 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the interplay of label bias with subgroup size and separability: A case study in mammographic density classification
Jul 24, 2025Systematic mislabelling affecting specific subgroups (i.e., label bias) in medical imaging datasets represents an understudied issue concerning the fairness of medical AI systems. In this work, we investigated how size and separability of subgroups affected by label bias influence the learned features and performance of a deep learning model. Therefore, we trained deep learning models for binary tissue density classification using the EMory BrEast imaging Dataset (EMBED), where label bias affected separable subgroups (based on imaging manufacturer) or non-separable "pseudo-subgroups". We found that simulated subgroup label bias led to prominent shifts in the learned feature representations of the models. Importantly, these shifts within the feature space were dependent on both the relative size and the separability of the subgroup affected by label bias. We also observed notable differences in subgroup performance depending on whether a validation set with clean labels was used to define the classification threshold for the model. For instance, with label bias affecting the majority separable subgroup, the true positive rate for that subgroup fell from 0.898, when the validation set had clean labels, to 0.518, when the validation set had biased labels. Our work represents a key contribution toward understanding the consequences of label bias on subgroup fairness in medical imaging AI.
Where are we with calibration under dataset shift in image classification?
Jul 10, 2025

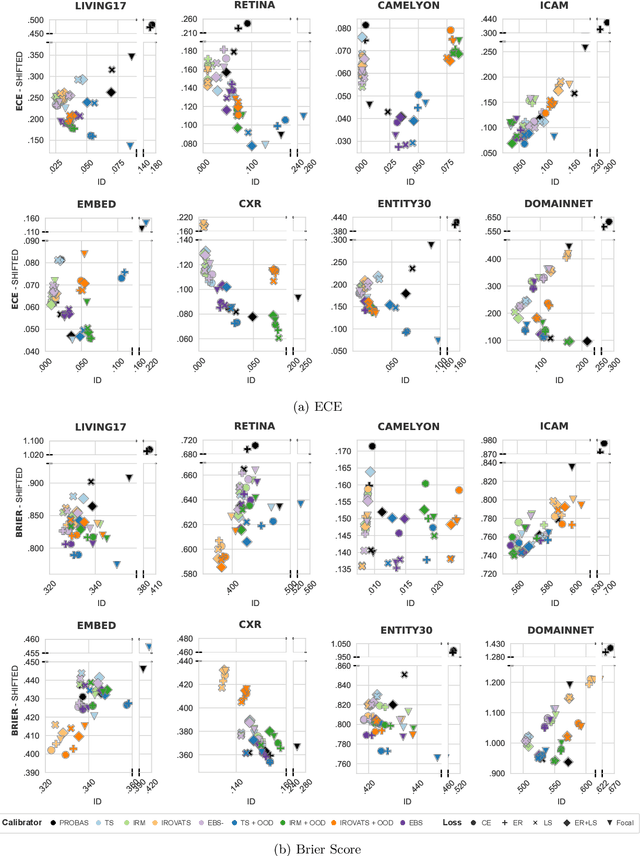
We conduct an extensive study on the state of calibration under real-world dataset shift for image classification. Our work provides important insights on the choice of post-hoc and in-training calibration techniques, and yields practical guidelines for all practitioners interested in robust calibration under shift. We compare various post-hoc calibration methods, and their interactions with common in-training calibration strategies (e.g., label smoothing), across a wide range of natural shifts, on eight different classification tasks across several imaging domains. We find that: (i) simultaneously applying entropy regularisation and label smoothing yield the best calibrated raw probabilities under dataset shift, (ii) post-hoc calibrators exposed to a small amount of semantic out-of-distribution data (unrelated to the task) are most robust under shift, (iii) recent calibration methods specifically aimed at increasing calibration under shifts do not necessarily offer significant improvements over simpler post-hoc calibration methods, (iv) improving calibration under shifts often comes at the cost of worsening in-distribution calibration. Importantly, these findings hold for randomly initialised classifiers, as well as for those finetuned from foundation models, the latter being consistently better calibrated compared to models trained from scratch. Finally, we conduct an in-depth analysis of ensembling effects, finding that (i) applying calibration prior to ensembling (instead of after) is more effective for calibration under shifts, (ii) for ensembles, OOD exposure deteriorates the ID-shifted calibration trade-off, (iii) ensembling remains one of the most effective methods to improve calibration robustness and, combined with finetuning from foundation models, yields best calibration results overall.
Automatic dataset shift identification to support root cause analysis of AI performance drift
Nov 13, 2024Shifts in data distribution can substantially harm the performance of clinical AI models. Hence, various methods have been developed to detect the presence of such shifts at deployment time. However, root causes of dataset shifts are varied, and the choice of shift mitigation strategies is highly dependent on the precise type of shift encountered at test time. As such, detecting test-time dataset shift is not sufficient: precisely identifying which type of shift has occurred is critical. In this work, we propose the first unsupervised dataset shift identification framework, effectively distinguishing between prevalence shift (caused by a change in the label distribution), covariate shift (caused by a change in input characteristics) and mixed shifts (simultaneous prevalence and covariate shifts). We discuss the importance of self-supervised encoders for detecting subtle covariate shifts and propose a novel shift detector leveraging both self-supervised encoders and task model outputs for improved shift detection. We report promising results for the proposed shift identification framework across three different imaging modalities (chest radiography, digital mammography, and retinal fundus images) on five types of real-world dataset shifts, using four large publicly available datasets.
Rethinking Fair Representation Learning for Performance-Sensitive Tasks
Oct 05, 2024



We investigate the prominent class of fair representation learning methods for bias mitigation. Using causal reasoning to define and formalise different sources of dataset bias, we reveal important implicit assumptions inherent to these methods. We prove fundamental limitations on fair representation learning when evaluation data is drawn from the same distribution as training data and run experiments across a range of medical modalities to examine the performance of fair representation learning under distribution shifts. Our results explain apparent contradictions in the existing literature and reveal how rarely considered causal and statistical aspects of the underlying data affect the validity of fair representation learning. We raise doubts about current evaluation practices and the applicability of fair representation learning methods in performance-sensitive settings. We argue that fine-grained analysis of dataset biases should play a key role in the field moving forward.
Radio-opaque artefacts in digital mammography: automatic detection and analysis of downstream effects
Oct 04, 2024
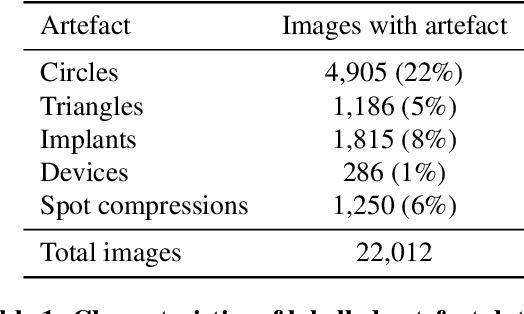


This study investigates the effects of radio-opaque artefacts, such as skin markers, breast implants, and pacemakers, on mammography classification models. After manually annotating 22,012 mammograms from the publicly available EMBED dataset, a robust multi-label artefact detector was developed to identify five distinct artefact types (circular and triangular skin markers, breast implants, support devices and spot compression structures). Subsequent experiments on two clinically relevant tasks $-$ breast density assessment and cancer screening $-$ revealed that these artefacts can significantly affect model performance, alter classification thresholds, and distort output distributions. These findings underscore the importance of accurate automatic artefact detection for developing reliable and robust classification models in digital mammography. To facilitate future research our annotations, code, and model predictions are made publicly available.
Robust image representations with counterfactual contrastive learning
Sep 16, 2024



Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy applied to generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discarding unwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt to simulate domain shifts through pre-defined generic image transformations. However, these do not always mimic realistic and relevant domain variations for medical imaging such as scanner differences. To tackle this issue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances in causal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations. Our method, evaluated across five datasets encompassing both chest radiography and mammography data, for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learning in terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superior downstream performance on both in-distribution and on external datasets, especially for images acquired with scanners under-represented in the training set. Further experiments show that the proposed framework extends beyond acquisition shifts, with models trained with counterfactual contrastive learning substantially improving subgroup performance across biological sex.
Mitigating attribute amplification in counterfactual image generation
Mar 14, 2024



Causal generative modelling is gaining interest in medical imaging due to its ability to answer interventional and counterfactual queries. Most work focuses on generating counterfactual images that look plausible, using auxiliary classifiers to enforce effectiveness of simulated interventions. We investigate pitfalls in this approach, discovering the issue of attribute amplification, where unrelated attributes are spuriously affected during interventions, leading to biases across protected characteristics and disease status. We show that attribute amplification is caused by the use of hard labels in the counterfactual training process and propose soft counterfactual fine-tuning to mitigate this issue. Our method substantially reduces the amplification effect while maintaining effectiveness of generated images, demonstrated on a large chest X-ray dataset. Our work makes an important advancement towards more faithful and unbiased causal modelling in medical imaging.
Distance Matters For Improving Performance Estimation Under Covariate Shift
Aug 14, 2023
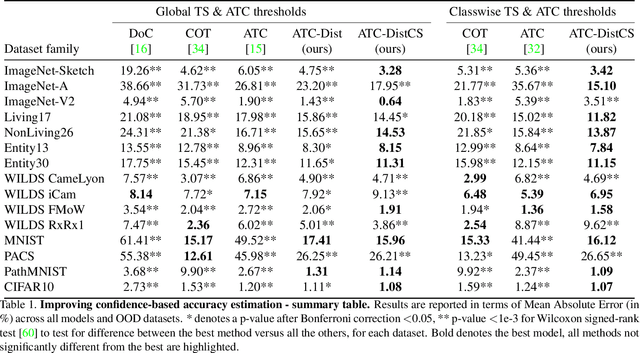


Performance estimation under covariate shift is a crucial component of safe AI model deployment, especially for sensitive use-cases. Recently, several solutions were proposed to tackle this problem, most leveraging model predictions or softmax confidence to derive accuracy estimates. However, under dataset shifts, confidence scores may become ill-calibrated if samples are too far from the training distribution. In this work, we show that taking into account distances of test samples to their expected training distribution can significantly improve performance estimation under covariate shift. Precisely, we introduce a "distance-check" to flag samples that lie too far from the expected distribution, to avoid relying on their untrustworthy model outputs in the accuracy estimation step. We demonstrate the effectiveness of this method on 13 image classification tasks, across a wide-range of natural and synthetic distribution shifts and hundreds of models, with a median relative MAE improvement of 27% over the best baseline across all tasks, and SOTA performance on 10 out of 13 tasks. Our code is publicly available at https://github.com/melanibe/distance_matters_performance_estimation.
The Role of Subgroup Separability in Group-Fair Medical Image Classification
Jul 06, 2023

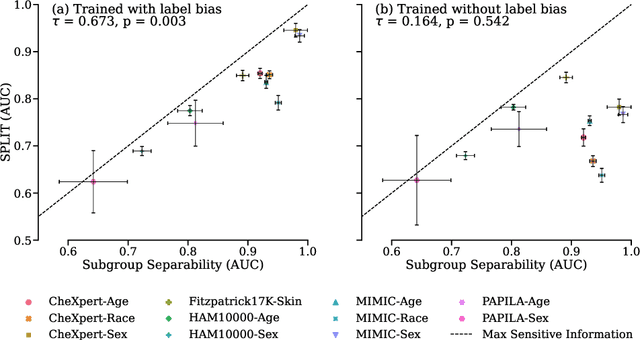
We investigate performance disparities in deep classifiers. We find that the ability of classifiers to separate individuals into subgroups varies substantially across medical imaging modalities and protected characteristics; crucially, we show that this property is predictive of algorithmic bias. Through theoretical analysis and extensive empirical evaluation, we find a relationship between subgroup separability, subgroup disparities, and performance degradation when models are trained on data with systematic bias such as underdiagnosis. Our findings shed new light on the question of how models become biased, providing important insights for the development of fair medical imaging AI.