 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERAG: Bayesian Ensemble Retrieval-Augmented Generation for Knowledge-based Visual Question Answering
Apr 24, 2026A common approach to question answering with retrieval-augmented generation (RAG) is to concatenate documents into a single context and pass it to a language model to generate an answer. While simple, this strategy can obscure the contribution of individual documents, making attribution difficult and contributing to the ``lost-in-the-middle'' effect, where relevant information in long contexts is overlooked. Concatenation also scales poorly: computational cost grows quadratically with context length, a problem that becomes especially severe when the context includes visual data, as in visual question answering. Attempts to mitigate these issues by limiting context length can further restrict performance by preventing models from benefiting from the improved recall offered by deeper retrieval. We propose Bayesian Ensemble Retrieval-Augmented Generation (BERAG), along with Bayesian Ensemble Fine-Tuning (BEFT), as a RAG framework in which language models are conditioned on individual retrieved documents rather than a single combined context. BERAG treats document posterior probabilities as ensemble weights and updates them token by token using Bayes' rule during generation. This approach enables probabilistic re-ranking, parallel memory usage, and clear attribution of document contribution, making it well-suited for large document collections. We evaluate BERAG and BEFT primarily on knowledge-based visual question answering tasks, where models must reason over long, imperfect retrieval lists. The results show substantial improvements over standard RAG, including strong gains on Document Visual Question Answering and multimodal needle-in-a-haystack benchmarks. We also demonstrate that BERAG mitigates the ``lost-in-the-middle'' effect. The document posterior can be used to detect insufficient grounding and trigger deflection, while document pruning enables faster decoding than standard RAG.
According to Me: Long-Term Personalized Referential Memory QA
Mar 02, 2026Personalized AI assistants must recall and reason over long-term user memory, which naturally spans multiple modalities and sources such as images, videos, and emails. However, existing Long-term Memory benchmarks focus primarily on dialogue history, failing to capture realistic personalized references grounded in lived experience. We introduce ATM-Bench, the first benchmark for multimodal, multi-source personalized referential Memory QA. ATM-Bench contains approximately four years of privacy-preserving personal memory data and human-annotated question-answer pairs with ground-truth memory evidence, including queries that require resolving personal references, multi-evidence reasoning from multi-source and handling conflicting evidence. We propose Schema-Guided Memory (SGM) to structurally represent memory items originated from different sources. In experiments, we implement 5 state-of-the-art memory systems along with a standard RAG baseline and evaluate variants with different memory ingestion, retrieval, and answer generation techniques. We find poor performance (under 20\% accuracy) on the ATM-Bench-Hard set, and that SGM improves performance over Descriptive Memory commonly adopted in prior works. Code available at: https://github.com/JingbiaoMei/ATM-Bench
CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
Jan 05, 2026Current work on robot failure detection and correction typically operate in a post hoc manner, analyzing errors and applying corrections only after failures occur. This work introduces CycleVLA, a system that equips Vision-Language-Action models (VLAs) with proactive self-correction, the capability to anticipate incipient failures and recover before they fully manifest during execution. CycleVLA achieves this by integrating a progress-aware VLA that flags critical subtask transition points where failures most frequently occur, a VLM-based failure predictor and planner that triggers subtask backtracking upon predicted failure, and a test-time scaling strategy based on Minimum Bayes Risk (MBR) decoding to improve retry success after backtracking. Extensive experiments show that CycleVLA improves performance for both well-trained and under-trained VLAs, and that MBR serves as an effective zero-shot test-time scaling strategy for VLAs. Project Page: https://dannymcy.github.io/cyclevla/
Improved Fine-Tuning of Large Multimodal Models for Hateful Meme Detection
Feb 18, 2025Hateful memes have become a significant concern on the Internet, necessitating robust automated detection systems. While large multimodal models have shown strong generalization across various tasks, they exhibit poor generalization to hateful meme detection due to the dynamic nature of memes tied to emerging social trends and breaking news. Recent work further highlights the limitations of conventional supervised fine-tuning for large multimodal models in this context. To address these challenges, we propose Large Multimodal Model Retrieval-Guided Contrastive Learning (LMM-RGCL), a novel two-stage fine-tuning framework designed to improve both in-domain accuracy and cross-domain generalization. Experimental results on six widely used meme classification datasets demonstrate that LMM-RGCL achieves state-of-the-art performance, outperforming agent-based systems such as VPD-PALI-X-55B. Furthermore, our method effectively generalizes to out-of-domain memes under low-resource settings, surpassing models like GPT-4o.
On Extending Direct Preference Optimization to Accommodate Ties
Sep 25, 2024



We derive and investigate two DPO variants that explicitly model the possibility of declaring a tie in pair-wise comparisons. We replace the Bradley-Terry model in DPO with two well-known modeling extensions, by Rao and Kupper and by Davidson, that assign probability to ties as alternatives to clear preferences. Our experiments in neural machine translation and summarization show that explicitly labeled ties can be added to the datasets for these DPO variants without the degradation in task performance that is observed when the same tied pairs are presented to DPO. We find empirically that the inclusion of ties leads to stronger regularization with respect to the reference policy as measured by KL divergence, and we see this even for DPO in its original form. These findings motivate and enable the inclusion of tied pairs in preference optimization as opposed to simply discarding them.
Survey for Landing Generative AI in Social and E-commerce Recsys -- the Industry Perspectives
Jun 10, 2024



Recently, generative AI (GAI), with their emerging capabilities, have presented unique opportunities for augmenting and revolutionizing industrial recommender systems (Recsys). Despite growing research efforts at the intersection of these fields, the integration of GAI into industrial Recsys remains in its infancy, largely due to the intricate nature of modern industrial Recsys infrastructure, operations, and product sophistication. Drawing upon our experiences in successfully integrating GAI into several major social and e-commerce platforms, this survey aims to comprehensively examine the underlying system and AI foundations, solution frameworks, connections to key research advancements, as well as summarize the practical insights and challenges encountered in the endeavor to integrate GAI into industrial Recsys. As pioneering work in this domain, we hope outline the representative developments of relevant fields, shed lights on practical GAI adoptions in the industry, and motivate future research.
Direct Preference Optimization for Neural Machine Translation with Minimum Bayes Risk Decoding
Nov 14, 2023



Minimum Bayes Risk (MBR) decoding can significantly improve translation performance of Multilingual Large Language Models (MLLMs). However, MBR decoding is computationally expensive and in this paper, we show how recently developed Reinforcement Learning (RL) technique, Direct Preference Optimization (DPO) can be used to fine-tune MLLMs so that we get the gains from MBR without the additional computation in inference. Our fine-tuned models have significantly improved performance on multiple NMT test sets compared to base MLLMs without preference optimization. Our method boosts the translation performance of MLLMs using relatively small monolingual fine-tuning sets.
Multi-objective Optimization of Notifications Using Offline Reinforcement Learning
Jul 07, 2022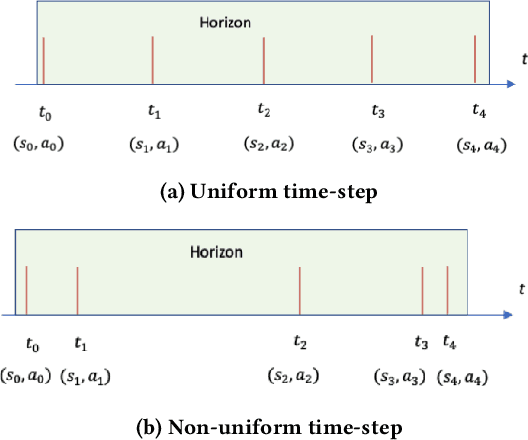

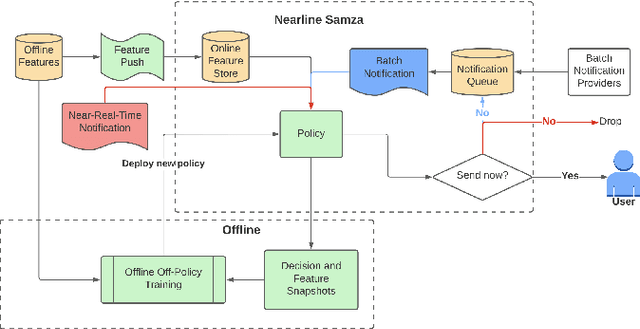
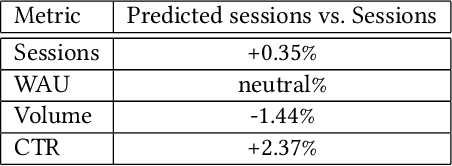
Mobile notification systems play a major role in a variety of applications to communicate, send alerts and reminders to the users to inform them about news, events or messages. In this paper, we formulate the near-real-time notification decision problem as a Markov Decision Process where we optimize for multiple objectives in the rewards. We propose an end-to-end offline reinforcement learning framework to optimize sequential notification decisions. We address the challenge of offline learning using a Double Deep Q-network method based on Conservative Q-learning that mitigates the distributional shift problem and Q-value overestimation. We illustrate our fully-deployed system and demonstrate the performance and benefits of the proposed approach through both offline and online experiments.