 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Mar 01, 2024Virtual assistants are poised to take a dramatic leap forward in terms of their dialogue capabilities, spurred by recent advances in transformer-based Large Language Models (LLMs). Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality and linguistically sophisticated data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 multi-domain, multi-intent conversations across 100 intents to demonstrate its capabilities. The generated conversations include a wide range of challenging phenomena and diverse user behaviour, conveniently identifiable via a set of turn-level tags. Finally, we provide separate test sets for seen and unseen intents, allowing for convenient out-of-distribution evaluation. We release both the data generation code and the dataset itself.
Effective and Efficient Conversation Retrieval for Dialogue State Tracking with Implicit Text Summaries
Feb 21, 2024Few-shot dialogue state tracking (DST) with Large Language Models (LLM) relies on an effective and efficient conversation retriever to find similar in-context examples for prompt learning. Previous works use raw dialogue context as search keys and queries, and a retriever is fine-tuned with annotated dialogues to achieve superior performance. However, the approach is less suited for scaling to new domains or new annotation languages, where fine-tuning data is unavailable. To address this problem, we handle the task of conversation retrieval based on text summaries of the conversations. A LLM-based conversation summarizer is adopted for query and key generation, which enables effective maximum inner product search. To avoid the extra inference cost brought by LLM-based conversation summarization, we further distill a light-weight conversation encoder which produces query embeddings without decoding summaries for test conversations. We validate our retrieval approach on MultiWOZ datasets with GPT-Neo-2.7B and LLaMA-7B/30B. The experimental results show a significant improvement over relevant baselines in real few-shot DST settings.
Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering
Sep 29, 2023

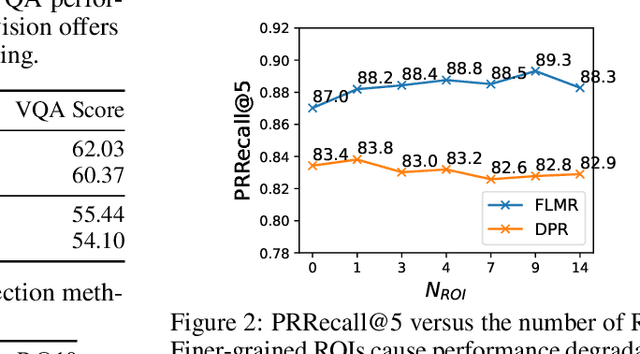
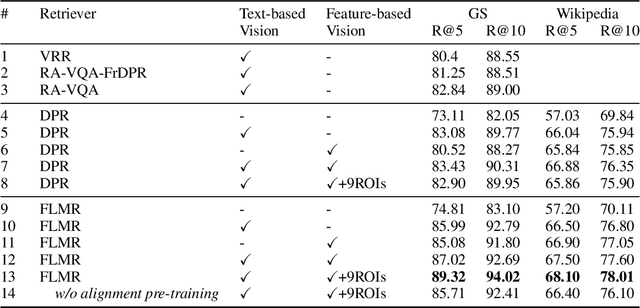
Knowledge-based Visual Question Answering (KB-VQA) requires VQA systems to utilize knowledge from existing knowledge bases to answer visually-grounded questions. Retrieval-Augmented Visual Question Answering (RA-VQA), a strong framework to tackle KB-VQA, first retrieves related documents with Dense Passage Retrieval (DPR) and then uses them to answer questions. This paper proposes Fine-grained Late-interaction Multi-modal Retrieval (FLMR) which significantly improves knowledge retrieval in RA-VQA. FLMR addresses two major limitations in RA-VQA's retriever: (1) the image representations obtained via image-to-text transforms can be incomplete and inaccurate and (2) relevance scores between queries and documents are computed with one-dimensional embeddings, which can be insensitive to finer-grained relevance. FLMR overcomes these limitations by obtaining image representations that complement those from the image-to-text transforms using a vision model aligned with an existing text-based retriever through a simple alignment network. FLMR also encodes images and questions using multi-dimensional embeddings to capture finer-grained relevance between queries and documents. FLMR significantly improves the original RA-VQA retriever's PRRecall@5 by approximately 8\%. Finally, we equipped RA-VQA with two state-of-the-art large multi-modal/language models to achieve $\sim61\%$ VQA score in the OK-VQA dataset.
Grounding Description-Driven Dialogue State Trackers with Knowledge-Seeking Turns
Sep 23, 2023Schema-guided dialogue state trackers can generalise to new domains without further training, yet they are sensitive to the writing style of the schemata. Augmenting the training set with human or synthetic schema paraphrases improves the model robustness to these variations but can be either costly or difficult to control. We propose to circumvent these issues by grounding the state tracking model in knowledge-seeking turns collected from the dialogue corpus as well as the schema. Including these turns in prompts during finetuning and inference leads to marked improvements in model robustness, as demonstrated by large average joint goal accuracy and schema sensitivity improvements on SGD and SGD-X.
Monitoring and explainability of models in production
Jul 13, 2020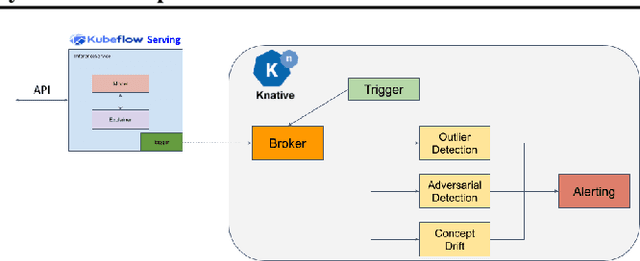
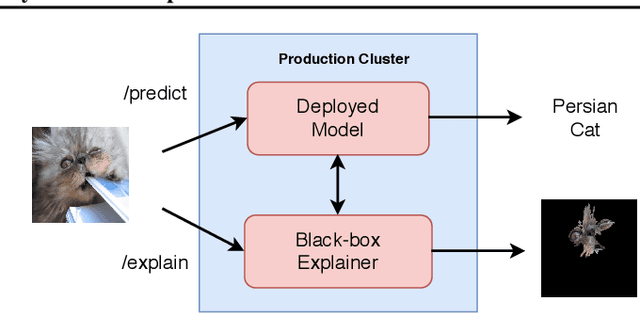
The machine learning lifecycle extends beyond the deployment stage. Monitoring deployed models is crucial for continued provision of high quality machine learning enabled services. Key areas include model performance and data monitoring, detecting outliers and data drift using statistical techniques, and providing explanations of historic predictions. We discuss the challenges to successful implementation of solutions in each of these areas with some recent examples of production ready solutions using open source tools.