 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKromHC: Manifold-Constrained Hyper-Connections with Kronecker-Product Residual Matrices
Jan 29, 2026The success of Hyper-Connections (HC) in neural networks (NN) has also highlighted issues related to its training instability and restricted scalability. The Manifold-Constrained Hyper-Connections (mHC) mitigate these challenges by projecting the residual connection space onto a Birkhoff polytope, however, it faces two issues: 1) its iterative Sinkhorn-Knopp (SK) algorithm does not always yield exact doubly stochastic residual matrices; 2) mHC incurs a prohibitive $\mathcal{O}(n^3C)$ parameter complexity with $n$ as the width of the residual stream and $C$ as the feature dimension. The recently proposed mHC-lite reparametrizes the residual matrix via the Birkhoff-von-Neumann theorem to guarantee double stochasticity, but also faces a factorial explosion in its parameter complexity, $\mathcal{O} \left( nC \cdot n! \right)$. To address both challenges, we propose \textbf{KromHC}, which uses the \underline{Kro}necker products of smaller doubly stochastic matrices to parametrize the residual matrix in \underline{mHC}. By enforcing manifold constraints across the factor residual matrices along each mode of the tensorized residual stream, KromHC guarantees exact double stochasticity of the residual matrices while reducing parameter complexity to $\mathcal{O}(n^2C)$. Comprehensive experiments demonstrate that KromHC matches or even outperforms state-of-the-art (SOTA) mHC variants, while requiring significantly fewer trainable parameters. The code is available at \texttt{https://github.com/wz1119/KromHC}.
RefineBridge: Generative Bridge Models Improve Financial Forecasting by Foundation Models
Dec 25, 2025


Financial time series forecasting is particularly challenging for transformer-based time series foundation models (TSFMs) due to non-stationarity, heavy-tailed distributions, and high-frequency noise present in data. Low-rank adaptation (LoRA) has become a popular parameter-efficient method for adapting pre-trained TSFMs to downstream data domains. However, it still underperforms in financial data, as it preserves the network architecture and training objective of TSFMs rather than complementing the foundation model. To further enhance TSFMs, we propose a novel refinement module, RefineBridge, built upon a tractable Schrödinger Bridge (SB) generative framework. Given the forecasts of TSFM as generative prior and the observed ground truths as targets, RefineBridge learns context-conditioned stochastic transport maps to improve TSFM predictions, iteratively approaching the ground-truth target from even a low-quality prior. Simulations on multiple financial benchmarks demonstrate that RefineBridge consistently improves the performance of state-of-the-art TSFMs across different prediction horizons.
Domain-Aware Tensor Network Structure Search
May 29, 2025Tensor networks (TNs) provide efficient representations of high-dimensional data, yet identification of the optimal TN structures, the so called tensor network structure search (TN-SS) problem, remains a challenge. Current state-of-the-art (SOTA) algorithms are computationally expensive as they require extensive function evaluations, which is prohibitive for real-world applications. In addition, existing methods ignore valuable domain information inherent in real-world tensor data and lack transparency in their identified TN structures. To this end, we propose a novel TN-SS framework, termed the tnLLM, which incorporates domain information about the data and harnesses the reasoning capabilities of large language models (LLMs) to directly predict suitable TN structures. The proposed framework involves a domain-aware prompting pipeline which instructs the LLM to infer suitable TN structures based on the real-world relationships between tensor modes. In this way, our approach is capable of not only iteratively optimizing the objective function, but also generating domain-aware explanations for the identified structures. Experimental results demonstrate that tnLLM achieves comparable TN-SS objective function values with much fewer function evaluations compared to SOTA algorithms. Furthermore, we demonstrate that the LLM-enabled domain information can be used to find good initializations in the search space for sampling-based SOTA methods to accelerate their convergence while preserving theoretical performance guarantees.
TensorLLM: Tensorising Multi-Head Attention for Enhanced Reasoning and Compression in LLMs
Jan 26, 2025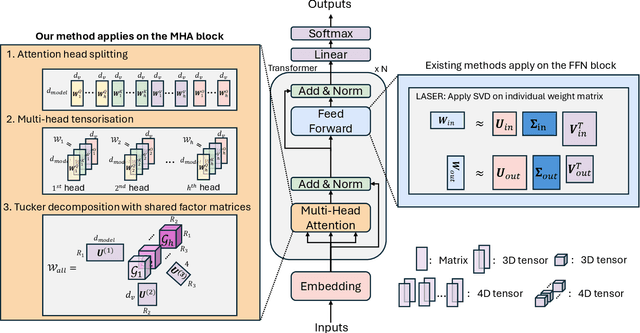
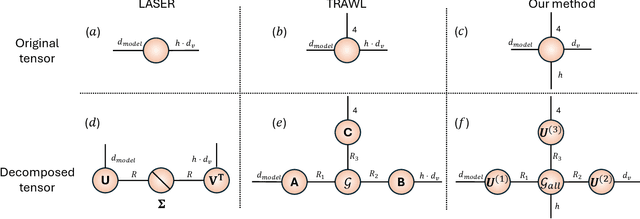

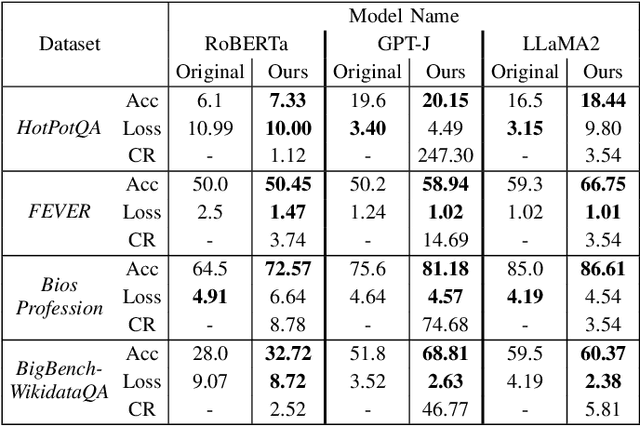
The reasoning abilities of Large Language Models (LLMs) can be improved by structurally denoising their weights, yet existing techniques primarily focus on denoising the feed-forward network (FFN) of the transformer block, and can not efficiently utilise the Multi-head Attention (MHA) block, which is the core of transformer architectures. To address this issue, we propose a novel intuitive framework that, at its very core, performs MHA compression through a multi-head tensorisation process and the Tucker decomposition. This enables both higher-dimensional structured denoising and compression of the MHA weights, by enforcing a shared higher-dimensional subspace across the weights of the multiple attention heads. We demonstrate that this approach consistently enhances the reasoning capabilities of LLMs across multiple benchmark datasets, and for both encoder-only and decoder-only architectures, while achieving compression rates of up to $\sim 250$ times in the MHA weights, all without requiring any additional data, training, or fine-tuning. Furthermore, we show that the proposed method can be seamlessly combined with existing FFN-only-based denoising techniques to achieve further improvements in LLM reasoning performance.
Targeted Angular Reversal of Weights (TARS) for Knowledge Removal in Large Language Models
Dec 13, 2024The sheer scale of data required to train modern large language models (LLMs) poses significant risks, as models are likely to gain knowledge of sensitive topics such as bio-security, as well the ability to replicate copyrighted works. Methods designed to remove such knowledge must do so from all prompt directions, in a multi-lingual capacity and without degrading general model performance. To this end, we introduce the targeted angular reversal (TARS) method of knowledge removal from LLMs. The TARS method firstly leverages the LLM in combination with a detailed prompt to aggregate information about a selected concept in the internal representation space of the LLM. It then refines this approximate concept vector to trigger the concept token with high probability, by perturbing the approximate concept vector with noise and transforming it into token scores with the language model head. The feedforward weight vectors in the LLM which operate directly on the internal representation space, and have the highest cosine similarity with this targeting vector, are then replaced by a reversed targeting vector, thus limiting the ability of the concept to propagate through the model. The modularity of the TARS method allows for a sequential removal of concepts from Llama 3.1 8B, such as the famous literary detective Sherlock Holmes, and the planet Saturn. It is demonstrated that the probability of triggering target concepts can be reduced to 0.00 with as few as 1 TARS edit, whilst simultaneously removing the knowledge bi-directionally. Moreover, knowledge is shown to be removed across all languages despite only being targeted in English. Importantly, TARS has minimal impact on the general model capabilities, as after removing 5 diverse concepts in a modular fashion, there is minimal KL divergence in the next token probabilities of the LLM on large corpora of Wikipedia text (median of 0.002).
Towards LLM-guided Efficient and Interpretable Multi-linear Tensor Network Rank Selection
Oct 14, 2024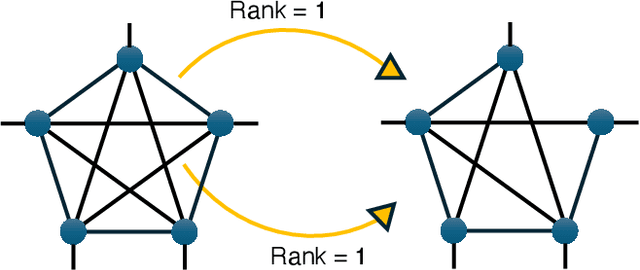
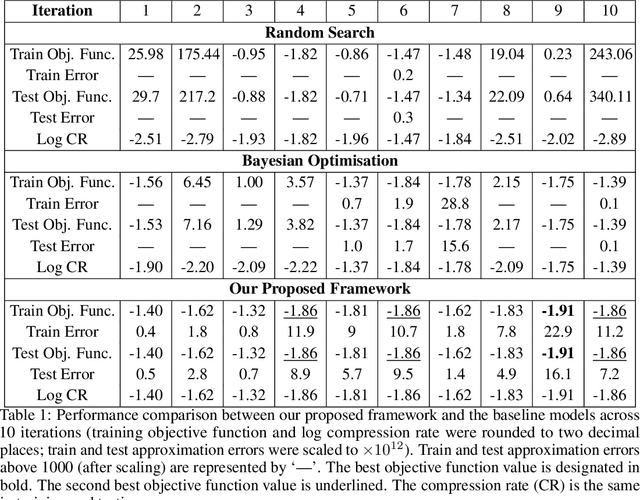
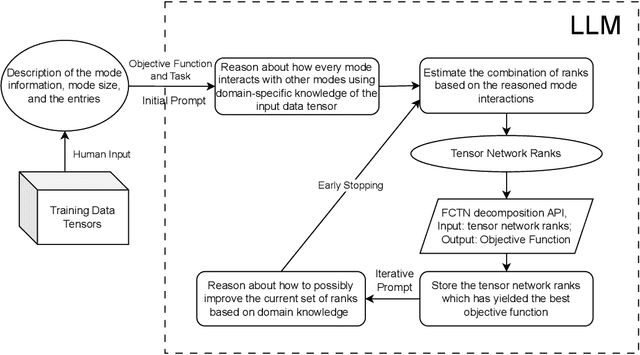
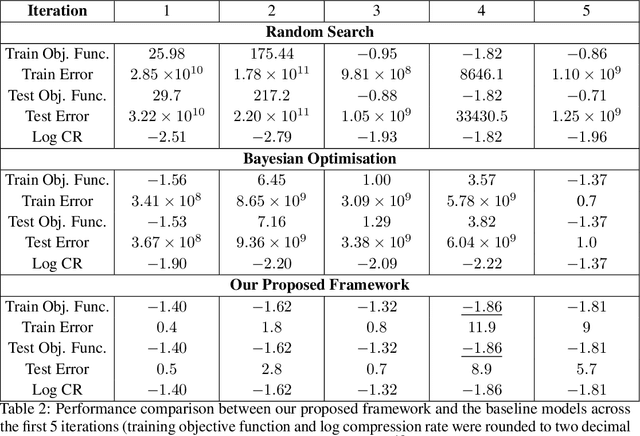
We propose a novel framework that leverages large language models (LLMs) to guide the rank selection in tensor network models for higher-order data analysis. By utilising the intrinsic reasoning capabilities and domain knowledge of LLMs, our approach offers enhanced interpretability of the rank choices and can effectively optimise the objective function. This framework enables users without specialised domain expertise to utilise tensor network decompositions and understand the underlying rationale within the rank selection process. Experimental results validate our method on financial higher-order datasets, demonstrating interpretable reasoning, strong generalisation to unseen test data, and its potential for self-enhancement over successive iterations. This work is placed at the intersection of large language models and higher-order data analysis.
FinLlama: Financial Sentiment Classification for Algorithmic Trading Applications
Mar 18, 2024
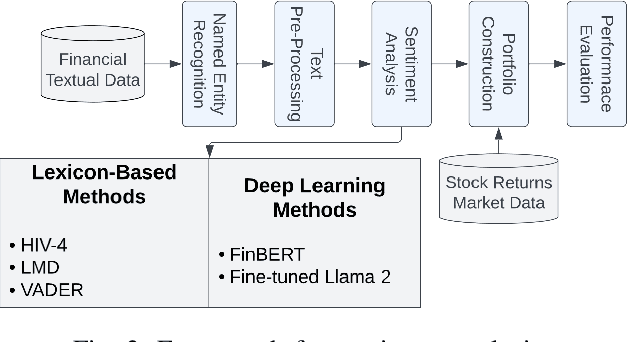
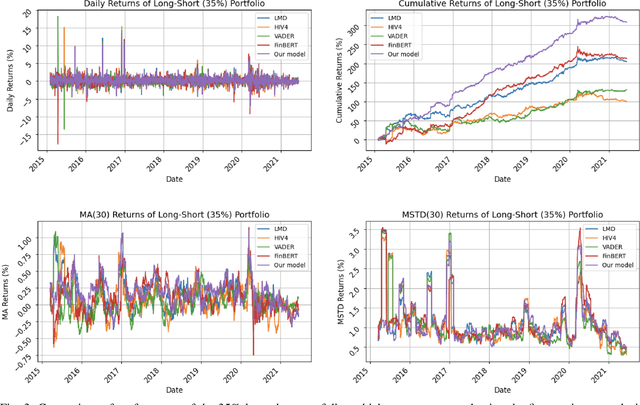

There are multiple sources of financial news online which influence market movements and trader's decisions. This highlights the need for accurate sentiment analysis, in addition to having appropriate algorithmic trading techniques, to arrive at better informed trading decisions. Standard lexicon based sentiment approaches have demonstrated their power in aiding financial decisions. However, they are known to suffer from issues related to context sensitivity and word ordering. Large Language Models (LLMs) can also be used in this context, but they are not finance-specific and tend to require significant computational resources. To facilitate a finance specific LLM framework, we introduce a novel approach based on the Llama 2 7B foundational model, in order to benefit from its generative nature and comprehensive language manipulation. This is achieved by fine-tuning the Llama2 7B model on a small portion of supervised financial sentiment analysis data, so as to jointly handle the complexities of financial lexicon and context, and further equipping it with a neural network based decision mechanism. Such a generator-classifier scheme, referred to as FinLlama, is trained not only to classify the sentiment valence but also quantify its strength, thus offering traders a nuanced insight into financial news articles. Complementing this, the implementation of parameter-efficient fine-tuning through LoRA optimises trainable parameters, thus minimising computational and memory requirements, without sacrificing accuracy. Simulation results demonstrate the ability of the proposed FinLlama to provide a framework for enhanced portfolio management decisions and increased market returns. These results underpin the ability of FinLlama to construct high-return portfolios which exhibit enhanced resilience, even during volatile periods and unpredictable market events.