 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scoping Review of Machine Learning Applications in Power System Protection and Disturbance Management
Sep 10, 2025The integration of renewable and distributed energy resources reshapes modern power systems, challenging conventional protection schemes. This scoping review synthesizes recent literature on machine learning (ML) applications in power system protection and disturbance management, following the PRISMA for Scoping Reviews framework. Based on over 100 publications, three key objectives are addressed: (i) assessing the scope of ML research in protection tasks; (ii) evaluating ML performance across diverse operational scenarios; and (iii) identifying methods suitable for evolving grid conditions. ML models often demonstrate high accuracy on simulated datasets; however, their performance under real-world conditions remains insufficiently validated. The existing literature is fragmented, with inconsistencies in methodological rigor, dataset quality, and evaluation metrics. This lack of standardization hampers the comparability of results and limits the generalizability of findings. To address these challenges, this review introduces a ML-oriented taxonomy for protection tasks, resolves key terminological inconsistencies, and advocates for standardized reporting practices. It further provides guidelines for comprehensive dataset documentation, methodological transparency, and consistent evaluation protocols, aiming to improve reproducibility and enhance the practical relevance of research outcomes. Critical gaps remain, including the scarcity of real-world validation, insufficient robustness testing, and limited consideration of deployment feasibility. Future research should prioritize public benchmark datasets, realistic validation methods, and advanced ML architectures. These steps are essential to move ML-based protection from theoretical promise to practical deployment in increasingly dynamic and decentralized power systems.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022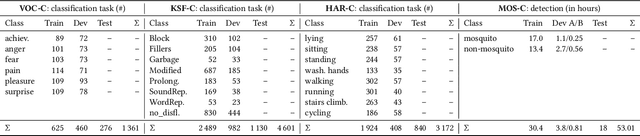
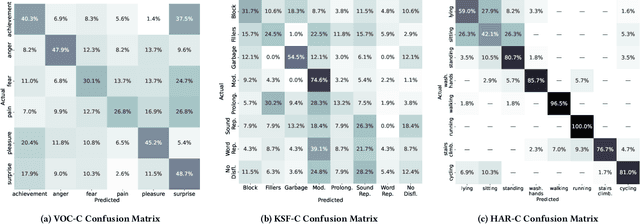

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022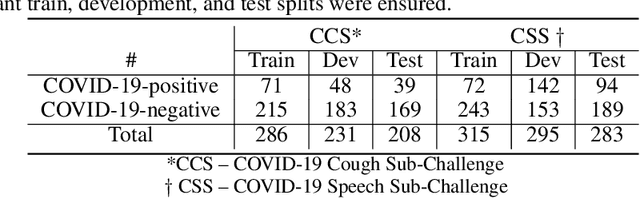
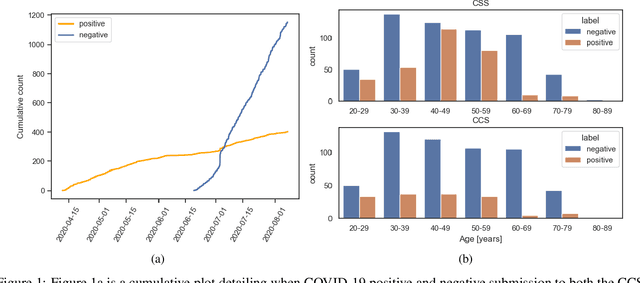
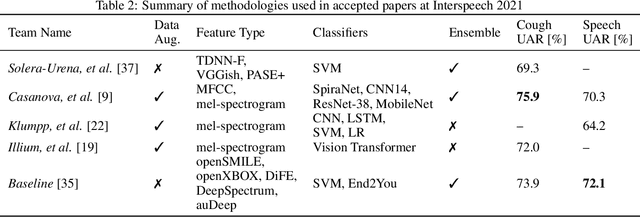
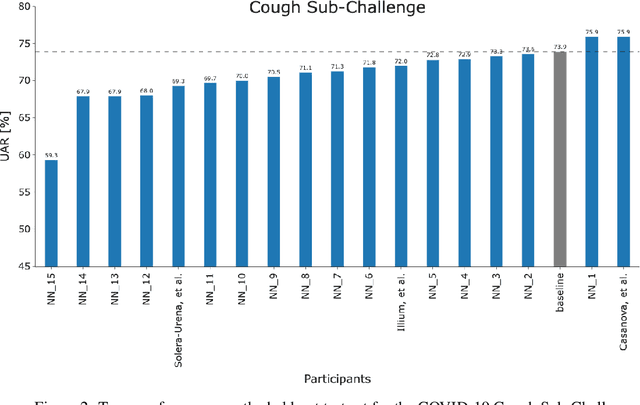
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
InSE-NET: A Perceptually Coded Audio Quality Model based on CNN
Aug 30, 2021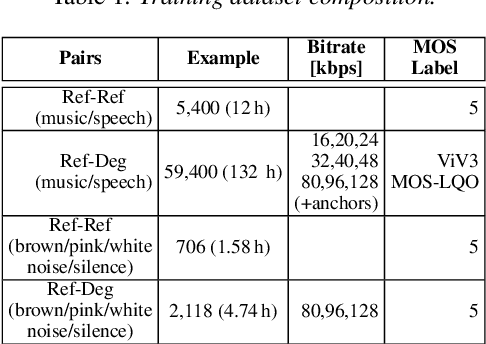
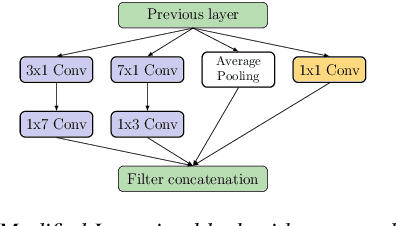
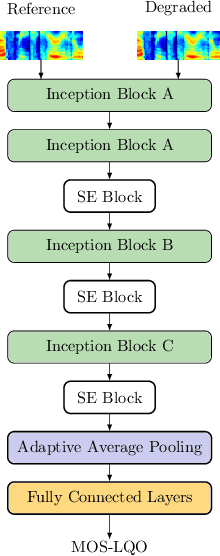
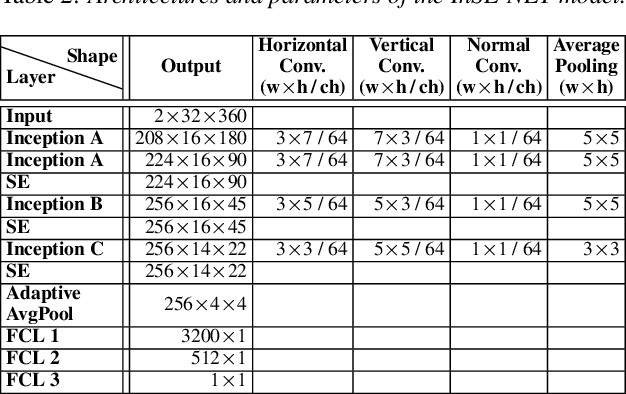
Automatic coded audio quality assessment is an important task whose progress is hampered by the scarcity of human annotations, poor generalization to unseen codecs, bitrates, content-types, and a lack of flexibility of existing approaches. One of the typical human-perception-related metrics, ViSQOL v3 (ViV3), has been proven to provide a high correlation to the quality scores rated by humans. In this study, we take steps to tackle problems of predicting coded audio quality by completely utilizing programmatically generated data that is informed with expert domain knowledge. We propose a learnable neural network, entitled InSE-NET, with a backbone of Inception and Squeeze-and-Excitation modules to assess the perceived quality of coded audio at a 48kHz sample rate. We demonstrate that synthetic data augmentation is capable of enhancing the prediction. Our proposed method is intrusive, i.e. it requires Gammatone spectrograms of unencoded reference signals. Besides a comparable performance to ViV3, our approach provides a more robust prediction towards higher bitrates.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021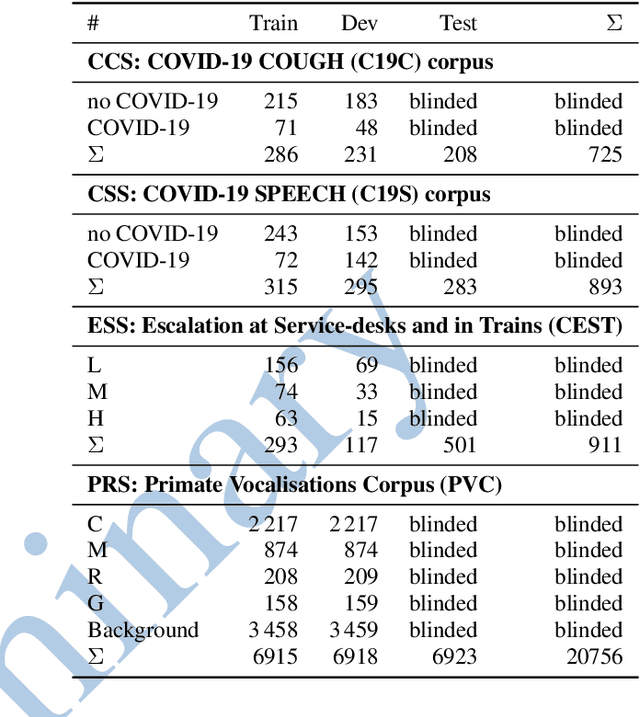
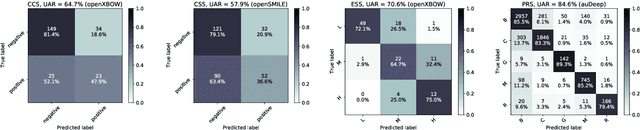
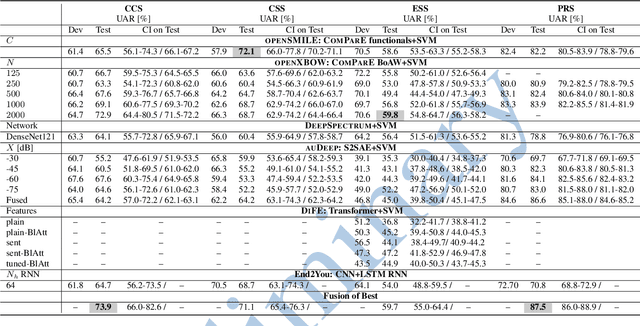
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
EXACT: A collaboration toolset for algorithm-aided annotation of almost everything
Apr 30, 2020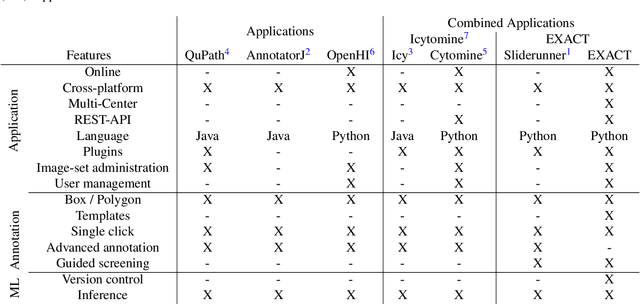
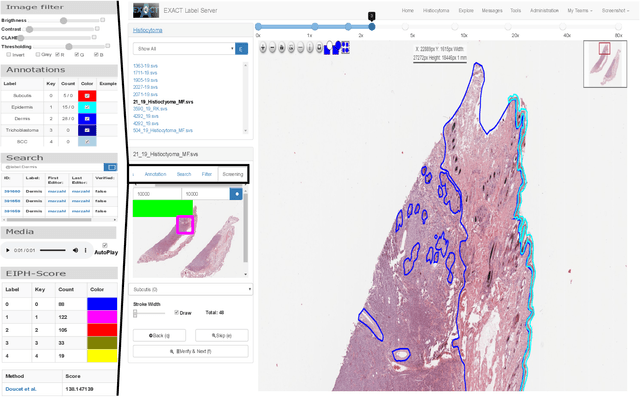
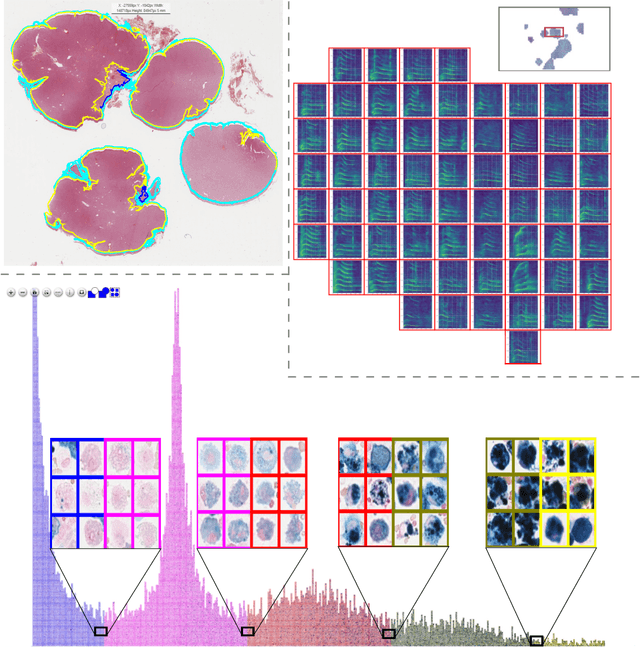
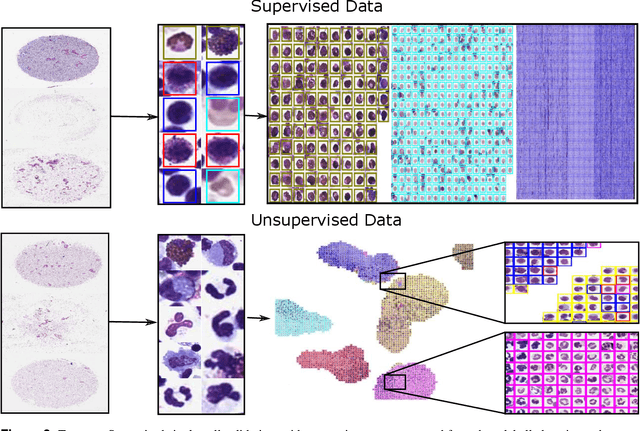
In many research areas scientific progress is accelerated by multidisciplinary access to image data and their interdisciplinary annotation. However, keeping track of these annotations to ensure a high-quality multi purpose data set is a challenging and labour intensive task. We developed the open-source online platform EXACT (EXpert Algorithm Cooperation Tool) that enables the collaborative interdisciplinary analysis of images from different domains online and offline. EXACT supports multi-gigapixel whole slide medical images, as well as image series with thousands of images. The software utilises a flexible plugin system that can be adapted to diverse applications such as counting mitotic figures with the screening mode, finding false annotations on a novel validation view, or using the latest deep learning image analysis technologies. This is combined with a version control system which makes it possible to keep track of changes in data sets and, for example, to link the results of deep learning experiments to specific data set versions. EXACT is freely available and has been applied successfully to a broad range of annotation tasks already, including highly diverse applications like deep learning supported cytology grading, interdisciplinary multi-centre whole slide image tumour annotation, and highly specialised whale sound spectroscopy clustering.
Analysis by Adversarial Synthesis -- A Novel Approach for Speech Vocoding
Jul 01, 2019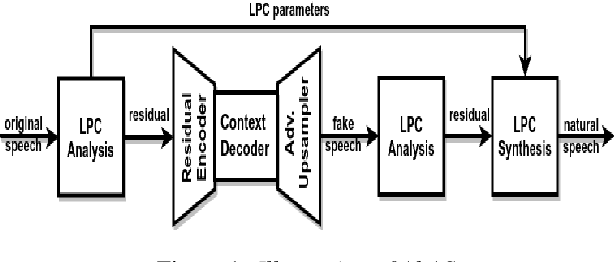
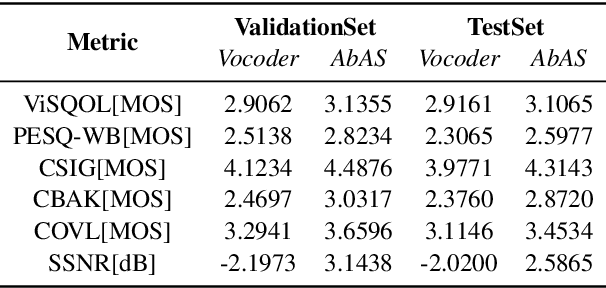
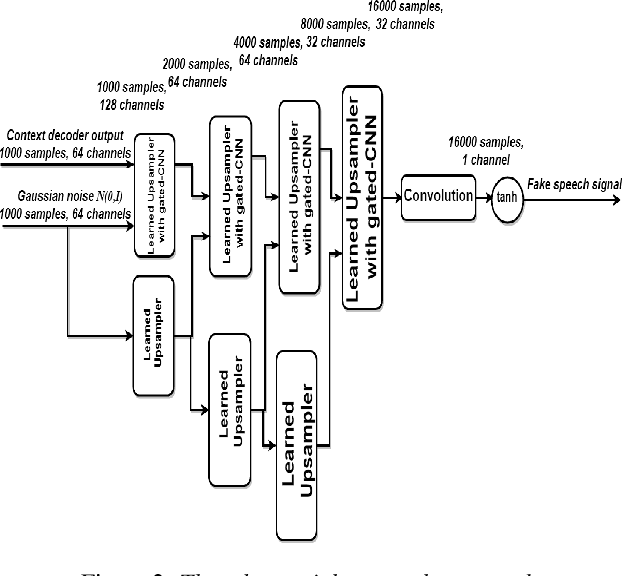
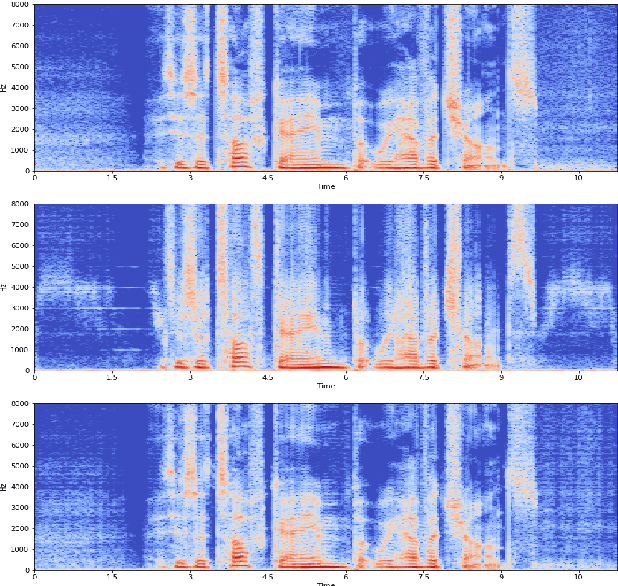
Classical parametric speech coding techniques provide a compact representation for speech signals. This affords a very low transmission rate but with a reduced perceptual quality of the reconstructed signals. Recently, autoregressive deep generative models such as WaveNet and SampleRNN have been used as speech vocoders to scale up the perceptual quality of the reconstructed signals without increasing the coding rate. However, such models suffer from a very slow signal generation mechanism due to their sample-by-sample modelling approach. In this work, we introduce a new methodology for neural speech vocoding based on generative adversarial networks (GANs). A fake speech signal is generated from a very compressed representation of the glottal excitation using conditional GANs as a deep generative model. This fake speech is then refined using the LPC parameters of the original speech signal to obtain a natural reconstruction. The reconstructed speech waveforms based on this approach show a higher perceptual quality than the classical vocoder counterparts according to subjective and objective evaluation scores for a dataset of 30 male and female speakers. Moreover, the usage of GANs enables to generate signals in one-shot compared to autoregressive generative models. This makes GANs promising for exploration to implement high-quality neural vocoders.