 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Models for Counterfactual Explanations
Jan 25, 2021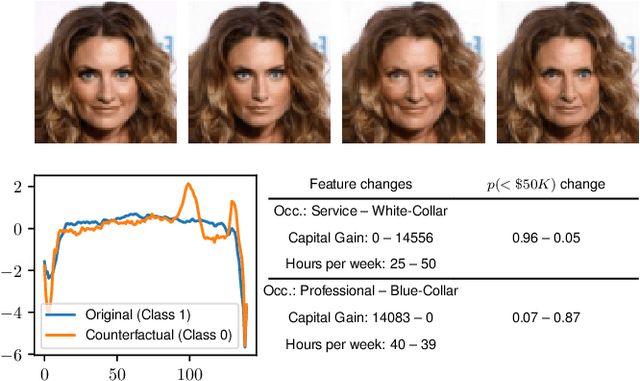


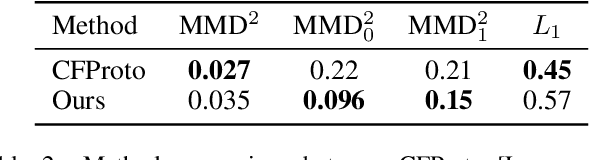
Counterfactual instances offer human-interpretable insight into the local behaviour of machine learning models. We propose a general framework to generate sparse, in-distribution counterfactual model explanations which match a desired target prediction with a conditional generative model, allowing batches of counterfactual instances to be generated with a single forward pass. The method is flexible with respect to the type of generative model used as well as the task of the underlying predictive model. This allows straightforward application of the framework to different modalities such as images, time series or tabular data as well as generative model paradigms such as GANs or autoencoders and predictive tasks like classification or regression. We illustrate the effectiveness of our method on image (CelebA), time series (ECG) and mixed-type tabular (Adult Census) data.
Monitoring and explainability of models in production
Jul 13, 2020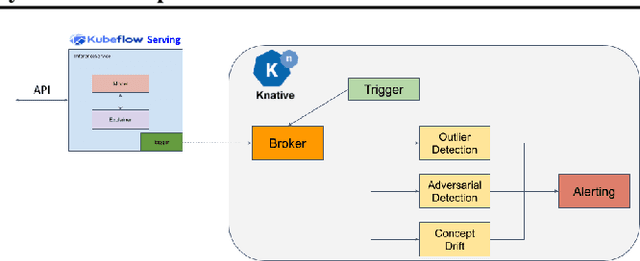
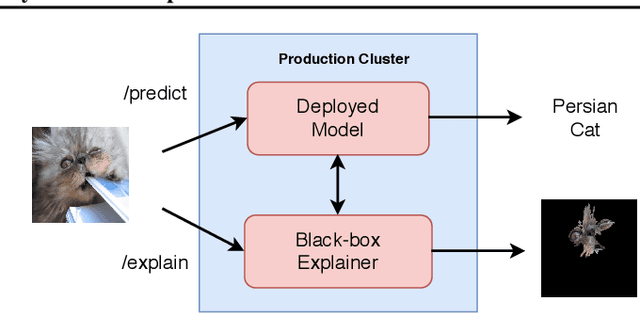
The machine learning lifecycle extends beyond the deployment stage. Monitoring deployed models is crucial for continued provision of high quality machine learning enabled services. Key areas include model performance and data monitoring, detecting outliers and data drift using statistical techniques, and providing explanations of historic predictions. We discuss the challenges to successful implementation of solutions in each of these areas with some recent examples of production ready solutions using open source tools.
Adversarial Detection and Correction by Matching Prediction Distributions
Feb 21, 2020
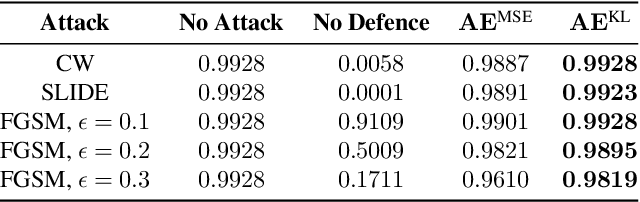
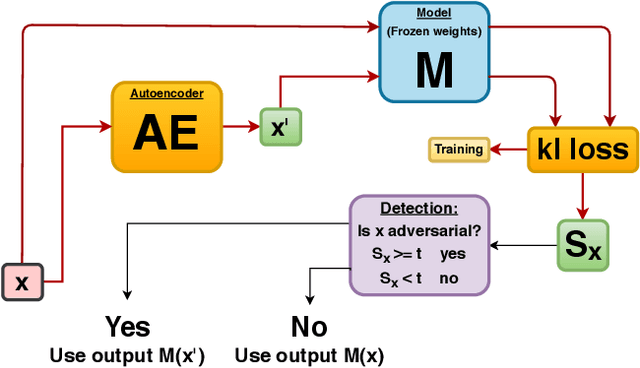
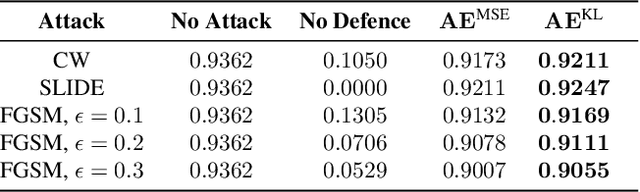
We present a novel adversarial detection and correction method for machine learning classifiers.The detector consists of an autoencoder trained with a custom loss function based on the Kullback-Leibler divergence between the classifier predictions on the original and reconstructed instances.The method is unsupervised, easy to train and does not require any knowledge about the underlying attack. The detector almost completely neutralises powerful attacks like Carlini-Wagner or SLIDE on MNIST and Fashion-MNIST, and remains very effective on CIFAR-10 when the attack is granted full access to the classification model but not the defence. We show that our method is still able to detect the adversarial examples in the case of a white-box attack where the attacker has full knowledge of both the model and the defence and investigate the robustness of the attack. The method is very flexible and can also be used to detect common data corruptions and perturbations which negatively impact the model performance. We illustrate this capability on the CIFAR-10-C dataset.