 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry is All You Need: A Unified Taxonomy of Matrix and Tensor Factorization for Compression of Generative Language Models
Oct 03, 2024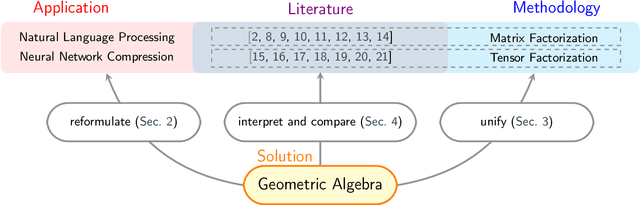

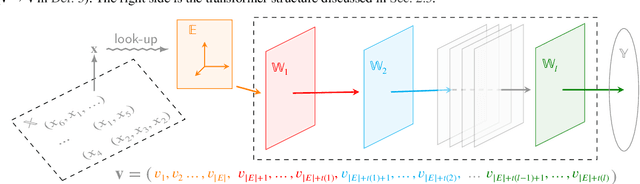
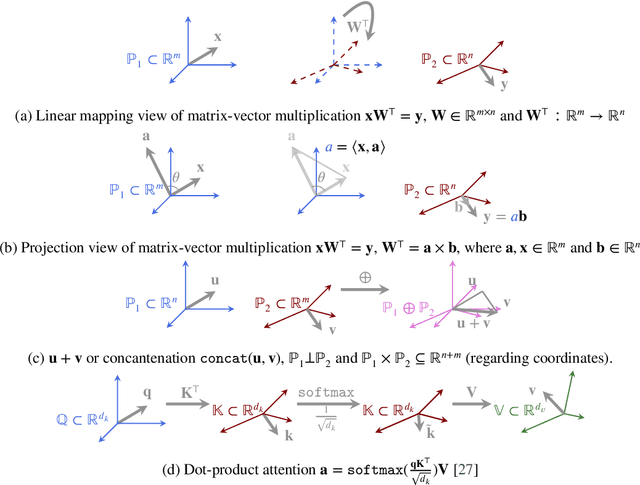
Matrix and tensor-guided parametrization for Natural Language Processing (NLP) models is fundamentally useful for the improvement of the model's systematic efficiency. However, the internal links between these two algebra structures and language model parametrization are poorly understood. Also, the existing matrix and tensor research is math-heavy and far away from machine learning (ML) and NLP research concepts. These two issues result in the recent progress on matrices and tensors for model parametrization being more like a loose collection of separate components from matrix/tensor and NLP studies, rather than a well-structured unified approach, further hindering algorithm design. To this end, we propose a unified taxonomy, which bridges the matrix/tensor compression approaches and model compression concepts in ML and NLP research. Namely, we adopt an elementary concept in linear algebra, that of a subspace, which is also the core concept in geometric algebra, to reformulate the matrix/tensor and ML/NLP concepts (e.g. attention mechanism) under one umbrella. In this way, based on our subspace formalization, typical matrix and tensor decomposition algorithms can be interpreted as geometric transformations. Finally, we revisit recent literature on matrix- or tensor-guided language model compression, rephrase and compare their core ideas, and then point out the current research gap and potential solutions.