 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesiderata for next generation of ML model serving
Oct 26, 2022
Inference is a significant part of ML software infrastructure. Despite the variety of inference frameworks available, the field as a whole can be considered in its early days. This paper puts forth a range of important qualities that next generation of inference platforms should be aiming for. We present our rationale for the importance of each quality, and discuss ways to achieve it in practice. An overarching design pattern is data-centricity, which enables smarter monitoring in ML system operation.
Serverless inferencing on Kubernetes
Jul 24, 2020
Organisations are increasingly putting machine learning models into production at scale. The increasing popularity of serverless scale-to-zero paradigms presents an opportunity for deploying machine learning models to help mitigate infrastructure costs when many models may not be in continuous use. We will discuss the KFServing project which builds on the KNative serverless paradigm to provide a serverless machine learning inference solution that allows a consistent and simple interface for data scientists to deploy their models. We will show how it solves the challenges of autoscaling GPU based inference and discuss some of the lessons learnt from using it in production.
Monitoring and explainability of models in production
Jul 13, 2020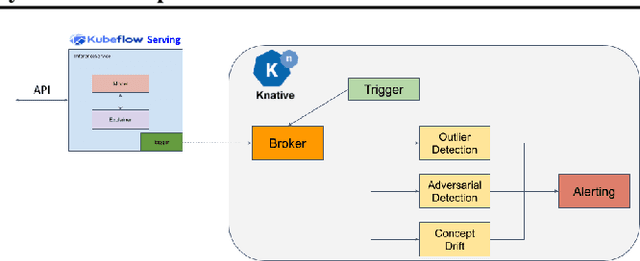
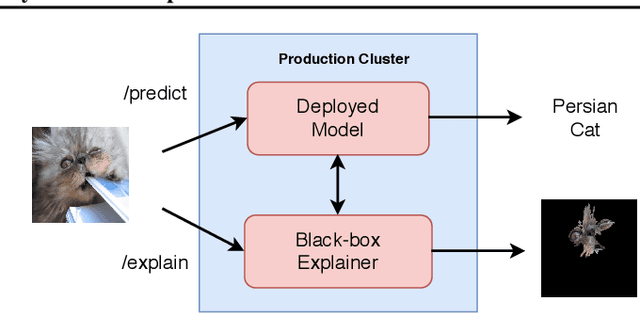
The machine learning lifecycle extends beyond the deployment stage. Monitoring deployed models is crucial for continued provision of high quality machine learning enabled services. Key areas include model performance and data monitoring, detecting outliers and data drift using statistical techniques, and providing explanations of historic predictions. We discuss the challenges to successful implementation of solutions in each of these areas with some recent examples of production ready solutions using open source tools.