 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Multivariate Change Detection with Calibrated and Memoryless False Detection Rates
Aug 02, 2021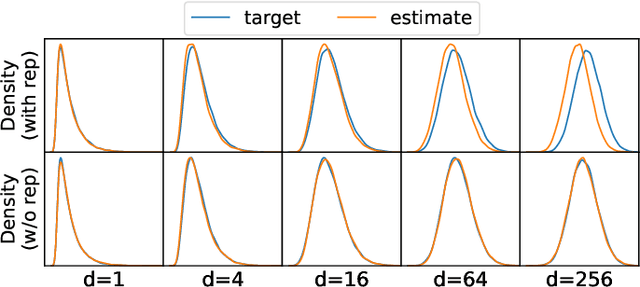
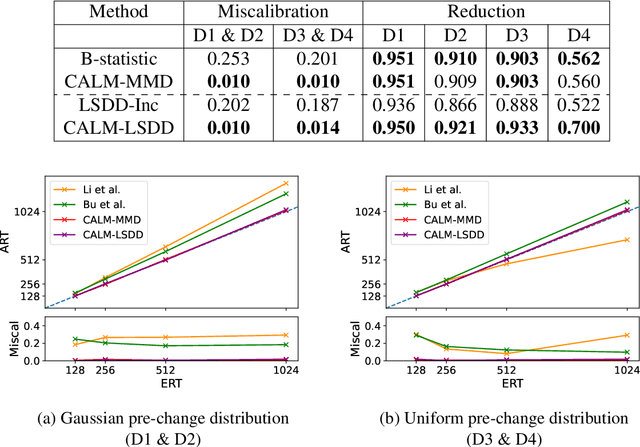
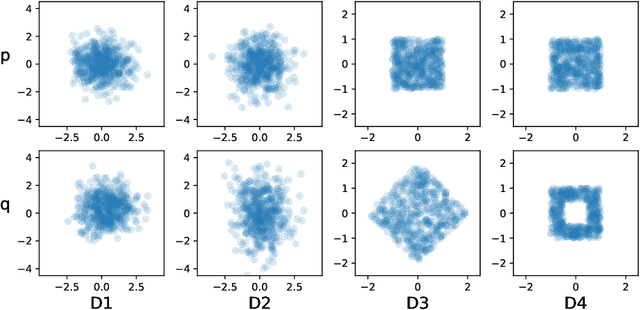
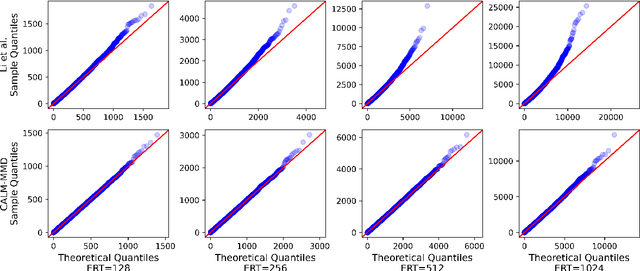
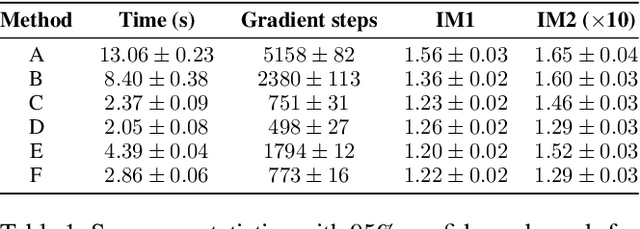
Responding appropriately to the detections of a sequential change detector requires knowledge of the rate at which false positives occur in the absence of change. When the pre-change and post-change distributions are unknown, setting detection thresholds to achieve a desired false positive rate is challenging, even when there exists a large number of samples from the reference distribution. Existing works resort to setting time-invariant thresholds that focus on the expected runtime of the detector in the absence of change, either bounding it loosely from below or targeting it directly but with asymptotic arguments that we show cause significant miscalibration in practice. We present a simulation-based approach to setting time-varying thresholds that allows a desired expected runtime to be targeted with a 20x reduction in miscalibration whilst additionally keeping the false positive rate constant across time steps. Whilst the approach to threshold setting is metric agnostic, we show that when using the popular and powerful quadratic time MMD estimator, thoughtful structuring of the computation can reduce the cost during configuration from $O(N^2B)$ to $O(N^2+NB)$ and during operation from $O(N^2)$ to $O(N)$, where $N$ is the number of reference samples and $B$ the number of bootstrap samples. Code is made available as part of the open-source Python library \texttt{alibi-detect}.
Model-agnostic and Scalable Counterfactual Explanations via Reinforcement Learning
Jun 04, 2021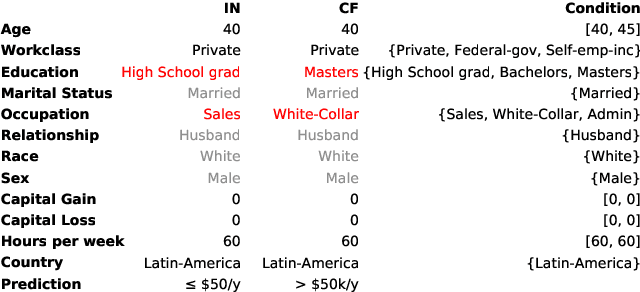
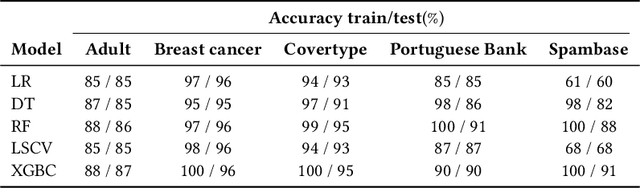
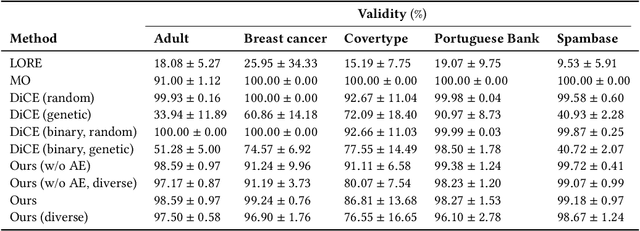

Counterfactual instances are a powerful tool to obtain valuable insights into automated decision processes, describing the necessary minimal changes in the input space to alter the prediction towards a desired target. Most previous approaches require a separate, computationally expensive optimization procedure per instance, making them impractical for both large amounts of data and high-dimensional data. Moreover, these methods are often restricted to certain subclasses of machine learning models (e.g. differentiable or tree-based models). In this work, we propose a deep reinforcement learning approach that transforms the optimization procedure into an end-to-end learnable process, allowing us to generate batches of counterfactual instances in a single forward pass. Our experiments on real-world data show that our method i) is model-agnostic (does not assume differentiability), relying only on feedback from model predictions; ii) allows for generating target-conditional counterfactual instances; iii) allows for flexible feature range constraints for numerical and categorical attributes, including the immutability of protected features (e.g. gender, race); iv) is easily extended to other data modalities such as images.
Conditional Generative Models for Counterfactual Explanations
Jan 25, 2021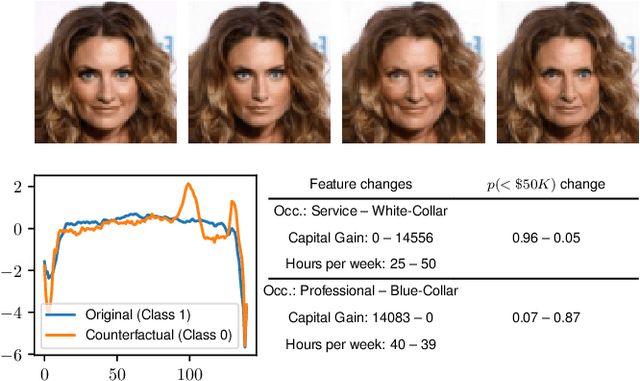


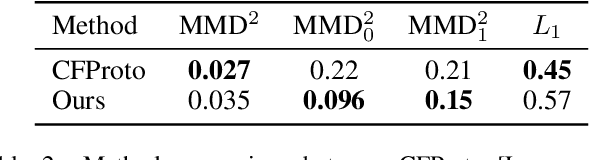
Counterfactual instances offer human-interpretable insight into the local behaviour of machine learning models. We propose a general framework to generate sparse, in-distribution counterfactual model explanations which match a desired target prediction with a conditional generative model, allowing batches of counterfactual instances to be generated with a single forward pass. The method is flexible with respect to the type of generative model used as well as the task of the underlying predictive model. This allows straightforward application of the framework to different modalities such as images, time series or tabular data as well as generative model paradigms such as GANs or autoencoders and predictive tasks like classification or regression. We illustrate the effectiveness of our method on image (CelebA), time series (ECG) and mixed-type tabular (Adult Census) data.
Monitoring and explainability of models in production
Jul 13, 2020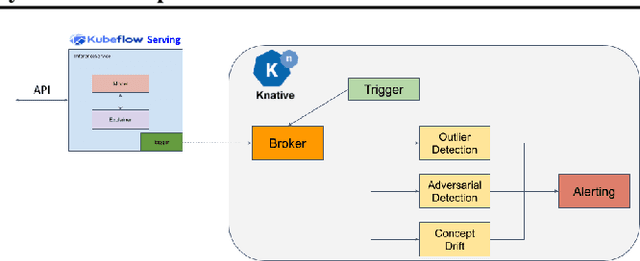
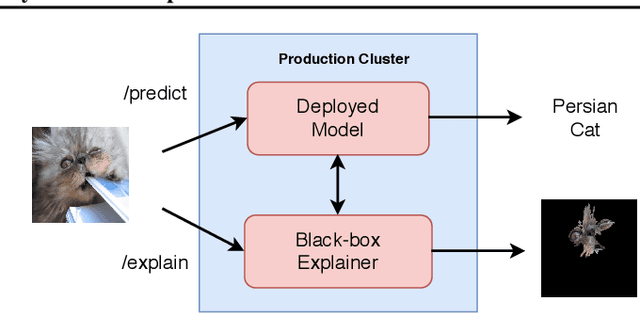
The machine learning lifecycle extends beyond the deployment stage. Monitoring deployed models is crucial for continued provision of high quality machine learning enabled services. Key areas include model performance and data monitoring, detecting outliers and data drift using statistical techniques, and providing explanations of historic predictions. We discuss the challenges to successful implementation of solutions in each of these areas with some recent examples of production ready solutions using open source tools.
ConBO: Conditional Bayesian Optimization
Feb 23, 2020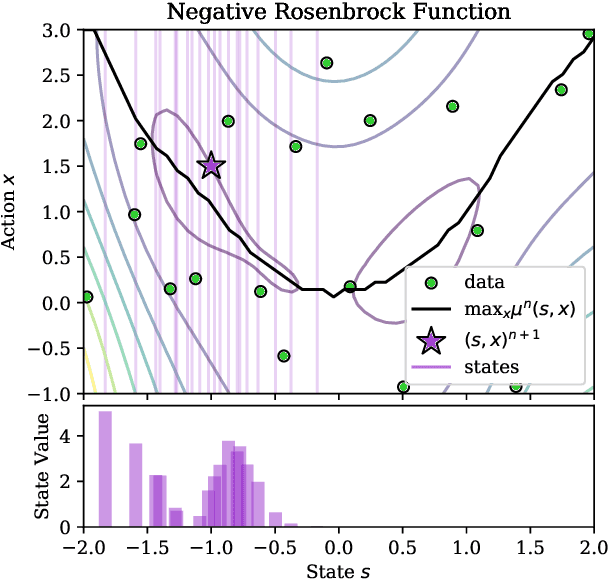
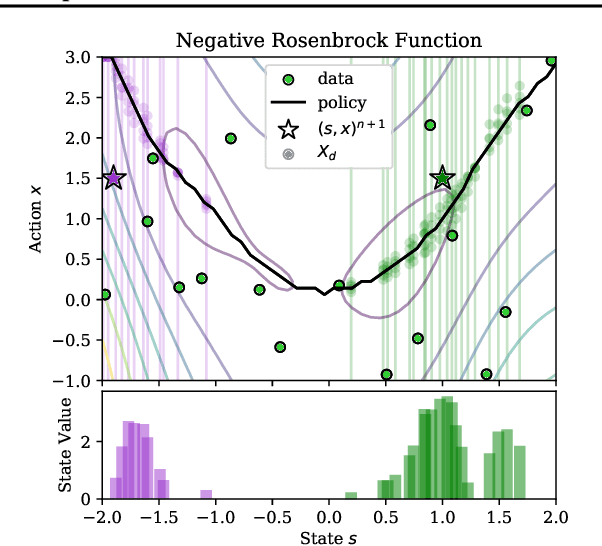
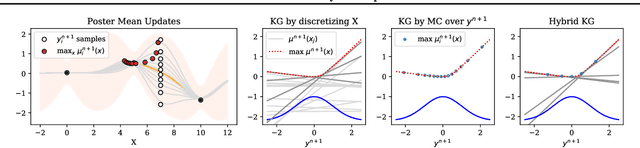
Bayesian optimization is a class of data efficient model based algorithms typically focused on global optimization. We consider the more general case where a user is faced with multiple problems that each need to be optimized conditional on a state variable, for example we optimize the location of ambulances conditioned on patient distribution given a range of cities with different patient distributions. Similarity across objectives boosts optimization of each objective in two ways: in modelling by data sharing across objectives, and also in acquisition by quantifying how all objectives benefit from a single point on one objective. For this we propose ConBO, a novel efficient algorithm that is based on a new hybrid Knowledge Gradient method, that outperforms recently published works on synthetic and real world problems, and is easily parallelized to collecting a batch of points.
Interpretable Counterfactual Explanations Guided by Prototypes
Jul 03, 2019


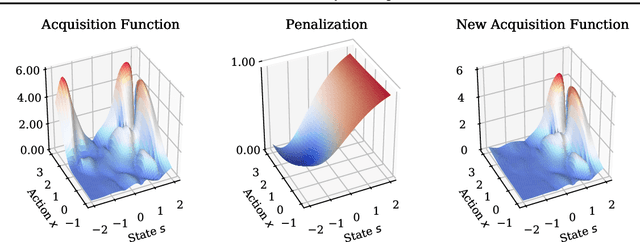
We propose a fast, model agnostic method for finding interpretable counterfactual explanations of classifier predictions by using class prototypes. We show that class prototypes, obtained using either an encoder or through class specific k-d trees, significantly speed up the the search for counterfactual instances and result in more interpretable explanations. We introduce two novel metrics to quantitatively evaluate local interpretability at the instance level. We use these metrics to illustrate the effectiveness of our method on an image and tabular dataset, respectively MNIST and Breast Cancer Wisconsin (Diagnostic). The method also eliminates the computational bottleneck that arises because of numerical gradient evaluation for $\textit{black box}$ models.