 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
Scaling Small Agents Through Strategy Auctions
Feb 02, 2026Small language models are increasingly viewed as a promising, cost-effective approach to agentic AI, with proponents claiming they are sufficiently capable for agentic workflows. However, while smaller agents can closely match larger ones on simple tasks, it remains unclear how their performance scales with task complexity, when large models become necessary, and how to better leverage small agents for long-horizon workloads. In this work, we empirically show that small agents' performance fails to scale with task complexity on deep search and coding tasks, and we introduce Strategy Auctions for Workload Efficiency (SALE), an agent framework inspired by freelancer marketplaces. In SALE, agents bid with short strategic plans, which are scored by a systematic cost-value mechanism and refined via a shared auction memory, enabling per-task routing and continual self-improvement without training a separate router or running all models to completion. Across deep search and coding tasks of varying complexity, SALE reduces reliance on the largest agent by 53%, lowers overall cost by 35%, and consistently improves upon the largest agent's pass@1 with only a negligible overhead beyond executing the final trace. In contrast, established routers that rely on task descriptions either underperform the largest agent or fail to reduce cost -- often both -- underscoring their poor fit for agentic workflows. These results suggest that while small agents may be insufficient for complex workloads, they can be effectively "scaled up" through coordinated task allocation and test-time self-improvement. More broadly, they motivate a systems-level view of agentic AI in which performance gains come less from ever-larger individual models and more from market-inspired coordination mechanisms that organize heterogeneous agents into efficient, adaptive ecosystems.
Culturally Grounded Physical Commonsense Reasoning in Italian and English: A Submission to the MRL 2025 Shared Task
Oct 26, 2025This paper presents our submission to the MRL 2025 Shared Task on Multilingual Physical Reasoning Datasets. The objective of the shared task is to create manually-annotated evaluation data in the physical commonsense reasoning domain, for languages other than English, following a format similar to PIQA. Our contribution, FormaMentis, is a novel benchmark for physical commonsense reasoning that is grounded in Italian language and culture. The data samples in FormaMentis are created by expert annotators who are native Italian speakers and are familiar with local customs and norms. The samples are additionally translated into English, while preserving the cultural elements unique to the Italian context.
AgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios
Aug 27, 2025Large Language Models (LLMs) have achieved high accuracy on complex commonsense and mathematical problems that involve the composition of multiple reasoning steps. However, current compositional benchmarks testing these skills tend to focus on either commonsense or math reasoning, whereas LLM agents solving real-world tasks would require a combination of both. In this work, we introduce an Agentic Commonsense and Math benchmark (AgentCoMa), where each compositional task requires a commonsense reasoning step and a math reasoning step. We test it on 61 LLMs of different sizes, model families, and training strategies. We find that LLMs can usually solve both steps in isolation, yet their accuracy drops by ~30% on average when the two are combined. This is a substantially greater performance gap than the one we observe in prior compositional benchmarks that combine multiple steps of the same reasoning type. In contrast, non-expert human annotators can solve the compositional questions and the individual steps in AgentCoMa with similarly high accuracy. Furthermore, we conduct a series of interpretability studies to better understand the performance gap, examining neuron patterns, attention maps and membership inference. Our work underscores a substantial degree of model brittleness in the context of mixed-type compositional reasoning and offers a test bed for future improvement.
How to Improve the Robustness of Closed-Source Models on NLI
May 26, 2025Closed-source Large Language Models (LLMs) have become increasingly popular, with impressive performance across a wide range of natural language tasks. These models can be fine-tuned to further improve performance, but this often results in the models learning from dataset-specific heuristics that reduce their robustness on out-of-distribution (OOD) data. Existing methods to improve robustness either perform poorly, or are non-applicable to closed-source models because they assume access to model internals, or the ability to change the model's training procedure. In this work, we investigate strategies to improve the robustness of closed-source LLMs through data-centric methods that do not require access to model internals. We find that the optimal strategy depends on the complexity of the OOD data. For highly complex OOD datasets, upsampling more challenging training examples can improve robustness by up to 1.5%. For less complex OOD datasets, replacing a portion of the training set with LLM-generated examples can improve robustness by 3.7%. More broadly, we find that large-scale closed-source autoregressive LLMs are substantially more robust than commonly used encoder models, and are a more appropriate choice of baseline going forward.
Reverse Engineering Human Preferences with Reinforcement Learning
May 21, 2025The capabilities of Large Language Models (LLMs) are routinely evaluated by other LLMs trained to predict human preferences. This framework--known as LLM-as-a-judge--is highly scalable and relatively low cost. However, it is also vulnerable to malicious exploitation, as LLM responses can be tuned to overfit the preferences of the judge. Previous work shows that the answers generated by a candidate-LLM can be edited post hoc to maximise the score assigned to them by a judge-LLM. In this study, we adopt a different approach and use the signal provided by judge-LLMs as a reward to adversarially tune models that generate text preambles designed to boost downstream performance. We find that frozen LLMs pipelined with these models attain higher LLM-evaluation scores than existing frameworks. Crucially, unlike other frameworks which intervene directly on the model's response, our method is virtually undetectable. We also demonstrate that the effectiveness of the tuned preamble generator transfers when the candidate-LLM and the judge-LLM are replaced with models that are not used during training. These findings raise important questions about the design of more reliable LLM-as-a-judge evaluation settings. They also demonstrate that human preferences can be reverse engineered effectively, by pipelining LLMs to optimise upstream preambles via reinforcement learning--an approach that could find future applications in diverse tasks and domains beyond adversarial attacks.
Enhancing LLM Robustness to Perturbed Instructions: An Empirical Study
Apr 03, 2025Large Language Models (LLMs) are highly vulnerable to input perturbations, as even a small prompt change may result in a substantially different output. Existing methods to enhance LLM robustness are primarily focused on perturbed data samples, whereas improving resiliency to perturbations of task-level instructions has remained relatively underexplored. In this work, we focus on character- and word-level edits of task-specific instructions, which substantially degrade downstream performance. We experiment with a variety of techniques to enhance the robustness of LLMs, including self-denoising and representation alignment, testing different models (Llama 3 and Flan-T5), datasets (CoLA, QNLI, SST-2) and instructions (both task-oriented and role-oriented). We find that, on average, self-denoising -- whether performed by a frozen LLM or a fine-tuned model -- achieves substantially higher performance gains than alternative strategies, including more complex baselines such as ensembling and supervised methods.
How can representation dimension dominate structurally pruned LLMs?
Mar 06, 2025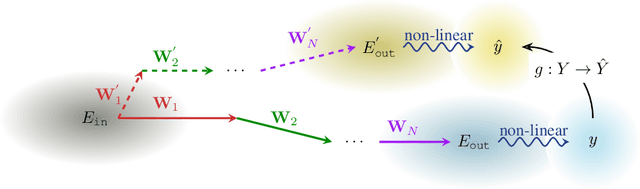



Pruning assumes a subnetwork exists in the original deep neural network, which can achieve comparative model performance with less computation than the original. However, it is unclear how the model performance varies with the different subnetwork extractions. In this paper, we choose the representation dimension (or embedding dimension, model dimension, the dimension of the residual stream in the relevant literature) as the entry point to this issue. We investigate the linear transformations in the LLM transformer blocks and consider a specific structured pruning approach, SliceGPT, to extract the subnetworks of different representation dimensions. We mechanistically analyse the activation flow during the model forward passes, and find the representation dimension dominates the linear transformations, model predictions, and, finally, the model performance. Explicit analytical relations are given to calculate the pruned model performance (perplexity and accuracy) without actual evaluation, and are empirically validated with Llama-3-8B-Instruct and Phi-3-mini-4k-Instruct.
LLMs can implicitly learn from mistakes in-context
Feb 12, 2025Learning from mistakes is a fundamental feature of human intelligence. Previous work has shown that Large Language Models (LLMs) can also learn from incorrect answers when provided with a comprehensive rationale detailing why an answer is wrong or how to correct it. In this work, we examine whether LLMs can learn from mistakes in mathematical reasoning tasks when these explanations are not provided. We investigate if LLMs are able to implicitly infer such rationales simply from observing both incorrect and correct answers. Surprisingly, we find that LLMs perform better, on average, when rationales are eliminated from the context and incorrect answers are simply shown alongside correct ones. This approach also substantially outperforms chain-of-thought prompting in our evaluations. We show that these results are consistent across LLMs of different sizes and varying reasoning abilities. Further, we carry out an in-depth analysis, and show that prompting with both wrong and correct answers leads to greater performance and better generalisation than introducing additional, more diverse question-answer pairs into the context. Finally, we show that new rationales generated by models that have only observed incorrect and correct answers are scored equally as highly by humans as those produced with the aid of exemplar rationales. Our results demonstrate that LLMs are indeed capable of in-context implicit learning.
Meta-Reasoning Improves Tool Use in Large Language Models
Nov 07, 2024External tools help large language models (LLMs) succeed at tasks where they would otherwise typically fail. In existing frameworks, LLMs learn tool use either by in-context demonstrations or via full model fine-tuning on annotated data. As these approaches do not easily scale, a recent trend is to abandon them in favor of lightweight, parameter-efficient tuning paradigms. These methods allow quickly alternating between the frozen LLM and its specialised fine-tuned version, by switching on or off a handful of additional custom parameters. Hence, we postulate that the generalization ability of the frozen model can be leveraged to improve tool selection. We present Tool selECTion via meta-reasONing (TECTON), a two-phase system that first reasons over a task using a custom fine-tuned LM head and outputs candidate tools. Then, with the custom head disabled, it meta-reasons (i.e., it reasons over the previous reasoning process) to make a final choice. We show that TECTON results in substantial gains - both in-distribution and out-of-distribution - on a range of math reasoning datasets.