 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering
Paper and Code
Sep 29, 2023

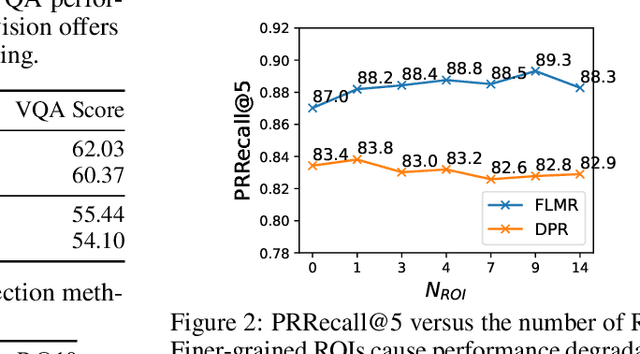
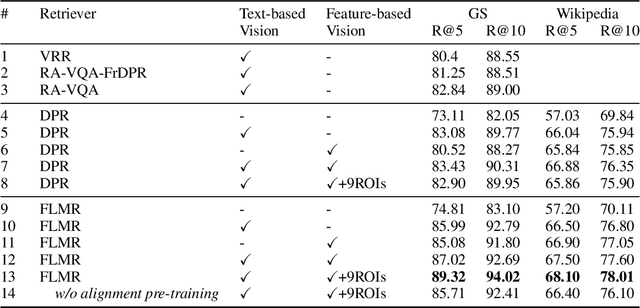
Knowledge-based Visual Question Answering (KB-VQA) requires VQA systems to utilize knowledge from existing knowledge bases to answer visually-grounded questions. Retrieval-Augmented Visual Question Answering (RA-VQA), a strong framework to tackle KB-VQA, first retrieves related documents with Dense Passage Retrieval (DPR) and then uses them to answer questions. This paper proposes Fine-grained Late-interaction Multi-modal Retrieval (FLMR) which significantly improves knowledge retrieval in RA-VQA. FLMR addresses two major limitations in RA-VQA's retriever: (1) the image representations obtained via image-to-text transforms can be incomplete and inaccurate and (2) relevance scores between queries and documents are computed with one-dimensional embeddings, which can be insensitive to finer-grained relevance. FLMR overcomes these limitations by obtaining image representations that complement those from the image-to-text transforms using a vision model aligned with an existing text-based retriever through a simple alignment network. FLMR also encodes images and questions using multi-dimensional embeddings to capture finer-grained relevance between queries and documents. FLMR significantly improves the original RA-VQA retriever's PRRecall@5 by approximately 8\%. Finally, we equipped RA-VQA with two state-of-the-art large multi-modal/language models to achieve $\sim61\%$ VQA score in the OK-VQA dataset.