 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERAG: Bayesian Ensemble Retrieval-Augmented Generation for Knowledge-based Visual Question Answering
Apr 24, 2026A common approach to question answering with retrieval-augmented generation (RAG) is to concatenate documents into a single context and pass it to a language model to generate an answer. While simple, this strategy can obscure the contribution of individual documents, making attribution difficult and contributing to the ``lost-in-the-middle'' effect, where relevant information in long contexts is overlooked. Concatenation also scales poorly: computational cost grows quadratically with context length, a problem that becomes especially severe when the context includes visual data, as in visual question answering. Attempts to mitigate these issues by limiting context length can further restrict performance by preventing models from benefiting from the improved recall offered by deeper retrieval. We propose Bayesian Ensemble Retrieval-Augmented Generation (BERAG), along with Bayesian Ensemble Fine-Tuning (BEFT), as a RAG framework in which language models are conditioned on individual retrieved documents rather than a single combined context. BERAG treats document posterior probabilities as ensemble weights and updates them token by token using Bayes' rule during generation. This approach enables probabilistic re-ranking, parallel memory usage, and clear attribution of document contribution, making it well-suited for large document collections. We evaluate BERAG and BEFT primarily on knowledge-based visual question answering tasks, where models must reason over long, imperfect retrieval lists. The results show substantial improvements over standard RAG, including strong gains on Document Visual Question Answering and multimodal needle-in-a-haystack benchmarks. We also demonstrate that BERAG mitigates the ``lost-in-the-middle'' effect. The document posterior can be used to detect insufficient grounding and trigger deflection, while document pruning enables faster decoding than standard RAG.
CyclicJudge: Mitigating Judge Bias Efficiently in LLM-based Evaluation
Mar 02, 2026LLM-as-judge evaluation has become standard practice for open-ended model assessment; however, judges exhibit systematic biases that cannot be eliminated by increasing the number of scenarios or generations. These biases are often similar in magnitude to the model differences that benchmarks are designed to detect, resulting in unreliable rankings when single-judge evaluations are used. This work introduces a variance decomposition that partitions benchmark score variance into scenario, generation, judge, and residual components. Based on this analysis, CyclicJudge, a round-robin assignment of judges, is demonstrated to be the optimal allocation strategy. It eliminates bias precisely while requiring each judge only once per cycle, maintaining the cost of single-judge evaluation. Empirical validation on MT-Bench supports all theoretical predictions.
According to Me: Long-Term Personalized Referential Memory QA
Mar 02, 2026Personalized AI assistants must recall and reason over long-term user memory, which naturally spans multiple modalities and sources such as images, videos, and emails. However, existing Long-term Memory benchmarks focus primarily on dialogue history, failing to capture realistic personalized references grounded in lived experience. We introduce ATM-Bench, the first benchmark for multimodal, multi-source personalized referential Memory QA. ATM-Bench contains approximately four years of privacy-preserving personal memory data and human-annotated question-answer pairs with ground-truth memory evidence, including queries that require resolving personal references, multi-evidence reasoning from multi-source and handling conflicting evidence. We propose Schema-Guided Memory (SGM) to structurally represent memory items originated from different sources. In experiments, we implement 5 state-of-the-art memory systems along with a standard RAG baseline and evaluate variants with different memory ingestion, retrieval, and answer generation techniques. We find poor performance (under 20\% accuracy) on the ATM-Bench-Hard set, and that SGM improves performance over Descriptive Memory commonly adopted in prior works. Code available at: https://github.com/JingbiaoMei/ATM-Bench
Improved Fine-Tuning of Large Multimodal Models for Hateful Meme Detection
Feb 18, 2025Hateful memes have become a significant concern on the Internet, necessitating robust automated detection systems. While large multimodal models have shown strong generalization across various tasks, they exhibit poor generalization to hateful meme detection due to the dynamic nature of memes tied to emerging social trends and breaking news. Recent work further highlights the limitations of conventional supervised fine-tuning for large multimodal models in this context. To address these challenges, we propose Large Multimodal Model Retrieval-Guided Contrastive Learning (LMM-RGCL), a novel two-stage fine-tuning framework designed to improve both in-domain accuracy and cross-domain generalization. Experimental results on six widely used meme classification datasets demonstrate that LMM-RGCL achieves state-of-the-art performance, outperforming agent-based systems such as VPD-PALI-X-55B. Furthermore, our method effectively generalizes to out-of-domain memes under low-resource settings, surpassing models like GPT-4o.
On Extending Direct Preference Optimization to Accommodate Ties
Sep 25, 2024



We derive and investigate two DPO variants that explicitly model the possibility of declaring a tie in pair-wise comparisons. We replace the Bradley-Terry model in DPO with two well-known modeling extensions, by Rao and Kupper and by Davidson, that assign probability to ties as alternatives to clear preferences. Our experiments in neural machine translation and summarization show that explicitly labeled ties can be added to the datasets for these DPO variants without the degradation in task performance that is observed when the same tied pairs are presented to DPO. We find empirically that the inclusion of ties leads to stronger regularization with respect to the reference policy as measured by KL divergence, and we see this even for DPO in its original form. These findings motivate and enable the inclusion of tied pairs in preference optimization as opposed to simply discarding them.
Control-DAG: Constrained Decoding for Non-Autoregressive Directed Acyclic T5 using Weighted Finite State Automata
Apr 10, 2024


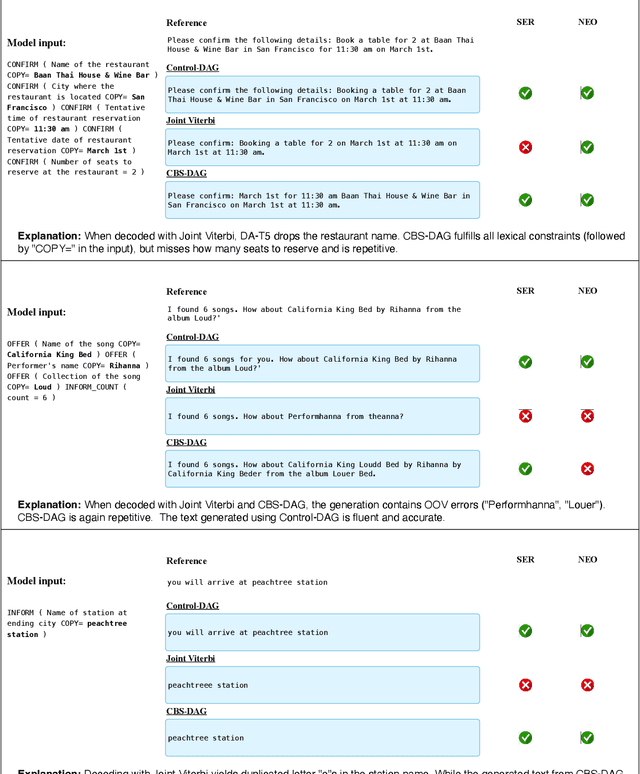
The Directed Acyclic Transformer is a fast non-autoregressive (NAR) model that performs well in Neural Machine Translation. Two issues prevent its application to general Natural Language Generation (NLG) tasks: frequent Out-Of-Vocabulary (OOV) errors and the inability to faithfully generate entity names. We introduce Control-DAG, a constrained decoding algorithm for our Directed Acyclic T5 (DA-T5) model which offers lexical, vocabulary and length control. We show that Control-DAG significantly enhances DA-T5 on the Schema Guided Dialogue and the DART datasets, establishing strong NAR results for Task-Oriented Dialogue and Data-to-Text NLG.
Few-Shot VQA with Frozen LLMs: A Tale of Two Approaches
Mar 17, 2024Two approaches have emerged to input images into large language models (LLMs). The first is to caption images into natural language. The second is to map image feature embeddings into the domain of the LLM and pass the mapped embeddings directly to the LLM. The majority of recent few-shot multimodal work reports performance using architectures that employ variations of one of these two approaches. But they overlook an important comparison between them. We design a controlled and focused experiment to compare these two approaches to few-shot visual question answering (VQA) with LLMs. Our findings indicate that for Flan-T5 XL, a 3B parameter LLM, connecting visual embeddings directly to the LLM embedding space does not guarantee improved performance over using image captions. In the zero-shot regime, we find using textual image captions is better. In the few-shot regimes, how the in-context examples are selected determines which is better.
PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers
Feb 13, 2024



Large Multimodal Models (LMMs) excel in natural language and visual understanding but are challenged by exacting tasks such as Knowledge-based Visual Question Answering (KB-VQA) which involve the retrieval of relevant information from document collections to use in shaping answers to questions. We present an extensive training and evaluation framework, M2KR, for KB-VQA. M2KR contains a collection of vision and language tasks which we have incorporated into a single suite of benchmark tasks for training and evaluating general-purpose multi-modal retrievers. We use M2KR to develop PreFLMR, a pre-trained version of the recently developed Fine-grained Late-interaction Multi-modal Retriever (FLMR) approach to KB-VQA, and we report new state-of-the-art results across a range of tasks. We also present investigations into the scaling behaviors of PreFLMR intended to be useful in future developments in general-purpose multi-modal retrievers.
Improving hateful memes detection via learning hatefulness-aware embedding space through retrieval-guided contrastive learning
Nov 14, 2023



Hateful memes have emerged as a significant concern on the Internet. These memes, which are a combination of image and text, often convey messages vastly different from their individual meanings. Thus, detecting hateful memes requires the system to jointly understand the visual and textual modalities. However, our investigation reveals that the embedding space of existing CLIP-based systems lacks sensitivity to subtle differences in memes that are vital for correct hatefulness classification. To address this issue, we propose constructing a hatefulness-aware embedding space through retrieval-guided contrastive training. Specifically, we add an auxiliary loss that utilizes hard negative and pseudo-gold samples to train the embedding space. Our approach achieves state-of-the-art performance on the HatefulMemes dataset with an AUROC of 86.7. Notably, our approach outperforms much larger fine-tuned Large Multimodal Models like Flamingo and LLaVA. Finally, we demonstrate a retrieval-based hateful memes detection system, which is capable of making hatefulness classification based on data unseen in training from a database. This allows developers to update the hateful memes detection system by simply adding new data without retraining, a desirable feature for real services in the constantly-evolving landscape of hateful memes on the Internet.
Direct Preference Optimization for Neural Machine Translation with Minimum Bayes Risk Decoding
Nov 14, 2023



Minimum Bayes Risk (MBR) decoding can significantly improve translation performance of Multilingual Large Language Models (MLLMs). However, MBR decoding is computationally expensive and in this paper, we show how recently developed Reinforcement Learning (RL) technique, Direct Preference Optimization (DPO) can be used to fine-tune MLLMs so that we get the gains from MBR without the additional computation in inference. Our fine-tuned models have significantly improved performance on multiple NMT test sets compared to base MLLMs without preference optimization. Our method boosts the translation performance of MLLMs using relatively small monolingual fine-tuning sets.