 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Invariance and Allocation: When Subgroup Balance Matters
Dec 10, 2025Unequal representation of demographic groups in training data poses challenges to model generalisation across populations. Standard practice assumes that balancing subgroup representation optimises performance. However, recent empirical results contradict this assumption: in some cases, imbalanced data distributions actually improve subgroup performance, while in others, subgroup performance remains unaffected by the absence of an entire subgroup during training. We conduct a systematic study of subgroup allocation across four vision and language models, varying training data composition to characterise the sensitivity of subgroup performance to data balance. We propose the latent separation hypothesis, which states that a partially fine-tuned model's dependence on subgroup representation is determined by the degree of separation between subgroups in the latent space of the pre-trained model. We formalise this hypothesis, provide theoretical analysis, and validate it empirically. Finally, we present a practical application to foundation model fine-tuning, demonstrating that quantitative analysis of latent subgroup separation can inform data collection and balancing decisions.
A Primer on Causal and Statistical Dataset Biases for Fair and Robust Image Analysis
Sep 04, 2025Machine learning methods often fail when deployed in the real world. Worse still, they fail in high-stakes situations and across socially sensitive lines. These issues have a chilling effect on the adoption of machine learning methods in settings such as medical diagnosis, where they are arguably best-placed to provide benefits if safely deployed. In this primer, we introduce the causal and statistical structures which induce failure in machine learning methods for image analysis. We highlight two previously overlooked problems, which we call the \textit{no fair lunch} problem and the \textit{subgroup separability} problem. We elucidate why today's fair representation learning methods fail to adequately solve them and propose potential paths forward for the field.
Subgroups Matter for Robust Bias Mitigation
May 29, 2025Despite the constant development of new bias mitigation methods for machine learning, no method consistently succeeds, and a fundamental question remains unanswered: when and why do bias mitigation techniques fail? In this paper, we hypothesise that a key factor may be the often-overlooked but crucial step shared by many bias mitigation methods: the definition of subgroups. To investigate this, we conduct a comprehensive evaluation of state-of-the-art bias mitigation methods across multiple vision and language classification tasks, systematically varying subgroup definitions, including coarse, fine-grained, intersectional, and noisy subgroups. Our results reveal that subgroup choice significantly impacts performance, with certain groupings paradoxically leading to worse outcomes than no mitigation at all. Our findings suggest that observing a disparity between a set of subgroups is not a sufficient reason to use those subgroups for mitigation. Through theoretical analysis, we explain these phenomena and uncover a counter-intuitive insight that, in some cases, improving fairness with respect to a particular set of subgroups is best achieved by using a different set of subgroups for mitigation. Our work highlights the importance of careful subgroup definition in bias mitigation and presents it as an alternative lever for improving the robustness and fairness of machine learning models.
Automatic dataset shift identification to support root cause analysis of AI performance drift
Nov 13, 2024Shifts in data distribution can substantially harm the performance of clinical AI models. Hence, various methods have been developed to detect the presence of such shifts at deployment time. However, root causes of dataset shifts are varied, and the choice of shift mitigation strategies is highly dependent on the precise type of shift encountered at test time. As such, detecting test-time dataset shift is not sufficient: precisely identifying which type of shift has occurred is critical. In this work, we propose the first unsupervised dataset shift identification framework, effectively distinguishing between prevalence shift (caused by a change in the label distribution), covariate shift (caused by a change in input characteristics) and mixed shifts (simultaneous prevalence and covariate shifts). We discuss the importance of self-supervised encoders for detecting subtle covariate shifts and propose a novel shift detector leveraging both self-supervised encoders and task model outputs for improved shift detection. We report promising results for the proposed shift identification framework across three different imaging modalities (chest radiography, digital mammography, and retinal fundus images) on five types of real-world dataset shifts, using four large publicly available datasets.
Rethinking Fair Representation Learning for Performance-Sensitive Tasks
Oct 05, 2024



We investigate the prominent class of fair representation learning methods for bias mitigation. Using causal reasoning to define and formalise different sources of dataset bias, we reveal important implicit assumptions inherent to these methods. We prove fundamental limitations on fair representation learning when evaluation data is drawn from the same distribution as training data and run experiments across a range of medical modalities to examine the performance of fair representation learning under distribution shifts. Our results explain apparent contradictions in the existing literature and reveal how rarely considered causal and statistical aspects of the underlying data affect the validity of fair representation learning. We raise doubts about current evaluation practices and the applicability of fair representation learning methods in performance-sensitive settings. We argue that fine-grained analysis of dataset biases should play a key role in the field moving forward.
Mitigating attribute amplification in counterfactual image generation
Mar 14, 2024



Causal generative modelling is gaining interest in medical imaging due to its ability to answer interventional and counterfactual queries. Most work focuses on generating counterfactual images that look plausible, using auxiliary classifiers to enforce effectiveness of simulated interventions. We investigate pitfalls in this approach, discovering the issue of attribute amplification, where unrelated attributes are spuriously affected during interventions, leading to biases across protected characteristics and disease status. We show that attribute amplification is caused by the use of hard labels in the counterfactual training process and propose soft counterfactual fine-tuning to mitigate this issue. Our method substantially reduces the amplification effect while maintaining effectiveness of generated images, demonstrated on a large chest X-ray dataset. Our work makes an important advancement towards more faithful and unbiased causal modelling in medical imaging.
Synthia's Melody: A Benchmark Framework for Unsupervised Domain Adaptation in Audio
Sep 26, 2023Despite significant advancements in deep learning for vision and natural language, unsupervised domain adaptation in audio remains relatively unexplored. We, in part, attribute this to the lack of an appropriate benchmark dataset. To address this gap, we present Synthia's melody, a novel audio data generation framework capable of simulating an infinite variety of 4-second melodies with user-specified confounding structures characterised by musical keys, timbre, and loudness. Unlike existing datasets collected under observational settings, Synthia's melody is free of unobserved biases, ensuring the reproducibility and comparability of experiments. To showcase its utility, we generate two types of distribution shifts-domain shift and sample selection bias-and evaluate the performance of acoustic deep learning models under these shifts. Our evaluations reveal that Synthia's melody provides a robust testbed for examining the susceptibility of these models to varying levels of distribution shift.
No Fair Lunch: A Causal Perspective on Dataset Bias in Machine Learning for Medical Imaging
Jul 31, 2023



As machine learning methods gain prominence within clinical decision-making, addressing fairness concerns becomes increasingly urgent. Despite considerable work dedicated to detecting and ameliorating algorithmic bias, today's methods are deficient with potentially harmful consequences. Our causal perspective sheds new light on algorithmic bias, highlighting how different sources of dataset bias may appear indistinguishable yet require substantially different mitigation strategies. We introduce three families of causal bias mechanisms stemming from disparities in prevalence, presentation, and annotation. Our causal analysis underscores how current mitigation methods tackle only a narrow and often unrealistic subset of scenarios. We provide a practical three-step framework for reasoning about fairness in medical imaging, supporting the development of safe and equitable AI prediction models.
The Role of Subgroup Separability in Group-Fair Medical Image Classification
Jul 06, 2023

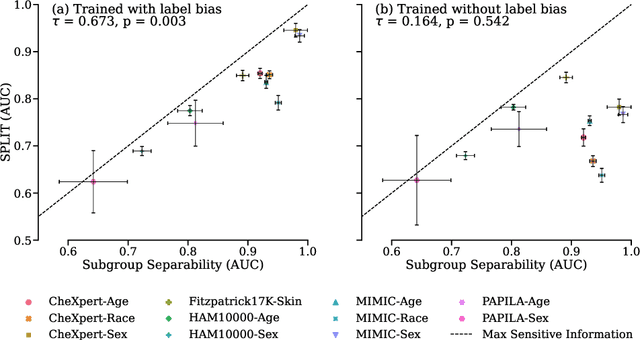
We investigate performance disparities in deep classifiers. We find that the ability of classifiers to separate individuals into subgroups varies substantially across medical imaging modalities and protected characteristics; crucially, we show that this property is predictive of algorithmic bias. Through theoretical analysis and extensive empirical evaluation, we find a relationship between subgroup separability, subgroup disparities, and performance degradation when models are trained on data with systematic bias such as underdiagnosis. Our findings shed new light on the question of how models become biased, providing important insights for the development of fair medical imaging AI.
Risk of Bias in Chest X-ray Foundation Models
Sep 07, 2022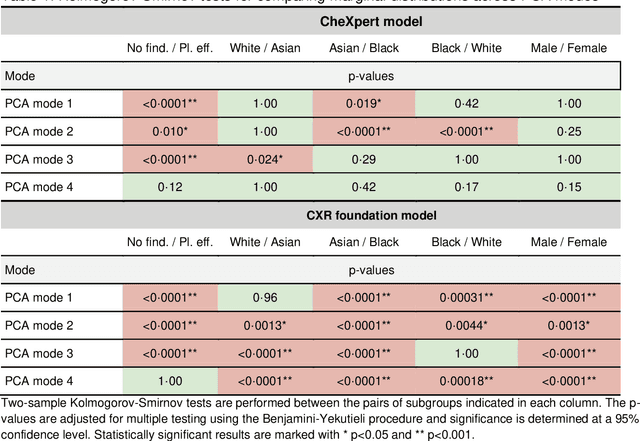
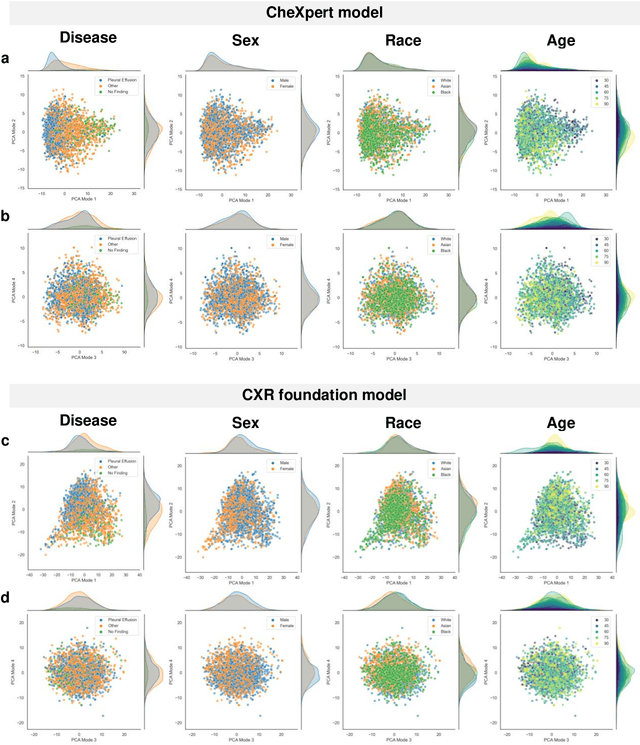
Foundation models are considered a breakthrough in all applications of AI, promising robust and reusable mechanisms for feature extraction, alleviating the need for large amounts of high quality training data for task-specific prediction models. However, foundation models may potentially encode and even reinforce existing biases present in historic datasets. Given the limited ability to scrutinize foundation models, it remains unclear whether the opportunities outweigh the risks in safety critical applications such as clinical decision making. In our statistical bias analysis of a recently published, and publicly available chest X-ray foundation model, we found reasons for concern as the model seems to encode protected characteristics including biological sex and racial identity, which may lead to disparate performance across subgroups in downstream applications. While research into foundation models for healthcare applications is in an early stage, we believe it is important to make the community aware of these risks to avoid harm.