 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePervasive Annotation Errors Break Text-to-SQL Benchmarks and Leaderboards
Jan 13, 2026Researchers have proposed numerous text-to-SQL techniques to streamline data analytics and accelerate the development of database-driven applications. To compare these techniques and select the best one for deployment, the community depends on public benchmarks and their leaderboards. Since these benchmarks heavily rely on human annotations during question construction and answer evaluation, the validity of the annotations is crucial. In this paper, we conduct an empirical study that (i) benchmarks annotation error rates for two widely used text-to-SQL benchmarks, BIRD and Spider 2.0-Snow, and (ii) corrects a subset of the BIRD development (Dev) set to measure the impact of annotation errors on text-to-SQL agent performance and leaderboard rankings. Through expert analysis, we show that BIRD Mini-Dev and Spider 2.0-Snow have error rates of 52.8% and 62.8%, respectively. We re-evaluate all 16 open-source agents from the BIRD leaderboard on both the original and the corrected BIRD Dev subsets. We show that performance changes range from -7% to 31% (in relative terms) and rank changes range from $-9$ to $+9$ positions. We further assess whether these impacts generalize to the full BIRD Dev set. We find that the rankings of agents on the uncorrected subset correlate strongly with those on the full Dev set (Spearman's $r_s$=0.85, $p$=3.26e-5), whereas they correlate weakly with those on the corrected subset (Spearman's $r_s$=0.32, $p$=0.23). These findings show that annotation errors can significantly distort reported performance and rankings, potentially misguiding research directions or deployment choices. Our code and data are available at https://github.com/uiuc-kang-lab/text_to_sql_benchmarks.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025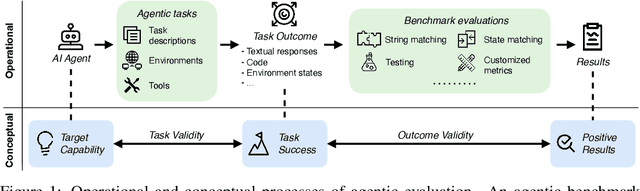
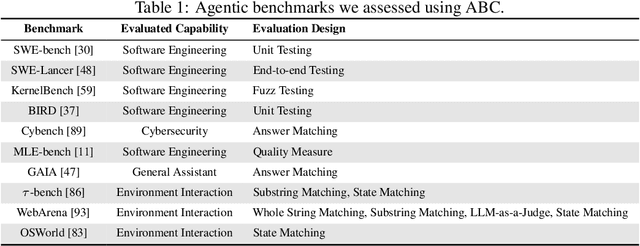
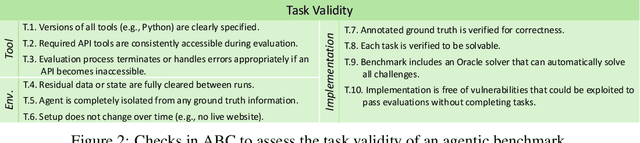
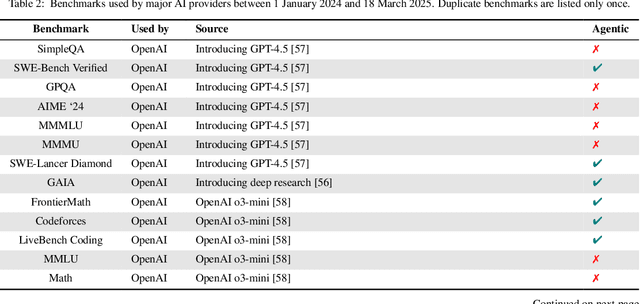
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
ELT-Bench: An End-to-End Benchmark for Evaluating AI Agents on ELT Pipelines
Apr 07, 2025Practitioners are increasingly turning to Extract-Load-Transform (ELT) pipelines with the widespread adoption of cloud data warehouses. However, designing these pipelines often involves significant manual work to ensure correctness. Recent advances in AI-based methods, which have shown strong capabilities in data tasks, such as text-to-SQL, present an opportunity to alleviate manual efforts in developing ELT pipelines. Unfortunately, current benchmarks in data engineering only evaluate isolated tasks, such as using data tools and writing data transformation queries, leaving a significant gap in evaluating AI agents for generating end-to-end ELT pipelines. To fill this gap, we introduce ELT-Bench, an end-to-end benchmark designed to assess the capabilities of AI agents to build ELT pipelines. ELT-Bench consists of 100 pipelines, including 835 source tables and 203 data models across various domains. By simulating realistic scenarios involving the integration of diverse data sources and the use of popular data tools, ELT-Bench evaluates AI agents' abilities in handling complex data engineering workflows. AI agents must interact with databases and data tools, write code and SQL queries, and orchestrate every pipeline stage. We evaluate two representative code agent frameworks, Spider-Agent and SWE-Agent, using six popular Large Language Models (LLMs) on ELT-Bench. The highest-performing agent, Spider-Agent Claude-3.7-Sonnet with extended thinking, correctly generates only 3.9% of data models, with an average cost of $4.30 and 89.3 steps per pipeline. Our experimental results demonstrate the challenges of ELT-Bench and highlight the need for a more advanced AI agent to reduce manual effort in ELT workflows. Our code and data are available at https://github.com/uiuc-kang-lab/ETL.git.