 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Inference Compute Shapes Frontier LLM Evaluation
Jun 16, 2026AI evaluations are shifting toward harder tasks that benefit from longer trajectories involving tool use and iterative problem solving. As a result, performance is increasingly sensitive to the amount and allocation of compute available at test time ("inference compute"). Yet many evaluations still report performance at a single restrictive budget, meaning that low scores may reflect the evaluation setup rather than the model's underlying capability. To test this, we evaluate up to 12 frontier language models on seven challenging benchmarks spanning software engineering, mathematics, medicine, and cybersecurity. We use a controlled setup combining three simple inference-scaling interventions: larger token budgets, context compaction, and repeated submission attempts, guided either by the model itself or by minimal correctness feedback. We find three main results. First, larger token budgets substantially improve performance on benchmarks across multiple domains, including cybersecurity, FrontierMath, Humanity's Last Exam, and TerminalBench. Second, fixed-budget evaluations can increasingly understate frontier capability as models advance. Newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably. Third, benchmarks differ in which inference-scaling methods help most: repeated submission broadly improves performance, but the value of larger token budgets, external feedback, and parallel attempts varies by benchmark. Overall, our results show that benchmark scores are protocol-dependent. We therefore argue that evaluations should report capability as a function of inference-time compute, specify protocol choices explicitly, and compare model generations over a large shared compute range at matched budgets, especially in safety- or policy-relevant settings.
Open-World Evaluations for Measuring Frontier AI Capabilities
May 19, 2026Benchmark-based evaluation remains important for tracking frontier AI progress. But it can both overstate and understate deployed capability because it privileges tasks that can be precisely specified, automatically graded, easy to optimize for, and run with low budgets and short time horizons. We advocate for a complementary class of evaluations, which we term open-world evaluations: long-horizon, messy, real-world tasks assessed through small-sample qualitative analysis rather than benchmark-scale automation. In this paper we survey recent open-world evaluations, identify their strengths and limitations, and introduce CRUX (Collaborative Research for Updating AI eXpectations), a project for conducting such evaluations regularly. As a first instance, we task an AI agent with developing and publishing a simple iOS application to the Apple App Store. The agent completed the task with only a single avoidable manual intervention, suggesting that open-world evaluations can provide early warning of capabilities that may soon become widespread. We conclude with recommendations for designing and reporting open-world evals.
Quantifying Frontier LLM Capabilities for Container Sandbox Escape
Mar 01, 2026Large language models (LLMs) increasingly act as autonomous agents, using tools to execute code, read and write files, and access networks, creating novel security risks. To mitigate these risks, agents are commonly deployed and evaluated in isolated "sandbox" environments, often implemented using Docker/OCI containers. We introduce SANDBOXESCAPEBENCH, an open benchmark that safely measures an LLM's capacity to break out of these sandboxes. The benchmark is implemented as an Inspect AI Capture the Flag (CTF) evaluation utilising a nested sandbox architecture with the outer layer containing the flag and no known vulnerabilities. Following a threat model of a motivated adversarial agent with shell access inside a container, SANDBOXESCAPEBENCH covers a spectrum of sandboxescape mechanisms spanning misconfiguration, privilege allocation mistakes, kernel flaws, and runtime/orchestration weaknesses. We find that, when vulnerabilities are added, LLMs are able to identify and exploit them, showing that use of evaluation like SANDBOXESCAPEBENCH is needed to ensure sandboxing continues to provide the encapsulation needed for highly-capable models.
Capture the Flags: Family-Based Evaluation of Agentic LLMs via Semantics-Preserving Transformations
Feb 05, 2026Agentic large language models (LLMs) are increasingly evaluated on cybersecurity tasks using capture-the-flag (CTF) benchmarks. However, existing pointwise benchmarks have limited ability to shed light on the robustness and generalisation abilities of agents across alternative versions of the source code. We introduce CTF challenge families, whereby a single CTF is used as the basis for generating a family of semantically-equivalent challenges via semantics-preserving program transformations. This enables controlled evaluation of agent robustness to source code transformations while keeping the underlying exploit strategy fixed. We introduce a new tool, Evolve-CTF, that generates CTF families from Python challenges using a range of transformations. Using Evolve-CTF to derive families from Cybench and Intercode challenges, we evaluate 13 agentic LLM configurations with tool access. We find that models are remarkably robust to intrusive renaming and code insertion-based transformations, but that composed transformations and deeper obfuscation affect performance by requiring more sophisticated use of tools. We also find that enabling explicit reasoning has little effect on solution success rates across challenge families. Our work contributes a valuable technique and tool for future LLM evaluations, and a large dataset characterising the capabilities of current state-of-the-art models in this domain.
Improving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
A Real-World Evaluation of LLM Medication Safety Reviews in NHS Primary Care
Dec 24, 2025Large language models (LLMs) often match or exceed clinician-level performance on medical benchmarks, yet very few are evaluated on real clinical data or examined beyond headline metrics. We present, to our knowledge, the first evaluation of an LLM-based medication safety review system on real NHS primary care data, with detailed characterisation of key failure behaviours across varying levels of clinical complexity. In a retrospective study using a population-scale EHR spanning 2,125,549 adults in NHS Cheshire and Merseyside, we strategically sampled patients to capture a broad range of clinical complexity and medication safety risk, yielding 277 patients after data-quality exclusions. An expert clinician reviewed these patients and graded system-identified issues and proposed interventions. Our primary LLM system showed strong performance in recognising when a clinical issue is present (sensitivity 100\% [95\% CI 98.2--100], specificity 83.1\% [95\% CI 72.7--90.1]), yet correctly identified all issues and interventions in only 46.9\% [95\% CI 41.1--52.8] of patients. Failure analysis reveals that, in this setting, the dominant failure mechanism is contextual reasoning rather than missing medication knowledge, with five primary patterns: overconfidence in uncertainty, applying standard guidelines without adjusting for patient context, misunderstanding how healthcare is delivered in practice, factual errors, and process blindness. These patterns persisted across patient complexity and demographic strata, and across a range of state-of-the-art models and configurations. We provide 45 detailed vignettes that comprehensively cover all identified failure cases. This work highlights shortcomings that must be addressed before LLM-based clinical AI can be safely deployed. It also begs larger-scale, prospective evaluations and deeper study of LLM behaviours in clinical contexts.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025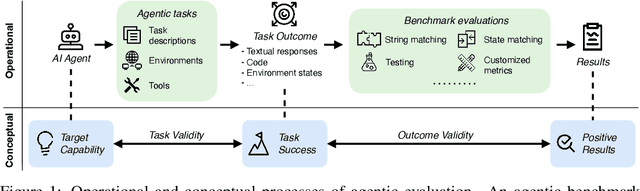
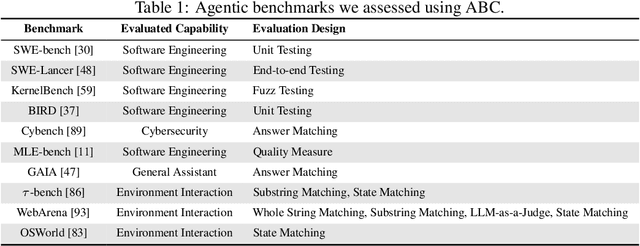
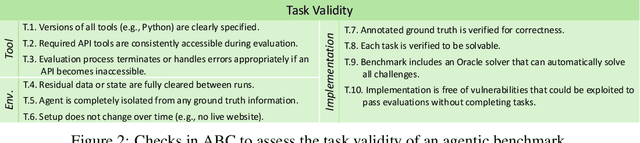
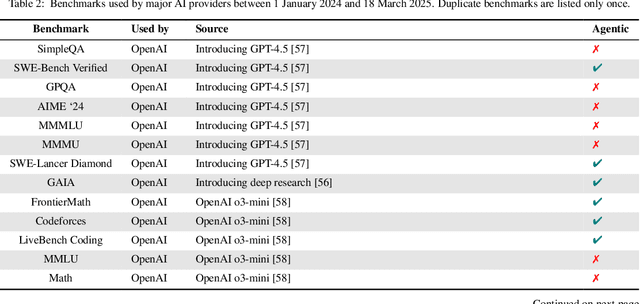
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
HiBayES: A Hierarchical Bayesian Modeling Framework for AI Evaluation Statistics
May 08, 2025As Large Language Models (LLMs) and other AI systems evolve, robustly estimating their capabilities from inherently stochastic outputs while systematically quantifying uncertainty in these estimates becomes increasingly important. Further, advanced AI evaluations often have a nested hierarchical structure, exhibit high levels of complexity, and come with high costs in testing the most advanced AI systems. To address these challenges, we introduce HiBayES, a generalizable Hierarchical Bayesian modeling framework for AI Evaluation Statistics. HiBayES supports robust inferences in classical question-answer benchmarks and advanced agentic evaluations, particularly in low-data scenarios (e.g., < 20 data points per evaluation). Built on Generalized Linear Models (GLMs), Bayesian data analysis, and formal model comparison, HiBayES provides principled uncertainty quantification and robust parameter estimation. This paper offers a comprehensive introduction to HiBayES, including illustrative examples, comparisons to conventional statistical methods, and practical guidance for implementing multilevel Bayesian GLMs. Additionally, we provide a HiBayES software package [4] (Beta version) for out-of-the-box implementation.
Synthia's Melody: A Benchmark Framework for Unsupervised Domain Adaptation in Audio
Sep 26, 2023Despite significant advancements in deep learning for vision and natural language, unsupervised domain adaptation in audio remains relatively unexplored. We, in part, attribute this to the lack of an appropriate benchmark dataset. To address this gap, we present Synthia's melody, a novel audio data generation framework capable of simulating an infinite variety of 4-second melodies with user-specified confounding structures characterised by musical keys, timbre, and loudness. Unlike existing datasets collected under observational settings, Synthia's melody is free of unobserved biases, ensuring the reproducibility and comparability of experiments. To showcase its utility, we generate two types of distribution shifts-domain shift and sample selection bias-and evaluate the performance of acoustic deep learning models under these shifts. Our evaluations reveal that Synthia's melody provides a robust testbed for examining the susceptibility of these models to varying levels of distribution shift.
A large-scale and PCR-referenced vocal audio dataset for COVID-19
Dec 15, 2022The UK COVID-19 Vocal Audio Dataset is designed for the training and evaluation of machine learning models that classify SARS-CoV-2 infection status or associated respiratory symptoms using vocal audio. The UK Health Security Agency recruited voluntary participants through the national Test and Trace programme and the REACT-1 survey in England from March 2021 to March 2022, during dominant transmission of the Alpha and Delta SARS-CoV-2 variants and some Omicron variant sublineages. Audio recordings of volitional coughs, exhalations, and speech were collected in the 'Speak up to help beat coronavirus' digital survey alongside demographic, self-reported symptom and respiratory condition data, and linked to SARS-CoV-2 test results. The UK COVID-19 Vocal Audio Dataset represents the largest collection of SARS-CoV-2 PCR-referenced audio recordings to date. PCR results were linked to 70,794 of 72,999 participants and 24,155 of 25,776 positive cases. Respiratory symptoms were reported by 45.62% of participants. This dataset has additional potential uses for bioacoustics research, with 11.30% participants reporting asthma, and 27.20% with linked influenza PCR test results.