 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Tropical Cyclone Forecasting With Video Diffusion Models
Jan 27, 2025



Tropical cyclone (TC) forecasting is crucial for disaster preparedness and mitigation. While recent deep learning approaches have shown promise, existing methods often treat TC evolution as a series of independent frame-to-frame predictions, limiting their ability to capture long-term dynamics. We present a novel application of video diffusion models for TC forecasting that explicitly models temporal dependencies through additional temporal layers. Our approach enables the model to generate multiple frames simultaneously, better capturing cyclone evolution patterns. We introduce a two-stage training strategy that significantly improves individual-frame quality and performance in low-data regimes. Experimental results show our method outperforms the previous approach of Nath et al. by 19.3% in MAE, 16.2% in PSNR, and 36.1% in SSIM. Most notably, we extend the reliable forecasting horizon from 36 to 50 hours. Through comprehensive evaluation using both traditional metrics and Fr\'echet Video Distance (FVD), we demonstrate that our approach produces more temporally coherent forecasts while maintaining competitive single-frame quality. Code accessible at https://github.com/Ren-creater/forecast-video-diffmodels.
Forecasting Tropical Cyclones with Cascaded Diffusion Models
Oct 04, 2023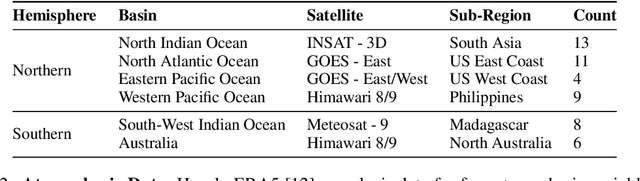
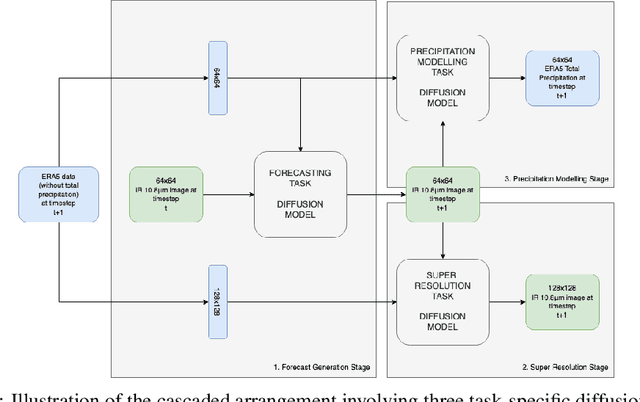

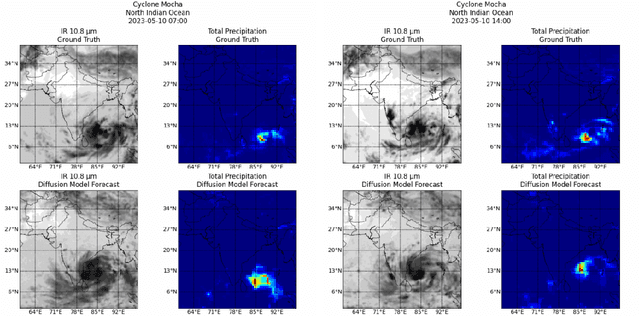
As cyclones become more intense due to climate change, the rise of AI-based modelling provides a more affordable and accessible approach compared to traditional methods based on mathematical models. This work leverages diffusion models to forecast cyclone trajectories and precipitation patterns by integrating satellite imaging, remote sensing, and atmospheric data, employing a cascaded approach that incorporates forecasting, super-resolution, and precipitation modelling, with training on a dataset of 51 cyclones from six major basins. Experiments demonstrate that the final forecasts from the cascaded models show accurate predictions up to a 36-hour rollout, with SSIM and PSNR values exceeding 0.5 and 20 dB, respectively, for all three tasks. This work also highlights the promising efficiency of AI methods such as diffusion models for high-performance needs, such as cyclone forecasting, while remaining computationally affordable, making them ideal for highly vulnerable regions with critical forecasting needs and financial limitations. Code accessible at \url{https://github.com/nathzi1505/forecast-diffmodels}.
Music Source Separation Based on a Lightweight Deep Learning Framework (DTTNET: DUAL-PATH TFC-TDF UNET)
Sep 15, 2023Music source separation (MSS) aims to extract 'vocals', 'drums', 'bass' and 'other' tracks from a piece of mixed music. While deep learning methods have shown impressive results, there is a trend toward larger models. In our paper, we introduce a novel and lightweight architecture called DTTNet, which is based on Dual-Path Module and Time-Frequency Convolutions Time-Distributed Fully-connected UNet (TFC-TDF UNet). DTTNet achieves 10.12 dB cSDR on 'vocals' compared to 10.01 dB reported for Bandsplit RNN (BSRNN) but with 86.7% fewer parameters. We also assess pattern-specific performance and model generalization for intricate audio patterns.
Audio Barlow Twins: Self-Supervised Audio Representation Learning
Sep 28, 2022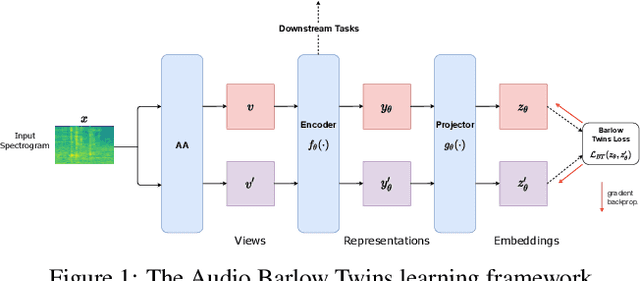
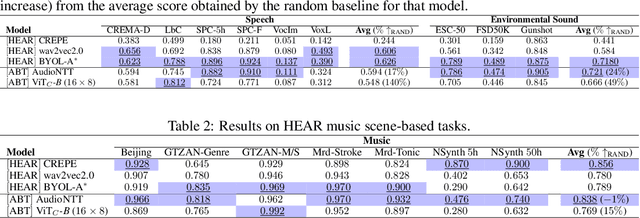

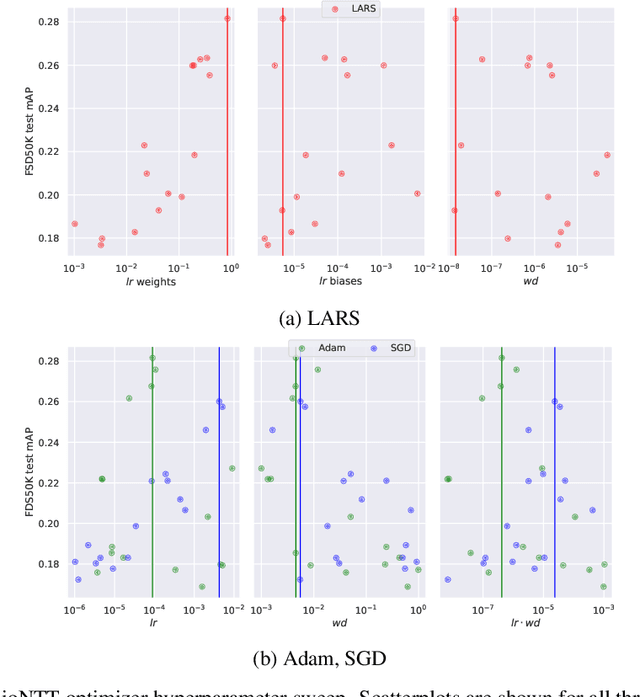
The Barlow Twins self-supervised learning objective requires neither negative samples or asymmetric learning updates, achieving results on a par with the current state-of-the-art within Computer Vision. As such, we present Audio Barlow Twins, a novel self-supervised audio representation learning approach, adapting Barlow Twins to the audio domain. We pre-train on the large-scale audio dataset AudioSet, and evaluate the quality of the learnt representations on 18 tasks from the HEAR 2021 Challenge, achieving results which outperform, or otherwise are on a par with, the current state-of-the-art for instance discrimination self-supervised learning approaches to audio representation learning. Code at https://github.com/jonahanton/SSL_audio.