 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapture the Flags: Family-Based Evaluation of Agentic LLMs via Semantics-Preserving Transformations
Feb 05, 2026Agentic large language models (LLMs) are increasingly evaluated on cybersecurity tasks using capture-the-flag (CTF) benchmarks. However, existing pointwise benchmarks have limited ability to shed light on the robustness and generalisation abilities of agents across alternative versions of the source code. We introduce CTF challenge families, whereby a single CTF is used as the basis for generating a family of semantically-equivalent challenges via semantics-preserving program transformations. This enables controlled evaluation of agent robustness to source code transformations while keeping the underlying exploit strategy fixed. We introduce a new tool, Evolve-CTF, that generates CTF families from Python challenges using a range of transformations. Using Evolve-CTF to derive families from Cybench and Intercode challenges, we evaluate 13 agentic LLM configurations with tool access. We find that models are remarkably robust to intrusive renaming and code insertion-based transformations, but that composed transformations and deeper obfuscation affect performance by requiring more sophisticated use of tools. We also find that enabling explicit reasoning has little effect on solution success rates across challenge families. Our work contributes a valuable technique and tool for future LLM evaluations, and a large dataset characterising the capabilities of current state-of-the-art models in this domain.
Enhancing LLM Robustness to Perturbed Instructions: An Empirical Study
Apr 03, 2025Large Language Models (LLMs) are highly vulnerable to input perturbations, as even a small prompt change may result in a substantially different output. Existing methods to enhance LLM robustness are primarily focused on perturbed data samples, whereas improving resiliency to perturbations of task-level instructions has remained relatively underexplored. In this work, we focus on character- and word-level edits of task-specific instructions, which substantially degrade downstream performance. We experiment with a variety of techniques to enhance the robustness of LLMs, including self-denoising and representation alignment, testing different models (Llama 3 and Flan-T5), datasets (CoLA, QNLI, SST-2) and instructions (both task-oriented and role-oriented). We find that, on average, self-denoising -- whether performed by a frozen LLM or a fine-tuned model -- achieves substantially higher performance gains than alternative strategies, including more complex baselines such as ensembling and supervised methods.
Turbulence: Systematically and Automatically Testing Instruction-Tuned Large Language Models for Code
Jan 14, 2024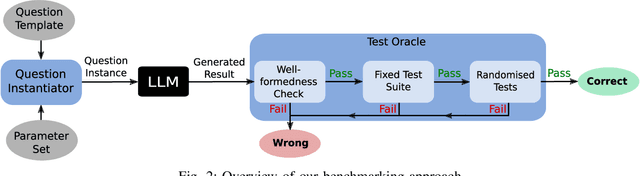
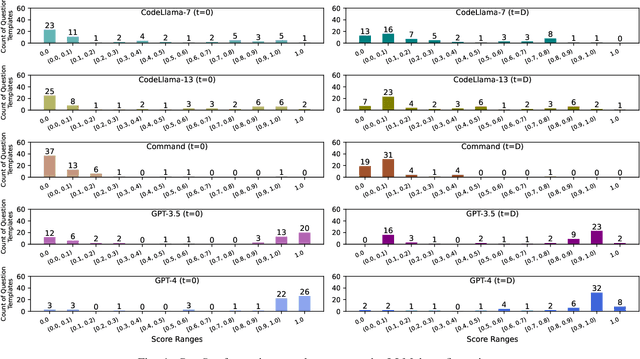

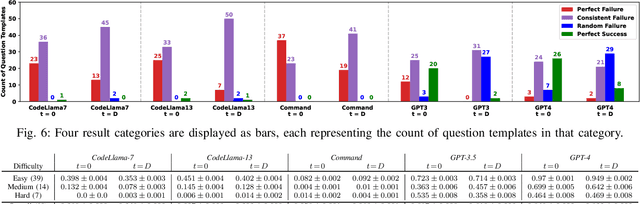
We present a method for systematically evaluating the correctness and robustness of instruction-tuned large language models (LLMs) for code generation via a new benchmark, Turbulence. Turbulence consists of a large set of natural language $\textit{question templates}$, each of which is a programming problem, parameterised so that it can be asked in many different forms. Each question template has an associated $\textit{test oracle}$ that judges whether a code solution returned by an LLM is correct. Thus, from a single question template, it is possible to ask an LLM a $\textit{neighbourhood}$ of very similar programming questions, and assess the correctness of the result returned for each question. This allows gaps in an LLM's code generation abilities to be identified, including $\textit{anomalies}$ where the LLM correctly solves $\textit{almost all}$ questions in a neighbourhood but fails for particular parameter instantiations. We present experiments against five LLMs from OpenAI, Cohere and Meta, each at two temperature configurations. Our findings show that, across the board, Turbulence is able to reveal gaps in LLM reasoning ability. This goes beyond merely highlighting that LLMs sometimes produce wrong code (which is no surprise): by systematically identifying cases where LLMs are able to solve some problems in a neighbourhood but do not manage to generalise to solve the whole neighbourhood, our method is effective at highlighting $\textit{robustness}$ issues. We present data and examples that shed light on the kinds of mistakes that LLMs make when they return incorrect code results.