 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Paper and Code
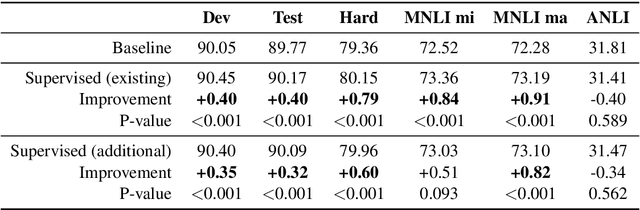
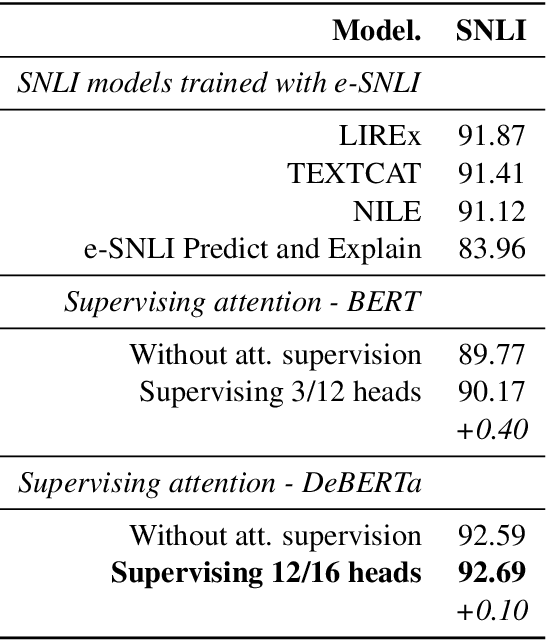
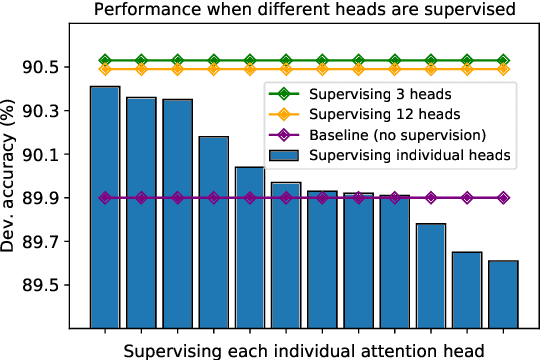
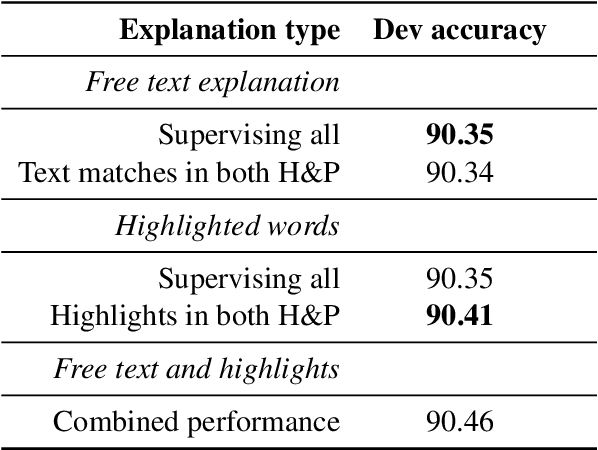
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.