 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere are we with calibration under dataset shift in image classification?
Jul 10, 2025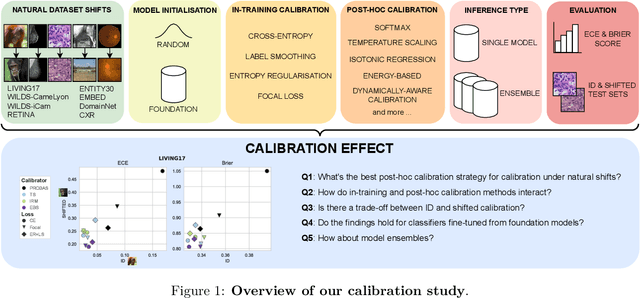
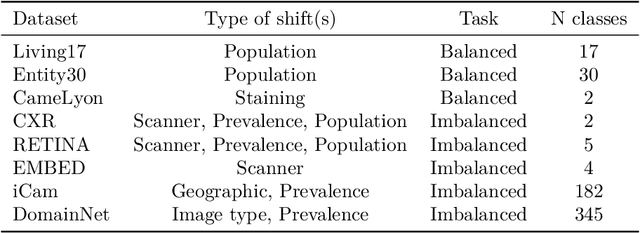

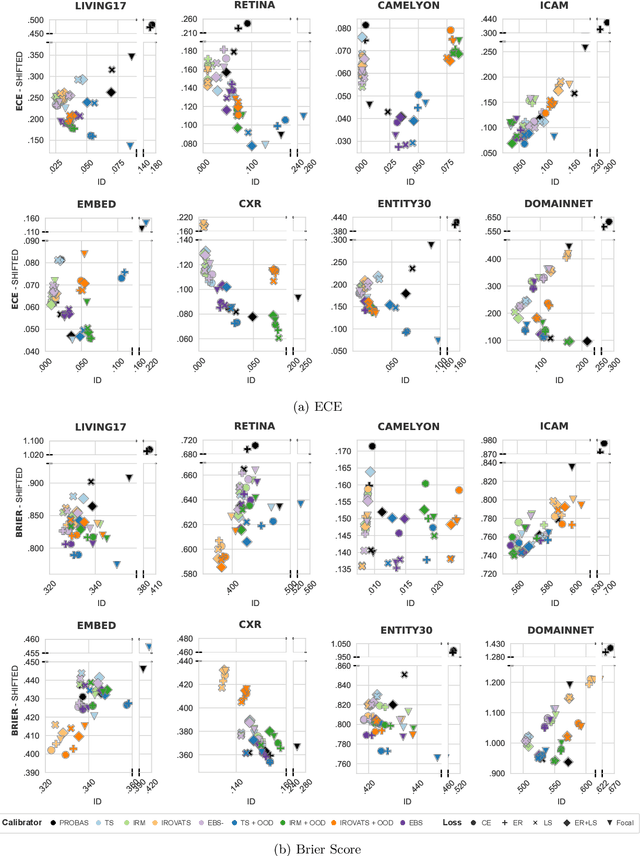
We conduct an extensive study on the state of calibration under real-world dataset shift for image classification. Our work provides important insights on the choice of post-hoc and in-training calibration techniques, and yields practical guidelines for all practitioners interested in robust calibration under shift. We compare various post-hoc calibration methods, and their interactions with common in-training calibration strategies (e.g., label smoothing), across a wide range of natural shifts, on eight different classification tasks across several imaging domains. We find that: (i) simultaneously applying entropy regularisation and label smoothing yield the best calibrated raw probabilities under dataset shift, (ii) post-hoc calibrators exposed to a small amount of semantic out-of-distribution data (unrelated to the task) are most robust under shift, (iii) recent calibration methods specifically aimed at increasing calibration under shifts do not necessarily offer significant improvements over simpler post-hoc calibration methods, (iv) improving calibration under shifts often comes at the cost of worsening in-distribution calibration. Importantly, these findings hold for randomly initialised classifiers, as well as for those finetuned from foundation models, the latter being consistently better calibrated compared to models trained from scratch. Finally, we conduct an in-depth analysis of ensembling effects, finding that (i) applying calibration prior to ensembling (instead of after) is more effective for calibration under shifts, (ii) for ensembles, OOD exposure deteriorates the ID-shifted calibration trade-off, (iii) ensembling remains one of the most effective methods to improve calibration robustness and, combined with finetuning from foundation models, yields best calibration results overall.
Rethinking Fair Representation Learning for Performance-Sensitive Tasks
Oct 05, 2024



We investigate the prominent class of fair representation learning methods for bias mitigation. Using causal reasoning to define and formalise different sources of dataset bias, we reveal important implicit assumptions inherent to these methods. We prove fundamental limitations on fair representation learning when evaluation data is drawn from the same distribution as training data and run experiments across a range of medical modalities to examine the performance of fair representation learning under distribution shifts. Our results explain apparent contradictions in the existing literature and reveal how rarely considered causal and statistical aspects of the underlying data affect the validity of fair representation learning. We raise doubts about current evaluation practices and the applicability of fair representation learning methods in performance-sensitive settings. We argue that fine-grained analysis of dataset biases should play a key role in the field moving forward.