 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Mar 01, 2024Virtual assistants are poised to take a dramatic leap forward in terms of their dialogue capabilities, spurred by recent advances in transformer-based Large Language Models (LLMs). Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality and linguistically sophisticated data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 multi-domain, multi-intent conversations across 100 intents to demonstrate its capabilities. The generated conversations include a wide range of challenging phenomena and diverse user behaviour, conveniently identifiable via a set of turn-level tags. Finally, we provide separate test sets for seen and unseen intents, allowing for convenient out-of-distribution evaluation. We release both the data generation code and the dataset itself.
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
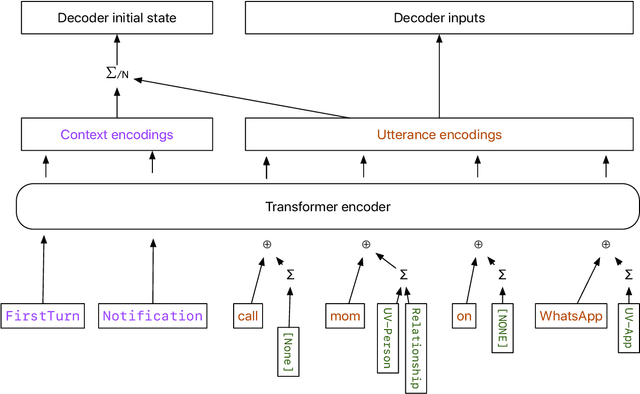
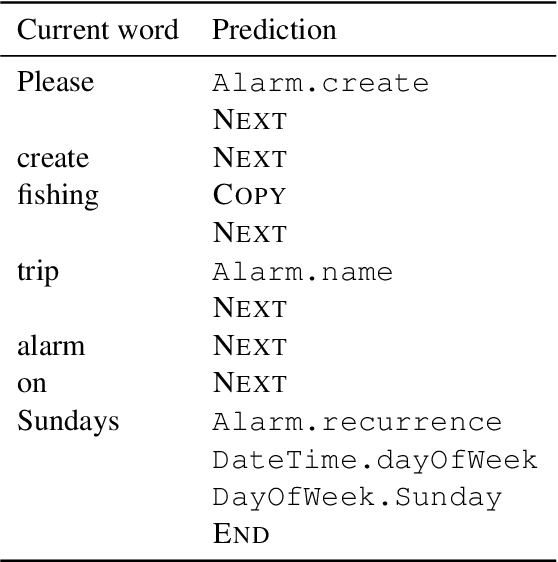

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.