number of layers. The extension of the FRPN to CNN results in an architecture, which we call convolutional-FRPN (C-FRPN), where the convolutional layers are recursive. The method is evaluated on several image classification benchmarks. It is shown that the C-FRPN consistently outperforms standard CNNs having the same number of parameters. The gap in performance is particularly large for small networks, showing that the C-FRPN is a very powerful architecture, since it allows to obtain equivalent performance with fewer parameters when compared with deep CNNs.