 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios
Aug 27, 2025Large Language Models (LLMs) have achieved high accuracy on complex commonsense and mathematical problems that involve the composition of multiple reasoning steps. However, current compositional benchmarks testing these skills tend to focus on either commonsense or math reasoning, whereas LLM agents solving real-world tasks would require a combination of both. In this work, we introduce an Agentic Commonsense and Math benchmark (AgentCoMa), where each compositional task requires a commonsense reasoning step and a math reasoning step. We test it on 61 LLMs of different sizes, model families, and training strategies. We find that LLMs can usually solve both steps in isolation, yet their accuracy drops by ~30% on average when the two are combined. This is a substantially greater performance gap than the one we observe in prior compositional benchmarks that combine multiple steps of the same reasoning type. In contrast, non-expert human annotators can solve the compositional questions and the individual steps in AgentCoMa with similarly high accuracy. Furthermore, we conduct a series of interpretability studies to better understand the performance gap, examining neuron patterns, attention maps and membership inference. Our work underscores a substantial degree of model brittleness in the context of mixed-type compositional reasoning and offers a test bed for future improvement.
How to Improve the Robustness of Closed-Source Models on NLI
May 26, 2025Closed-source Large Language Models (LLMs) have become increasingly popular, with impressive performance across a wide range of natural language tasks. These models can be fine-tuned to further improve performance, but this often results in the models learning from dataset-specific heuristics that reduce their robustness on out-of-distribution (OOD) data. Existing methods to improve robustness either perform poorly, or are non-applicable to closed-source models because they assume access to model internals, or the ability to change the model's training procedure. In this work, we investigate strategies to improve the robustness of closed-source LLMs through data-centric methods that do not require access to model internals. We find that the optimal strategy depends on the complexity of the OOD data. For highly complex OOD datasets, upsampling more challenging training examples can improve robustness by up to 1.5%. For less complex OOD datasets, replacing a portion of the training set with LLM-generated examples can improve robustness by 3.7%. More broadly, we find that large-scale closed-source autoregressive LLMs are substantially more robust than commonly used encoder models, and are a more appropriate choice of baseline going forward.
LUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Mar 01, 2024



Virtual assistants are poised to take a dramatic leap forward in terms of their dialogue capabilities, spurred by recent advances in transformer-based Large Language Models (LLMs). Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality and linguistically sophisticated data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 multi-domain, multi-intent conversations across 100 intents to demonstrate its capabilities. The generated conversations include a wide range of challenging phenomena and diverse user behaviour, conveniently identifiable via a set of turn-level tags. Finally, we provide separate test sets for seen and unseen intents, allowing for convenient out-of-distribution evaluation. We release both the data generation code and the dataset itself.
Logical Reasoning for Natural Language Inference Using Generated Facts as Atoms
May 22, 2023
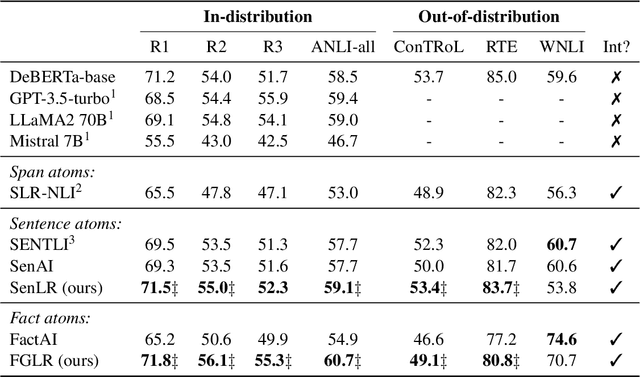


State-of-the-art neural models can now reach human performance levels across various natural language understanding tasks. However, despite this impressive performance, models are known to learn from annotation artefacts at the expense of the underlying task. While interpretability methods can identify influential features for each prediction, there are no guarantees that these features are responsible for the model decisions. Instead, we introduce a model-agnostic logical framework to determine the specific information in an input responsible for each model decision. This method creates interpretable Natural Language Inference (NLI) models that maintain their predictive power. We achieve this by generating facts that decompose complex NLI observations into individual logical atoms. Our model makes predictions for each atom and uses logical rules to decide the class of the observation based on the predictions for each atom. We apply our method to the highly challenging ANLI dataset, where our framework improves the performance of both a DeBERTa-base and BERT baseline. Our method performs best on the most challenging examples, achieving a new state-of-the-art for the ANLI round 3 test set. We outperform every baseline in a reduced-data setting, and despite using no annotations for the generated facts, our model predictions for individual facts align with human expectations.
Improving Robustness in Knowledge Distillation Using Domain-Targeted Data Augmentation
May 22, 2023



Applying knowledge distillation encourages a student model to behave more like a teacher model, largely retaining the performance of the teacher model, even though the student model may have substantially fewer parameters. However, while distillation helps student models behave more like teacher models in-distribution, this is not necessarily the case out-of-distribution. To address this, we use a language model to create task-specific unlabeled data that mimics the data in targeted out-of-distribution domains. We use this generated data for knowledge distillation on the task of Natural Language Inference (NLI), encouraging the student models to behave more like the teacher models for these examples. Our domain-targeted augmentation is highly effective, and outperforms previous robustness methods when evaluating out-of-distribution performance on MNLI. Surprisingly, this method also improves performance on out-of-distribution domains that the data was not generated for. We additionally introduce Distilled Minority Upsampling (DMU), a method for identifying and upsampling minority examples during the distillation. DMU is complementary to the domain-targeted augmentation, and substantially improves performance on SNLI-hard. Finally, we show out-of-distribution improvements on HANS from both of our methods, despite augmenting the training data with fewer than 5k examples.
Logical Reasoning with Span Predictions: Span-level Logical Atoms for Interpretable and Robust NLI Models
May 23, 2022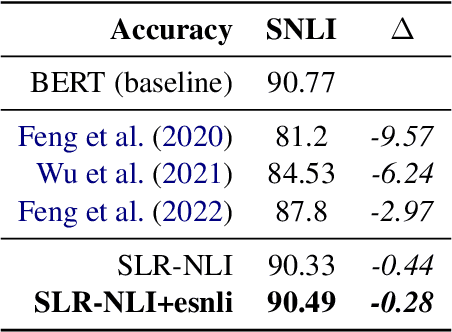

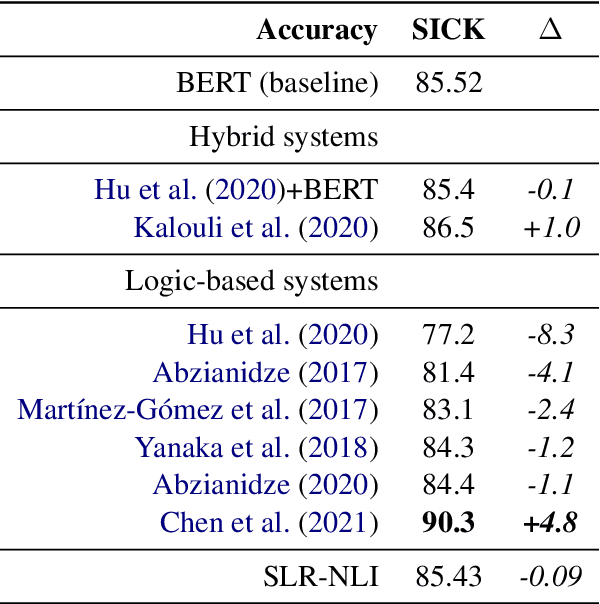
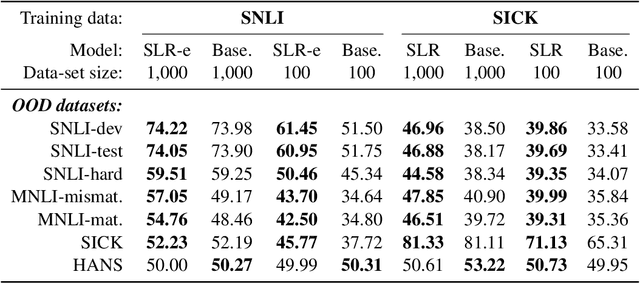
Current Natural Language Inference (NLI) models achieve impressive results, sometimes outperforming humans when evaluating on in-distribution test sets. However, as these models are known to learn from annotation artefacts and dataset biases, it is unclear to what extent the models are learning the task of NLI instead of learning from shallow heuristics in their training data. We address this issue by introducing a logical reasoning framework for NLI, creating highly transparent model decisions that are based on logical rules. Unlike prior work, we show that the improved interpretability can be achieved without decreasing the predictive accuracy. We almost fully retain performance on SNLI while identifying the exact hypothesis spans that are responsible for each model prediction. Using the e-SNLI human explanations, we also verify that our model makes sensible decisions at a span level, despite not using any span-level labels during training. We can further improve model performance and the span-level decisions by using the e-SNLI explanations during training. Finally, our model outperforms its baseline in a reduced data setting. When training with only 100 examples, in-distribution performance improves by 18%, while out-of-distribution performance improves on SNLI-hard, MNLI-mismatched, MNLI-matched and SICK by 11%, 26%, 22%, and 21% respectively.
Natural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Apr 16, 2021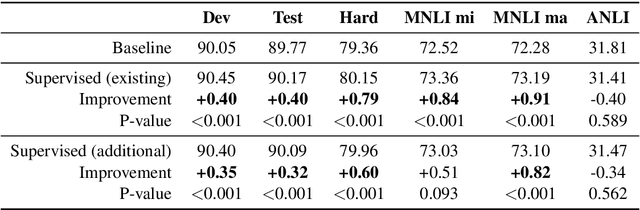
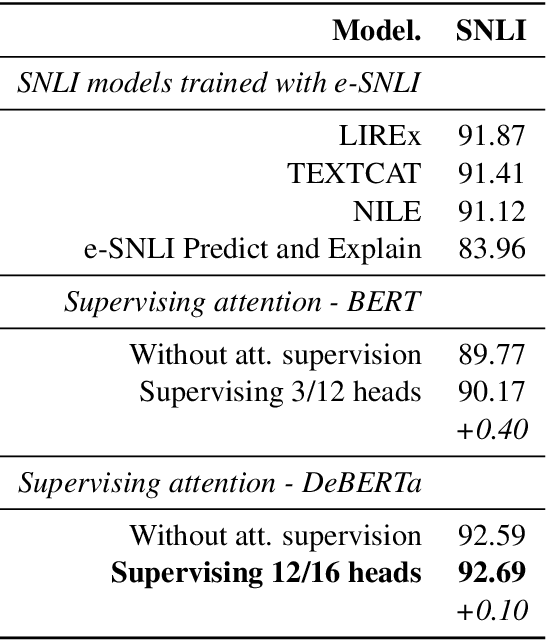
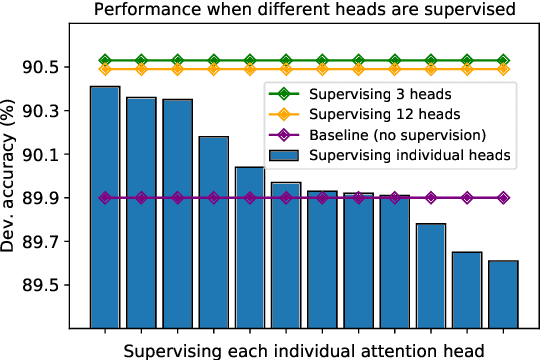
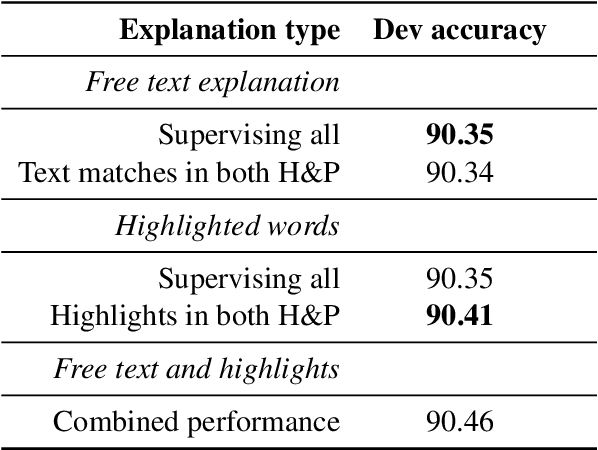
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.
There is Strength in Numbers: Avoiding the Hypothesis-Only Bias in Natural Language Inference via Ensemble Adversarial Training
Apr 27, 2020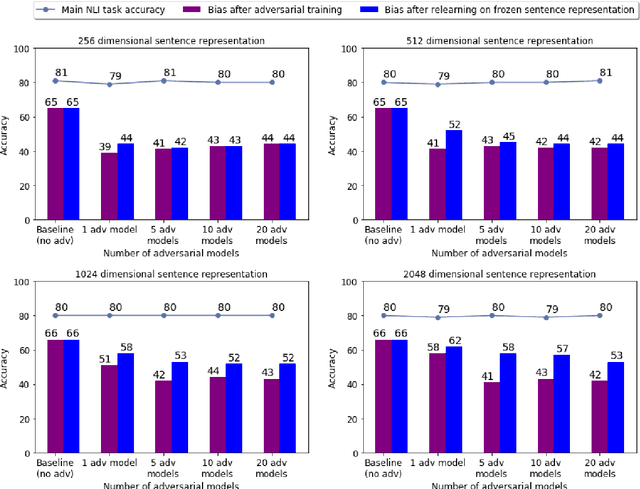

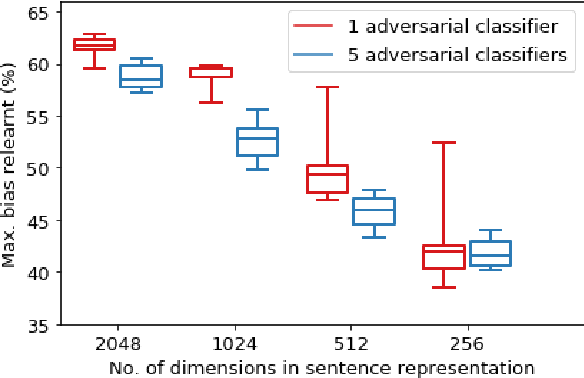

Natural Language Inference (NLI) datasets contain annotation artefacts resulting in spurious correlations between the natural language utterances and their respective entailment classes. These artefacts are exploited by neural networks even when only considering the hypothesis and ignoring the premise, leading to unwanted biases. Previous work proposed tackling this problem via adversarial training, but this leads to learned sentence representations that still suffer from the same biases. As a solution, we propose using an ensemble of adversaries during the training, encouraging the model to jointly decrease the accuracy of these different adversaries while fitting the data. We show that using an ensemble of adversaries can prevent the bias from being relearned after the model training is completed, further improving how well the model generalises to different NLI datasets. In particular, these models outperformed previous approaches when tested on 12 different NLI datasets not used in the model training. Finally, the optimal number of adversarial classifiers depends on the dimensionality of the sentence representations, with larger dimensional representations benefiting when trained with a greater number of adversaries.