 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorLLM: Tensorising Multi-Head Attention for Enhanced Reasoning and Compression in LLMs
Paper and Code
Jan 26, 2025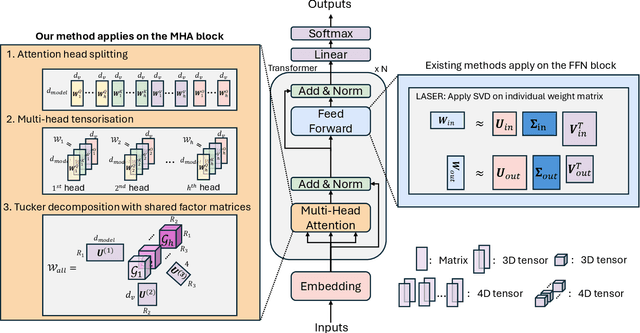
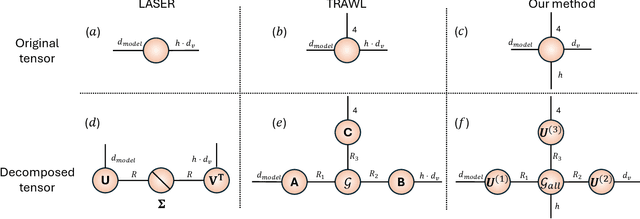

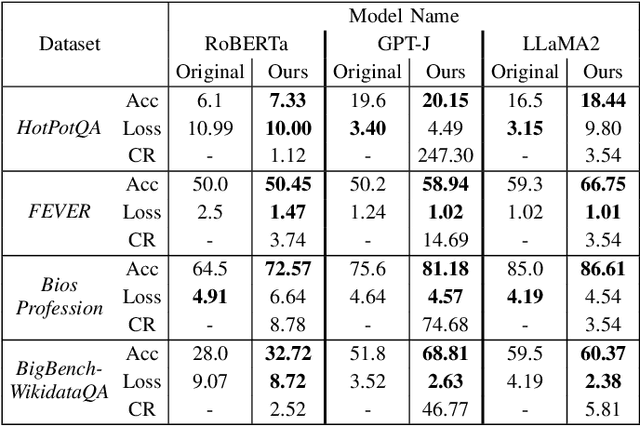
The reasoning abilities of Large Language Models (LLMs) can be improved by structurally denoising their weights, yet existing techniques primarily focus on denoising the feed-forward network (FFN) of the transformer block, and can not efficiently utilise the Multi-head Attention (MHA) block, which is the core of transformer architectures. To address this issue, we propose a novel intuitive framework that, at its very core, performs MHA compression through a multi-head tensorisation process and the Tucker decomposition. This enables both higher-dimensional structured denoising and compression of the MHA weights, by enforcing a shared higher-dimensional subspace across the weights of the multiple attention heads. We demonstrate that this approach consistently enhances the reasoning capabilities of LLMs across multiple benchmark datasets, and for both encoder-only and decoder-only architectures, while achieving compression rates of up to $\sim 250$ times in the MHA weights, all without requiring any additional data, training, or fine-tuning. Furthermore, we show that the proposed method can be seamlessly combined with existing FFN-only-based denoising techniques to achieve further improvements in LLM reasoning performance.