 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting LLM Compression Degradation from Spectral Statistics
Apr 20, 2026Matrix-level low-rank compression is a promising way to reduce the cost of large language models, but running compression and evaluating the resulting models on language tasks can be prohibitively expensive. Can compression-induced degradation be predicted before committing to this compute? We systematically analyze the Qwen3 and Gemma3 model families across four representative low-rank compression methods: vanilla SVD, two ASVD variants, and SVD-LLM. We find that stable rank and information density, measured in bits per parameter, dominate performance degradation. The interaction term $γ\cdot \barρ_s$, defined as compression ratio times stable rank, is a robust predictor of accuracy degradation, achieving leave-one-out cross-validation Pearson correlations of $0.890$ for attention layers and $0.839$ for MLP layers. We provide theoretical intuition for why this predictor succeeds by connecting it to standard SVD truncation bounds and error composition mechanisms in transformer layers. These findings enable a predict-then-compress workflow: compute $γ\cdot \barρ_s$ from weights, estimate degradation, and invest compute only in desirable configurations.
TensorSLM: Energy-efficient Embedding Compression of Sub-billion Parameter Language Models on Low-end Devices
Jun 16, 2025Small Language Models (SLMs, or on-device LMs) have significantly fewer parameters than Large Language Models (LLMs). They are typically deployed on low-end devices, like mobile phones and single-board computers. Unlike LLMs, which rely on increasing model size for better generalisation, SLMs designed for edge applications are expected to have adaptivity to the deployment environments and energy efficiency given the device battery life constraints, which are not addressed in datacenter-deployed LLMs. This paper addresses these two requirements by proposing a training-free token embedding compression approach using Tensor-Train Decomposition (TTD). Each pre-trained token embedding vector is converted into a lower-dimensional Matrix Product State (MPS). We comprehensively evaluate the extracted low-rank structures across compression ratio, language task performance, latency, and energy consumption on a typical low-end device, i.e. Raspberry Pi. Taking the sub-billion parameter versions of GPT-2/Cerebres-GPT and OPT models as examples, our approach achieves a comparable language task performance to the original model with around $2.0\times$ embedding layer compression, while the energy consumption of a single query drops by half.
How can representation dimension dominate structurally pruned LLMs?
Mar 06, 2025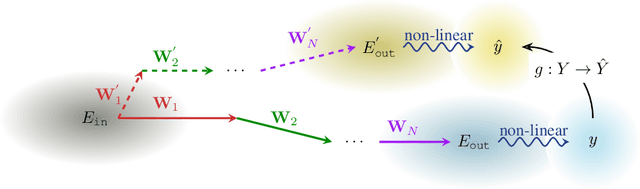



Pruning assumes a subnetwork exists in the original deep neural network, which can achieve comparative model performance with less computation than the original. However, it is unclear how the model performance varies with the different subnetwork extractions. In this paper, we choose the representation dimension (or embedding dimension, model dimension, the dimension of the residual stream in the relevant literature) as the entry point to this issue. We investigate the linear transformations in the LLM transformer blocks and consider a specific structured pruning approach, SliceGPT, to extract the subnetworks of different representation dimensions. We mechanistically analyse the activation flow during the model forward passes, and find the representation dimension dominates the linear transformations, model predictions, and, finally, the model performance. Explicit analytical relations are given to calculate the pruned model performance (perplexity and accuracy) without actual evaluation, and are empirically validated with Llama-3-8B-Instruct and Phi-3-mini-4k-Instruct.
Geometry is All You Need: A Unified Taxonomy of Matrix and Tensor Factorization for Compression of Generative Language Models
Oct 03, 2024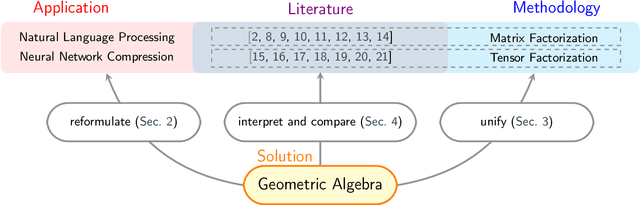

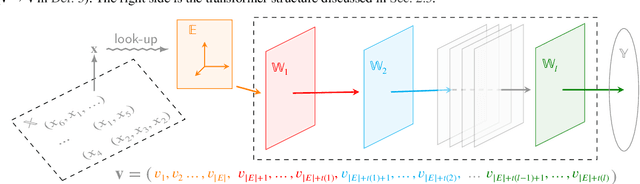
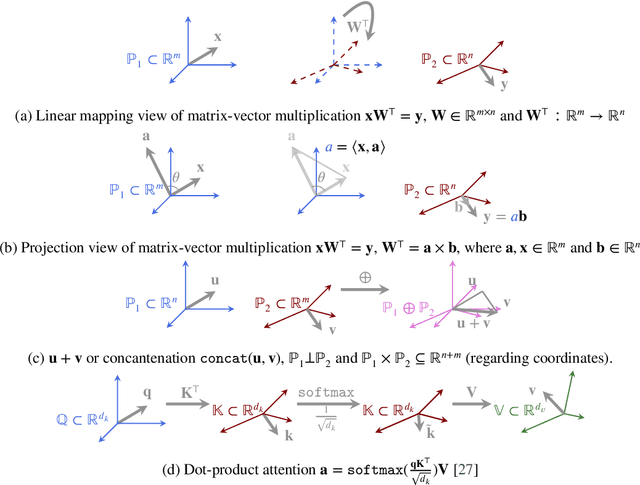
Matrix and tensor-guided parametrization for Natural Language Processing (NLP) models is fundamentally useful for the improvement of the model's systematic efficiency. However, the internal links between these two algebra structures and language model parametrization are poorly understood. Also, the existing matrix and tensor research is math-heavy and far away from machine learning (ML) and NLP research concepts. These two issues result in the recent progress on matrices and tensors for model parametrization being more like a loose collection of separate components from matrix/tensor and NLP studies, rather than a well-structured unified approach, further hindering algorithm design. To this end, we propose a unified taxonomy, which bridges the matrix/tensor compression approaches and model compression concepts in ML and NLP research. Namely, we adopt an elementary concept in linear algebra, that of a subspace, which is also the core concept in geometric algebra, to reformulate the matrix/tensor and ML/NLP concepts (e.g. attention mechanism) under one umbrella. In this way, based on our subspace formalization, typical matrix and tensor decomposition algorithms can be interpreted as geometric transformations. Finally, we revisit recent literature on matrix- or tensor-guided language model compression, rephrase and compare their core ideas, and then point out the current research gap and potential solutions.
FinLlama: Financial Sentiment Classification for Algorithmic Trading Applications
Mar 18, 2024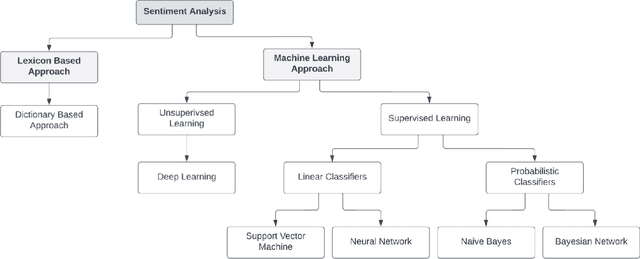
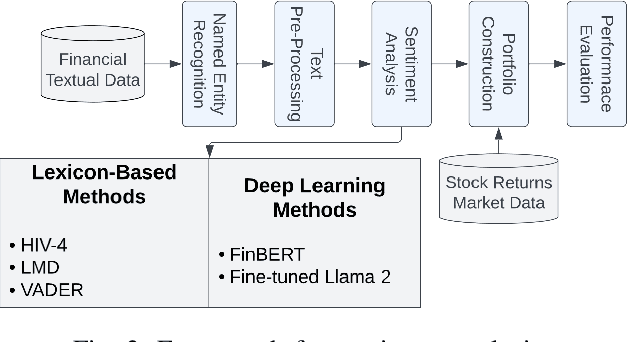
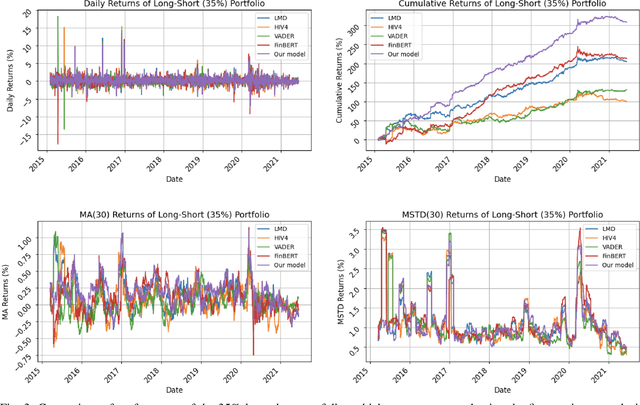

There are multiple sources of financial news online which influence market movements and trader's decisions. This highlights the need for accurate sentiment analysis, in addition to having appropriate algorithmic trading techniques, to arrive at better informed trading decisions. Standard lexicon based sentiment approaches have demonstrated their power in aiding financial decisions. However, they are known to suffer from issues related to context sensitivity and word ordering. Large Language Models (LLMs) can also be used in this context, but they are not finance-specific and tend to require significant computational resources. To facilitate a finance specific LLM framework, we introduce a novel approach based on the Llama 2 7B foundational model, in order to benefit from its generative nature and comprehensive language manipulation. This is achieved by fine-tuning the Llama2 7B model on a small portion of supervised financial sentiment analysis data, so as to jointly handle the complexities of financial lexicon and context, and further equipping it with a neural network based decision mechanism. Such a generator-classifier scheme, referred to as FinLlama, is trained not only to classify the sentiment valence but also quantify its strength, thus offering traders a nuanced insight into financial news articles. Complementing this, the implementation of parameter-efficient fine-tuning through LoRA optimises trainable parameters, thus minimising computational and memory requirements, without sacrificing accuracy. Simulation results demonstrate the ability of the proposed FinLlama to provide a framework for enhanced portfolio management decisions and increased market returns. These results underpin the ability of FinLlama to construct high-return portfolios which exhibit enhanced resilience, even during volatile periods and unpredictable market events.
TensorGPT: Efficient Compression of the Embedding Layer in LLMs based on the Tensor-Train Decomposition
Jul 02, 2023



High-dimensional token embeddings underpin Large Language Models (LLMs), as they can capture subtle semantic information and significantly enhance the modelling of complex language patterns. However, the associated high dimensionality also introduces considerable model parameters, and a prohibitively high model storage. To address this issue, this work proposes an approach based on the Tensor-Train Decomposition (TTD), where each token embedding is treated as a Matrix Product State (MPS) that can be efficiently computed in a distributed manner. The experimental results on GPT-2 demonstrate that, through our approach, the embedding layer can be compressed by a factor of up to 38.40 times, and when the compression factor is 3.31 times, even produced a better performance than the original GPT-2 model.
Private Training Set Inspection in MLaaS
May 15, 2023Machine Learning as a Service (MLaaS) is a popular cloud-based solution for customers who aim to use an ML model but lack training data, computation resources, or expertise in ML. In this case, the training datasets are typically a private possession of the ML or data companies and are inaccessible to the customers, but the customers still need an approach to confirm that the training datasets meet their expectations and fulfil regulatory measures like fairness. However, no existing work addresses the above customers' concerns. This work is the first attempt to solve this problem, taking data origin as an entry point. We first define origin membership measurement and based on this, we then define diversity and fairness metrics to address customers' concerns. We then propose a strategy to estimate the values of these two metrics in the inaccessible training dataset, combining shadow training techniques from membership inference and an efficient featurization scheme in multiple instance learning. The evaluation contains an application of text review polarity classification applications based on the language BERT model. Experimental results show that our solution can achieve up to 0.87 accuracy for membership inspection and up to 99.3% confidence in inspecting diversity and fairness distribution.
Data Provenance Inference in Machine Learning
Nov 24, 2022Unintended memorization of various information granularity has garnered academic attention in recent years, e.g. membership inference and property inference. How to inversely use this privacy leakage to facilitate real-world applications is a growing direction; the current efforts include dataset ownership inference and user auditing. Standing on the data lifecycle and ML model production, we propose an inference process named Data Provenance Inference, which is to infer the generation, collection or processing property of the ML training data, to assist ML developers in locating the training data gaps without maintaining strenuous metadata. We formularly define the data provenance and the data provenance inference task in ML training. Then we propose a novel inference strategy combining embedded-space multiple instance classification and shadow learning. Comprehensive evaluations cover language, visual and structured data in black-box and white-box settings, with diverse kinds of data provenance (i.e. business, county, movie, user). Our best inference accuracy achieves 98.96% in the white-box text model when "author" is the data provenance. The experimental results indicate that, in general, the inference performance positively correlated with the amount of reference data for inference, the depth and also the amount of the parameter of the accessed layer. Furthermore, we give a post-hoc statistical analysis of the data provenance definition to explain when our proposed method works well.