 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatiotemporal Illumination Model for 3D Image Fusion in Optical Coherence Tomography
Feb 19, 2024Optical coherence tomography (OCT) is a non-invasive, micrometer-scale imaging modality that has become a clinical standard in ophthalmology. By raster-scanning the retina, sequential cross-sectional image slices are acquired to generate volumetric data. In-vivo imaging suffers from discontinuities between slices that show up as motion and illumination artifacts. We present a new illumination model that exploits continuity in orthogonally raster-scanned volume data. Our novel spatiotemporal parametrization adheres to illumination continuity both temporally, along the imaged slices, as well as spatially, in the transverse directions. Yet, our formulation does not make inter-slice assumptions, which could have discontinuities. This is the first optimization of a 3D inverse model in an image reconstruction context in OCT. Evaluation in 68 volumes from eyes with pathology showed reduction of illumination artifacts in 88\% of the data, and only 6\% showed moderate residual illumination artifacts. The method enables the use of forward-warped motion corrected data, which is more accurate, and enables supersampling and advanced 3D image reconstruction in OCT.
A Spatiotemporal Model for Precise and Efficient Fully-automatic 3D Motion Correction in OCT
Sep 15, 2022Optical coherence tomography (OCT) is a micrometer-scale, volumetric imaging modality that has become a clinical standard in ophthalmology. OCT instruments image by raster-scanning a focused light spot across the retina, acquiring sequential cross-sectional images to generate volumetric data. Patient eye motion during the acquisition poses unique challenges: Non-rigid, discontinuous distortions can occur, leading to gaps in data and distorted topographic measurements. We present a new distortion model and a corresponding fully-automatic, reference-free optimization strategy for computational motion correction in orthogonally raster-scanned, retinal OCT volumes. Using a novel, domain-specific spatiotemporal parametrization of forward-warping displacements, eye motion can be corrected continuously for the first time. Parameter estimation with temporal regularization improves robustness and accuracy over previous spatial approaches. We correct each A-scan individually in 3D in a single mapping, including repeated acquisitions used in OCT angiography protocols. Specialized 3D forward image warping reduces median runtime to < 9 s, fast enough for clinical use. We present a quantitative evaluation on 18 subjects with ocular pathology and demonstrate accurate correction during microsaccades. Transverse correction is limited only by ocular tremor, whereas submicron repeatability is achieved axially (0.51 um median of medians), representing a dramatic improvement over previous work. This allows assessing longitudinal changes in focal retinal pathologies as a marker of disease progression or treatment response, and promises to enable multiple new capabilities such as supersampled/super-resolution volume reconstruction and analysis of pathological eye motion occuring in neurological diseases.
Maximum a posteriori signal recovery for optical coherence tomography angiography image generation and denoising
Oct 29, 2020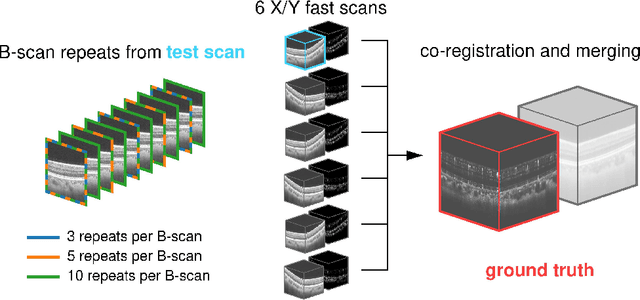
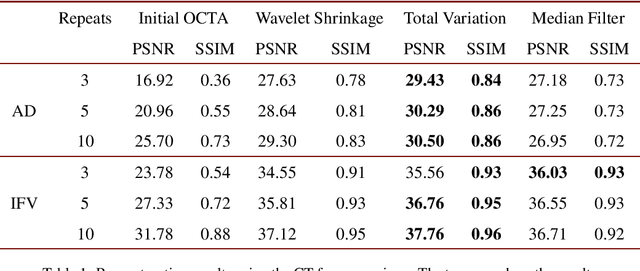
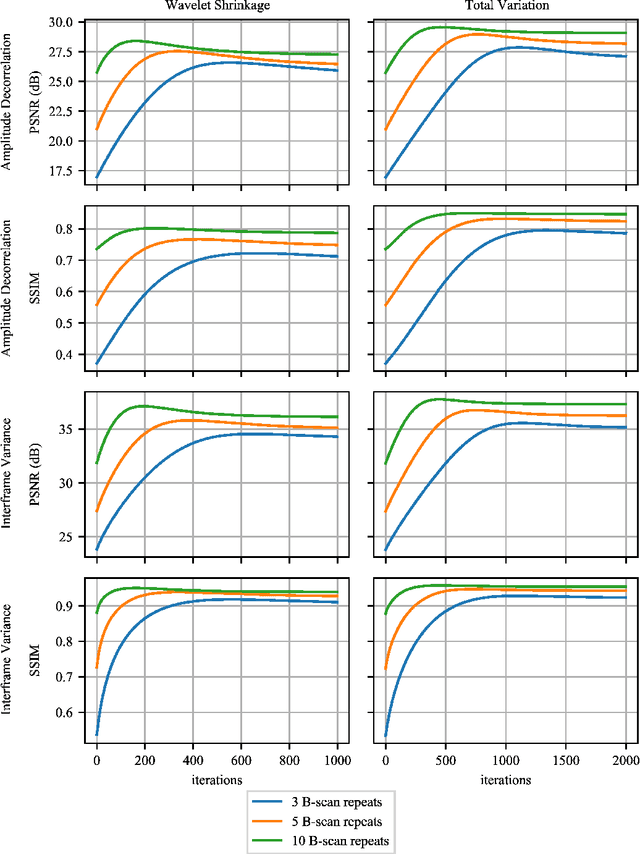

Optical coherence tomography angiography (OCTA) is a novel and clinically promising imaging modality to image retinal and sub-retinal vasculature. Based on repeated optical coherence tomography (OCT) scans, intensity changes are observed over time and used to compute OCTA image data. OCTA data are prone to noise and artifacts caused by variations in flow speed and patient movement. We propose a novel iterative maximum a posteriori signal recovery algorithm in order to generate OCTA volumes with reduced noise and increased image quality. This algorithm is based on previous work on probabilistic OCTA signal models and maximum likelihood estimates. Reconstruction results using total variation minimization and wavelet shrinkage for regularization were compared against an OCTA ground truth volume, merged from six co-registered single OCTA volumes. The results show a significant improvement in peak signal-to-noise ratio and structural similarity. The presented algorithm brings together OCTA image generation and Bayesian statistics and can be developed into new OCTA image generation and denoising algorithms.
Efficient and high accuracy 3-D OCT angiography motion correction in pathology
Oct 14, 2020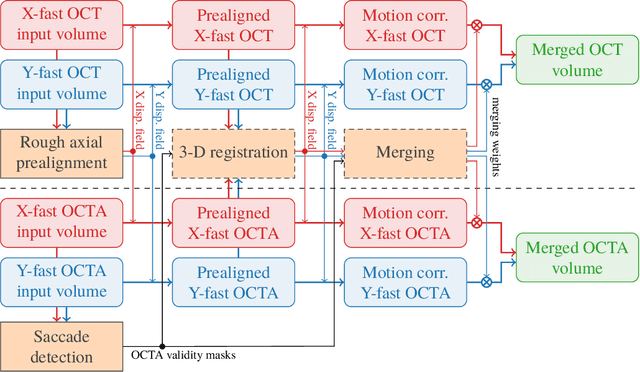
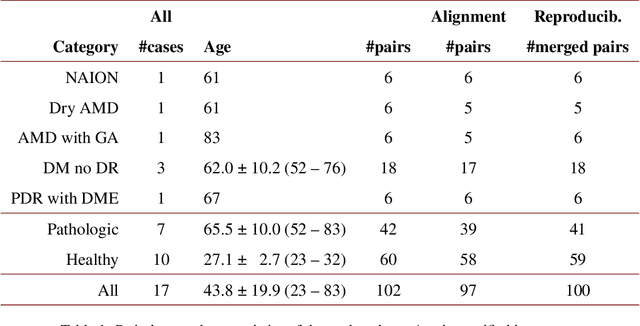
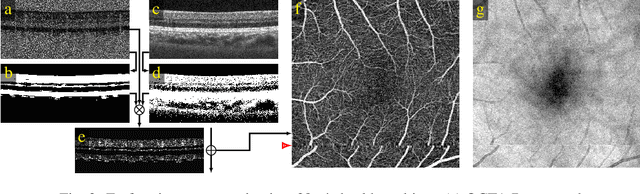
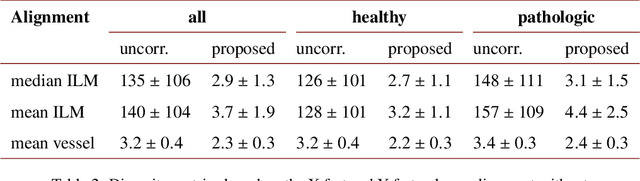
We propose a novel method for non-rigid 3-D motion correction of orthogonally raster-scanned optical coherence tomography angiography volumes. This is the first approach that aligns predominantly axial structural features like retinal layers and transverse angiographic vascular features in a joint optimization. Combined with the use of orthogonal scans and favorization of kinematically more plausible displacements, the approach allows subpixel alignment and micrometer-scale distortion correction in all 3 dimensions. As no specific structures or layers are segmented, the approach is by design robust to pathologic changes. It is furthermore designed for highly parallel implementation and brief runtime, allowing its integration in clinical routine even for high density or wide-field scans. We evaluated the algorithm with metrics related to clinically relevant features in a large-scale quantitative evaluation based on 204 volumetric scans of 17 subjects including both a wide range of pathologies and healthy controls. Using this method, we achieve state-of-the-art axial performance and show significant advances in both transverse co-alignment and distortion correction, especially in the pathologic subgroup.
Analysis by Adversarial Synthesis -- A Novel Approach for Speech Vocoding
Jul 01, 2019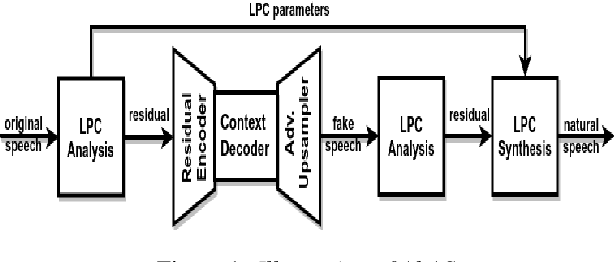
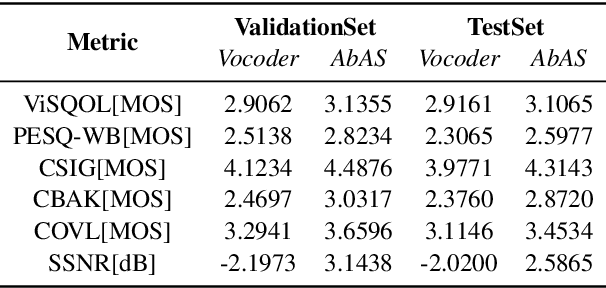
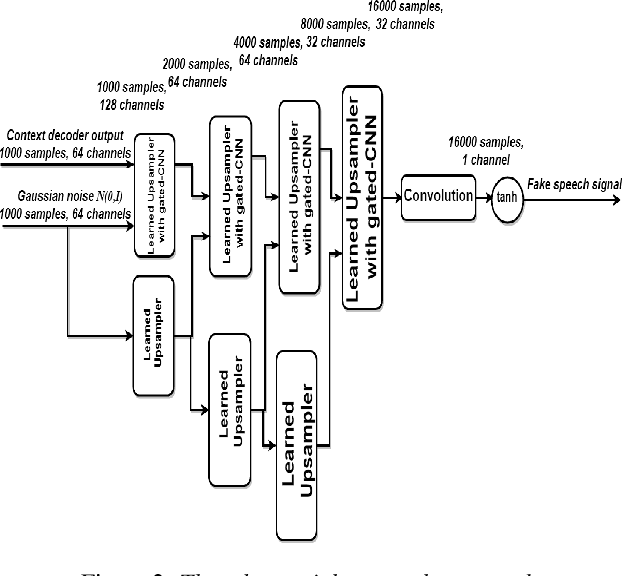
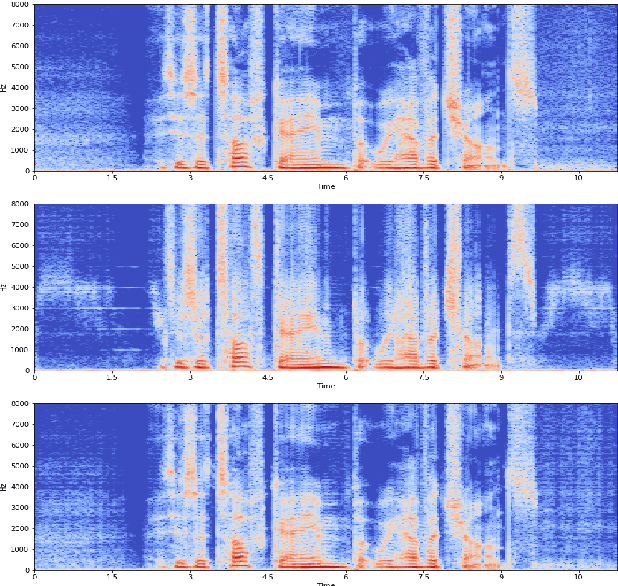
Classical parametric speech coding techniques provide a compact representation for speech signals. This affords a very low transmission rate but with a reduced perceptual quality of the reconstructed signals. Recently, autoregressive deep generative models such as WaveNet and SampleRNN have been used as speech vocoders to scale up the perceptual quality of the reconstructed signals without increasing the coding rate. However, such models suffer from a very slow signal generation mechanism due to their sample-by-sample modelling approach. In this work, we introduce a new methodology for neural speech vocoding based on generative adversarial networks (GANs). A fake speech signal is generated from a very compressed representation of the glottal excitation using conditional GANs as a deep generative model. This fake speech is then refined using the LPC parameters of the original speech signal to obtain a natural reconstruction. The reconstructed speech waveforms based on this approach show a higher perceptual quality than the classical vocoder counterparts according to subjective and objective evaluation scores for a dataset of 30 male and female speakers. Moreover, the usage of GANs enables to generate signals in one-shot compared to autoregressive generative models. This makes GANs promising for exploration to implement high-quality neural vocoders.