 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Angular Reversal of Weights (TARS) for Knowledge Removal in Large Language Models
Dec 13, 2024The sheer scale of data required to train modern large language models (LLMs) poses significant risks, as models are likely to gain knowledge of sensitive topics such as bio-security, as well the ability to replicate copyrighted works. Methods designed to remove such knowledge must do so from all prompt directions, in a multi-lingual capacity and without degrading general model performance. To this end, we introduce the targeted angular reversal (TARS) method of knowledge removal from LLMs. The TARS method firstly leverages the LLM in combination with a detailed prompt to aggregate information about a selected concept in the internal representation space of the LLM. It then refines this approximate concept vector to trigger the concept token with high probability, by perturbing the approximate concept vector with noise and transforming it into token scores with the language model head. The feedforward weight vectors in the LLM which operate directly on the internal representation space, and have the highest cosine similarity with this targeting vector, are then replaced by a reversed targeting vector, thus limiting the ability of the concept to propagate through the model. The modularity of the TARS method allows for a sequential removal of concepts from Llama 3.1 8B, such as the famous literary detective Sherlock Holmes, and the planet Saturn. It is demonstrated that the probability of triggering target concepts can be reduced to 0.00 with as few as 1 TARS edit, whilst simultaneously removing the knowledge bi-directionally. Moreover, knowledge is shown to be removed across all languages despite only being targeted in English. Importantly, TARS has minimal impact on the general model capabilities, as after removing 5 diverse concepts in a modular fashion, there is minimal KL divergence in the next token probabilities of the LLM on large corpora of Wikipedia text (median of 0.002).
In-ear ECG Signal Enhancement with Denoising Convolutional Autoencoders
Aug 27, 2024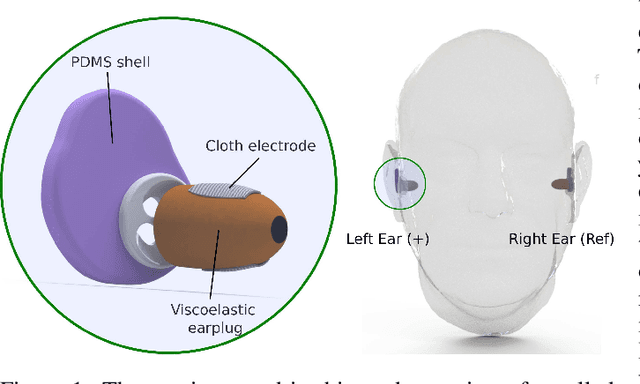
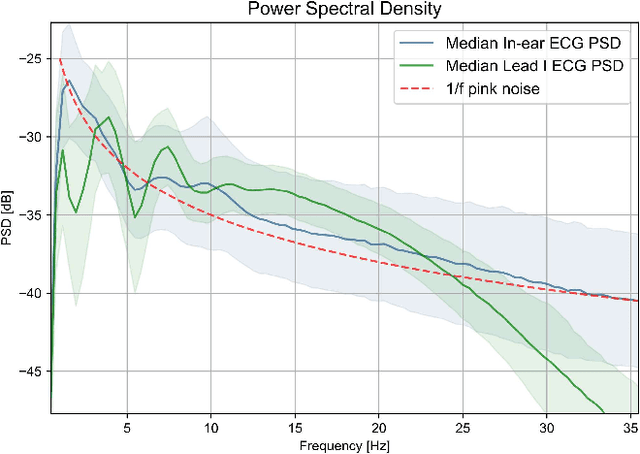
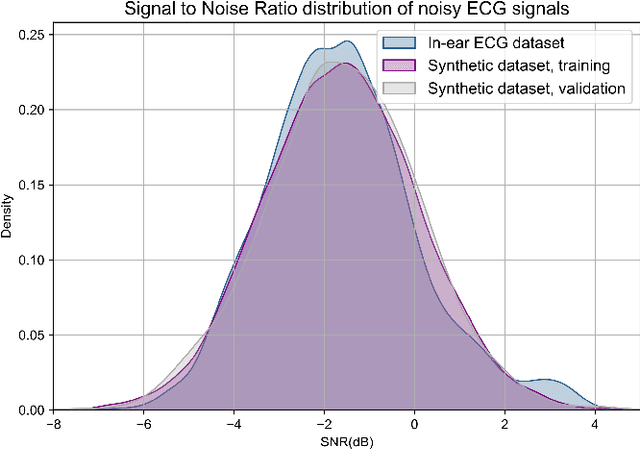
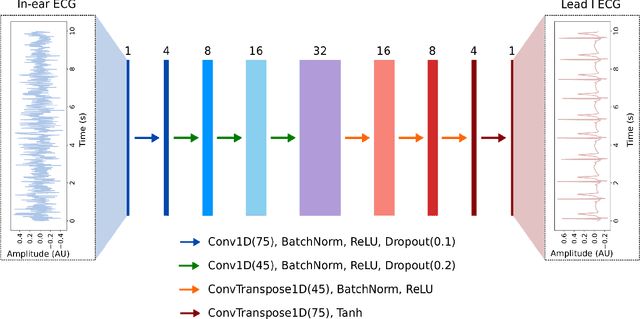
The cardiac dipole has been shown to propagate to the ears, now a common site for consumer wearable electronics, enabling the recording of electrocardiogram (ECG) signals. However, in-ear ECG recordings often suffer from significant noise due to their small amplitude and the presence of other physiological signals, such as electroencephalogram (EEG), which complicates the extraction of cardiovascular features. This study addresses this issue by developing a denoising convolutional autoencoder (DCAE) to enhance ECG information from in-ear recordings, producing cleaner ECG outputs. The model is evaluated using a dataset of in-ear ECGs and corresponding clean Lead I ECGs from 45 healthy participants. The results demonstrate a substantial improvement in signal-to-noise ratio (SNR), with a median increase of 5.9 dB. Additionally, the model significantly improved heart rate estimation accuracy, reducing the mean absolute error by almost 70% and increasing R-peak detection precision to a median value of 90%. We also trained and validated the model using a synthetic dataset, generated from real ECG signals, including abnormal cardiac morphologies, corrupted by pink noise. The results obtained show effective removal of noise sources with clinically plausible waveform reconstruction ability.
Interpretable Pre-Trained Transformers for Heart Time-Series Data
Jul 30, 2024Decoder-only transformers are the backbone of the popular generative pre-trained transformer (GPT) series of large language models. In this work, we apply the same framework to periodic heart time-series data to create two pre-trained general purpose cardiac models, namely PPG-PT and ECG-PT. We demonstrate that both such pre-trained models are fully interpretable. This is achieved firstly through aggregate attention maps which show that the model focuses on similar points in previous cardiac cycles in order to make predictions and gradually broadens its attention in deeper layers. Next, tokens with the same value, that occur at different distinct points in the ECG and PPG cycle, form separate clusters in high dimensional space based on their phase as they propagate through the transformer blocks. Finally, we highlight that individual attention heads respond to specific physiologically relevent features, such as the dicrotic notch in PPG and the P-wave in ECG. It is also demonstrated that these pre-trained models can be easily fine-tuned for tasks such as classification of atrial fibrillation. In this specific example, the fine-tuning took 11 minutes of computer time, and achieved a leave-one-subject-out AUCs of 0.99 and 0.93 for ECG and PPG respectively. Importantly, these fine-tuned models are also fully explainable, with attention shifting to regions in the context that are strongly indicative of atrial fibrillation.
A Deep Matched Filter For R-Peak Detection in Ear-ECG
May 23, 2023The Ear-ECG provides a continuous Lead I electrocardiogram (ECG) by measuring the potential difference related to heart activity using electrodes that can be embedded within earphones. The significant increase in wearability and comfort afforded by Ear-ECG is often accompanied by a corresponding degradation in signal quality - a common obstacle that is shared by most wearable technologies. We aim to resolve this issue by introducing a Deep Matched Filter (Deep-MF) for the highly accurate detection of R-peaks in wearable ECG, thus enhancing the utility of Ear-ECG in real-world scenarios. The Deep-MF consists of an encoder stage (trained as part of an encoder-decoder module to reproduce ground truth ECG), and an R-peak classifier stage. Through its operation as a Matched Filter, the encoder searches for matches with an ECG template pattern in the input signal, prior to filtering the matches with the subsequent convolutional layers and selecting peaks corresponding to true ECG matches. The so condensed latent representation of R-peak information is then fed into a simple R-peak classifier, of which the output provides precise R-peak locations. The proposed Deep Matched Filter is evaluated using leave-one-subject-out cross validation over 36 subjects with an age range of 18-75, with the Deep-MF outperforming existing algorithms for R-peak detection in noisy ECG. The Deep-MF achieves a median R-peak recall of 94.9\%, a median precision of 91.2\% and an (AUC) value of 0.97. Furthermore, we demonstrate that the Deep Matched Filter algorithm not only retains the initialised ECG kernel structure during the training process, but also amplifies portions of the ECG which it deems most valuable. Overall, the Deep Matched Filter serves as a valuable step forward for the real-world functionality of Ear-ECG and, through its explainable operation, the acceptance of deep learning models in e-health.
Amplitude-Independent Machine Learning for PPG through Visibility Graphs and Transfer Learning
May 23, 2023



Photoplethysmography (PPG) signals are omnipresent in wearable devices, as they measure blood volume variations using LED technology. These signals provide insight into the body's circulatory system and can be employed to extract various bio-features, such as heart rate and vascular ageing. Although several algorithms have been proposed for this purpose, many exhibit limitations, including heavy reliance on human calibration, high signal quality requirements, and a lack of generalization. In this paper, we introduce a PPG signal processing framework that integrates graph theory and computer vision algorithms, which is invariant to affine transformations, offers rapid computation speed, and exhibits robust generalization across tasks and datasets.
Rapid Extraction of Respiratory Waveforms from Photoplethysmography: A Deep Encoder Approach
Dec 22, 2022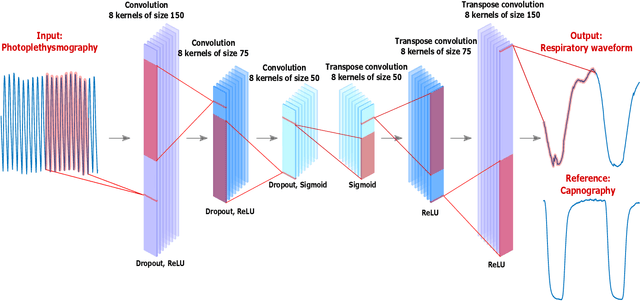
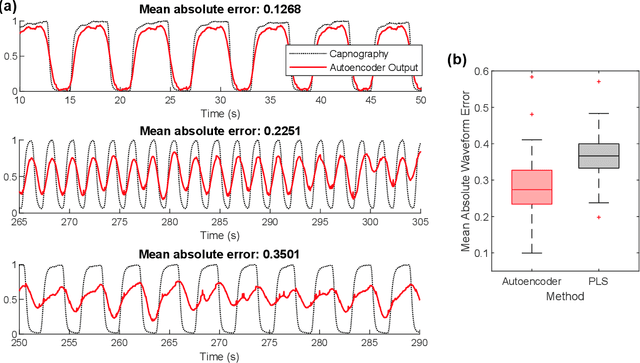
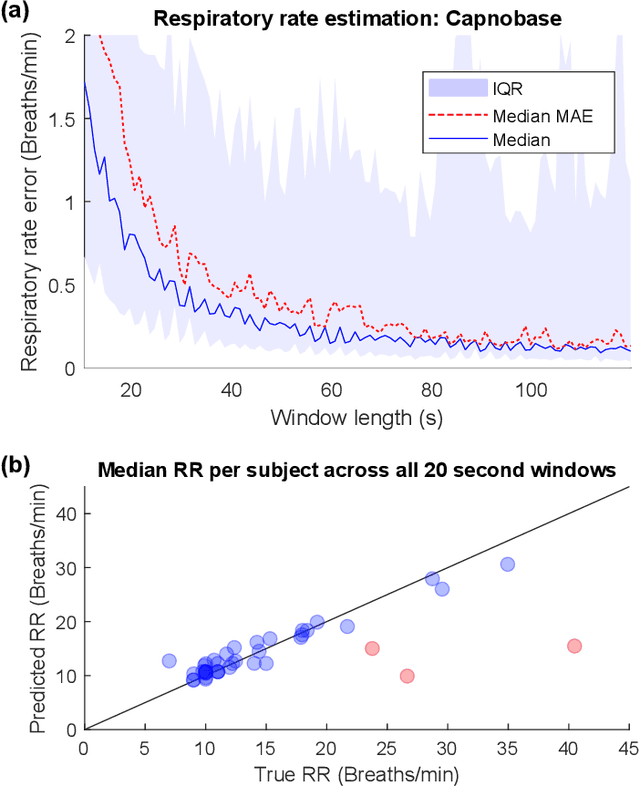

Much of the information of breathing is contained within the photoplethysmography (PPG) signal, through changes in venous blood flow, heart rate and stroke volume. We aim to leverage this fact, by employing a novel deep learning framework which is a based on a repurposed convolutional autoencoder. Our model aims to encode all of the relevant respiratory information contained within photoplethysmography waveform, and decode it into a waveform that is similar to a gold standard respiratory reference. The model is employed on two photoplethysmography data sets, namely Capnobase and BIDMC. We show that the model is capable of producing respiratory waveforms that approach the gold standard, while in turn producing state of the art respiratory rate estimates. We also show that when it comes to capturing more advanced respiratory waveform characteristics such as duty cycle, our model is for the most part unsuccessful. A suggested reason for this, in light of a previous study on in-ear PPG, is that the respiratory variations in finger-PPG are far weaker compared with other recording locations. Importantly, our model can perform these waveform estimates in a fraction of a millisecond, giving it the capacity to produce over 6 hours of respiratory waveforms in a single second. Moreover, we attempt to interpret the behaviour of the kernel weights within the model, showing that in part our model intuitively selects different breathing frequencies. The model proposed in this work could help to improve the usefulness of consumer PPG-based wearables for medical applications, where detailed respiratory information is required.
An Apparatus for the Simulation of Breathing Disorders: Physically Meaningful Generation of Surrogate Data
Sep 14, 2021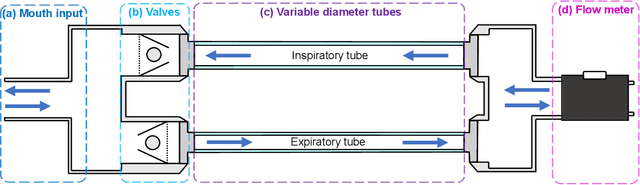
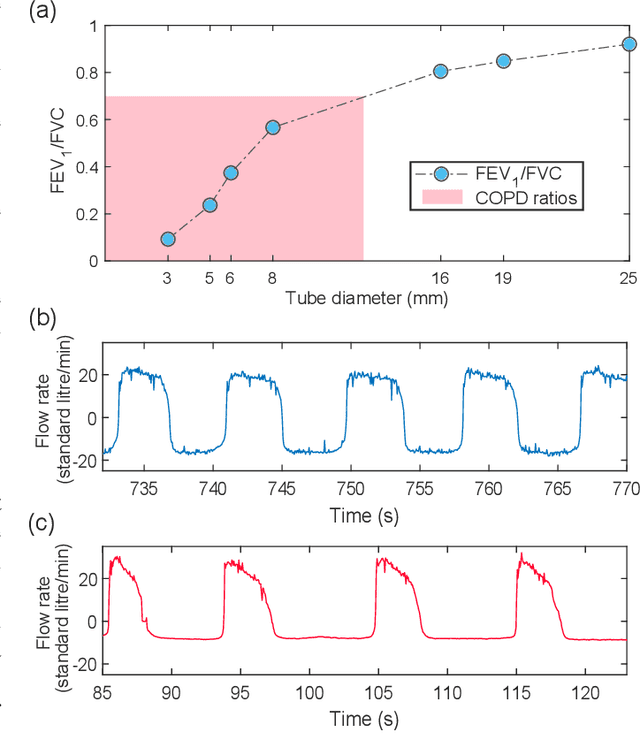
Whilst debilitating breathing disorders, such as chronic obstructive pulmonary disease (COPD), are rapidly increasing in prevalence, we witness a continued integration of artificial intelligence into healthcare. While this promises improved detection and monitoring of breathing disorders, AI techniques are "data hungry" which highlights the importance of generating physically meaningful surrogate data. Such domain knowledge aware surrogates would enable both an improved understanding of respiratory waveform changes with different breathing disorders and different severities, and enhance the training of machine learning algorithms. To this end, we introduce an apparatus comprising of PVC tubes and 3D printed parts as a simple yet effective method of simulating both obstructive and restrictive respiratory waveforms in healthy subjects. Independent control over both inspiratory and expiratory resistances allows for the simulation of obstructive breathing disorders through the whole spectrum of FEV1/FVC spirometry ratios (used to classify COPD), ranging from healthy values to values seen in severe chronic obstructive pulmonary disease. Moreover, waveform characteristics of breathing disorders, such as a change in inspiratory duty cycle or peak flow are also observed in the waveforms resulting from use of the artificial breathing disorder simulation apparatus. Overall, the proposed apparatus provides us with a simple, effective and physically meaningful way to generate surrogate breathing disorder waveforms, a prerequisite for the use of artificial intelligence in respiratory health.
In-Ear SpO2 for Classification of Cognitive Workload
Jan 03, 2021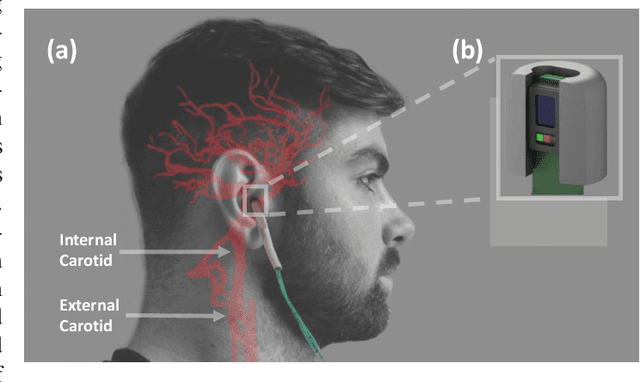
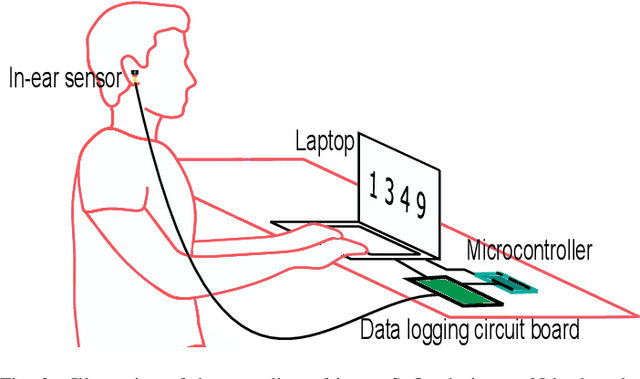
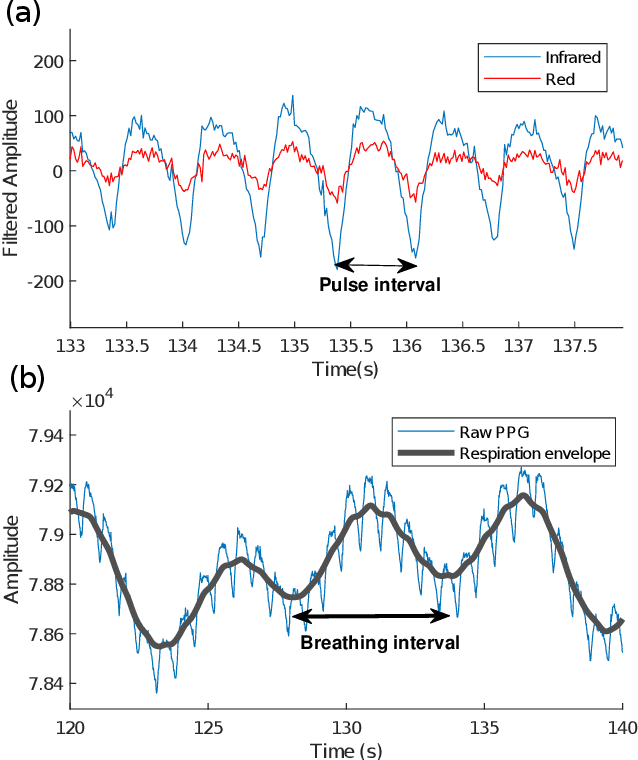
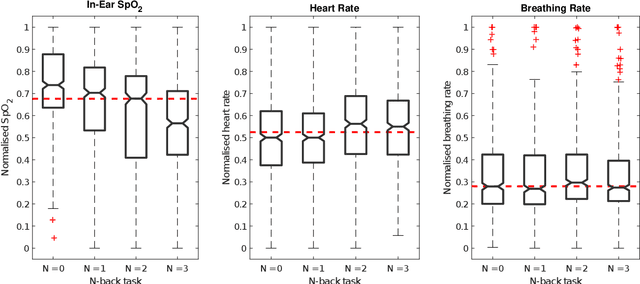
Classification of cognitive workload promises immense benefit in diverse areas ranging from driver safety to augmenting human capability through closed loop brain computer interface. The brain is the most metabolically active organ in the body and increases its metabolic activity and thus oxygen consumption with increasing cognitive demand. In this study, we explore the feasibility of in-ear SpO2 cognitive workload tracking. To this end, we preform cognitive workload assessment in 8 subjects, based on an N-back task, whereby the subjects are asked to count and remember the number of odd numbers displayed on a screen in 5 second windows. The 2 and 3-back tasks lead to either the lowest median absolute SpO2 or largest median decrease in SpO2 in all of the subjects, indicating a robust and measurable decrease in blood oxygen in response to increased cognitive workload. Using features derived from in-ear pulse oximetry, including SpO2, pulse rate and respiration rate, we were able to classify the 4 N-back task categories, over 5 second epochs, with a mean accuracy of 94.2%. Moreover, out of 21 total features, the 9 most important features for classification accuracy were all SpO2 related features. The findings suggest that in-ear SpO2 measurements provide valuable information for classification of cognitive workload over short time windows, which together with the small form factor promises a new avenue for real time cognitive workload tracking.