 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Affect-Adaptive Human-Robot Interaction: A Protocol for Multimodal Dataset Collection on Social Anxiety
Nov 17, 2025
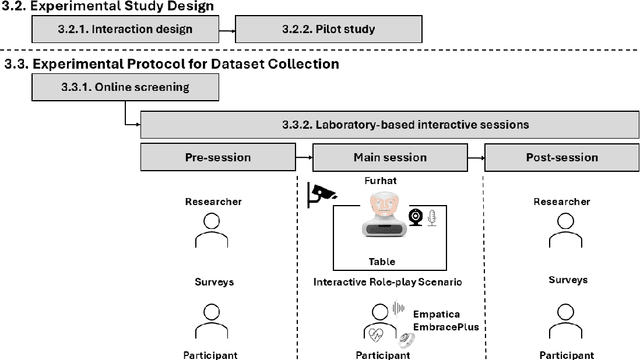

Social anxiety is a prevalent condition that affects interpersonal interactions and social functioning. Recent advances in artificial intelligence and social robotics offer new opportunities to examine social anxiety in the human-robot interaction context. Accurate detection of affective states and behaviours associated with social anxiety requires multimodal datasets, where each signal modality provides complementary insights into its manifestations. However, such datasets remain scarce, limiting progress in both research and applications. To address this, this paper presents a protocol for multimodal dataset collection designed to reflect social anxiety in a human-robot interaction context. The dataset will consist of synchronised audio, video, and physiological recordings acquired from at least 70 participants, grouped according to their level of social anxiety, as they engage in approximately 10-minute interactive Wizard-of-Oz role-play scenarios with the Furhat social robot under controlled experimental conditions. In addition to multimodal data, the dataset will be enriched with contextual data providing deeper insight into individual variability in social anxiety responses. This work can contribute to research on affect-adaptive human-robot interaction by providing support for robust multimodal detection of social anxiety.
Value Elicitation for a Socially Assistive Robot Addressing Social Anxiety: A Participatory Design Approach
Nov 05, 2025Social anxiety is a prevalent mental health condition that can significantly impact overall well-being and quality of life. Despite its widespread effects, adequate support or treatment for social anxiety is often insufficient. Advances in technology, particularly in social robotics, offer promising opportunities to complement traditional mental health. As an initial step toward developing effective solutions, it is essential to understand the values that shape what is considered meaningful, acceptable, and helpful. In this study, a participatory design workshop was conducted with mental health academic researchers to elicit the underlying values that should inform the design of socially assistive robots for social anxiety support. Through creative, reflective, and envisioning activities, participants explored scenarios and design possibilities, allowing for systematic elicitation of values, expectations, needs, and preferences related to robot-supported interventions. The findings reveal rich insights into design-relevant values-including adaptivity, acceptance, and efficacy-that are core to support for individuals with social anxiety. This study highlights the significance of a research-led approach to value elicitation, emphasising user-centred and context-aware design considerations in the development of socially assistive robots.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021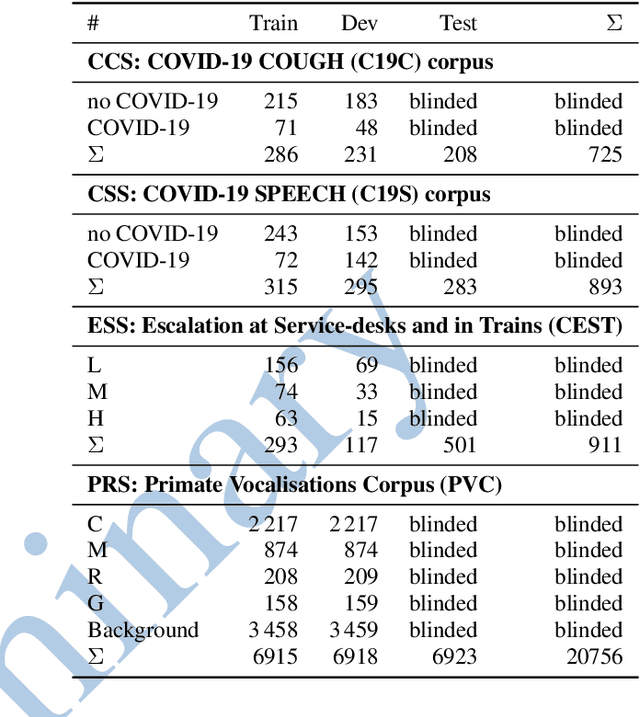
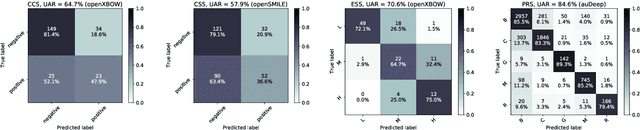
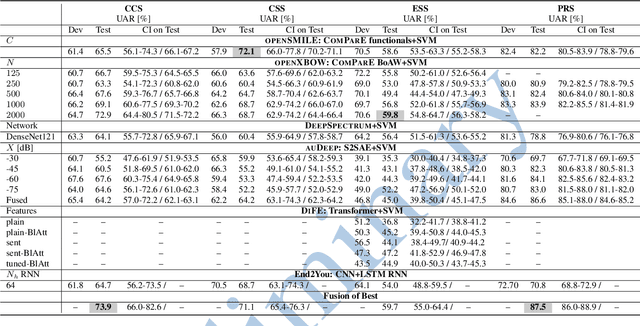
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
MuSe 2020 -- The First International Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop
Apr 30, 2020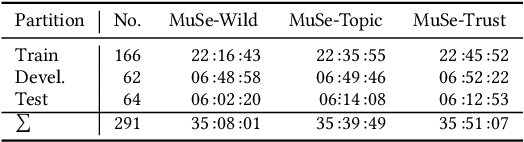
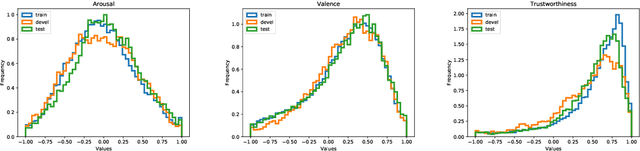
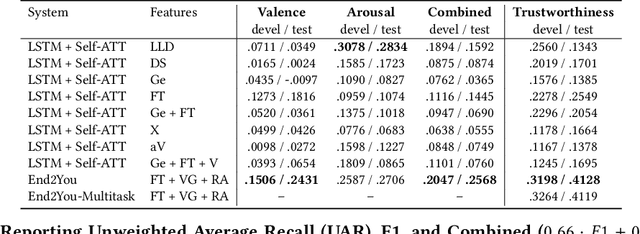
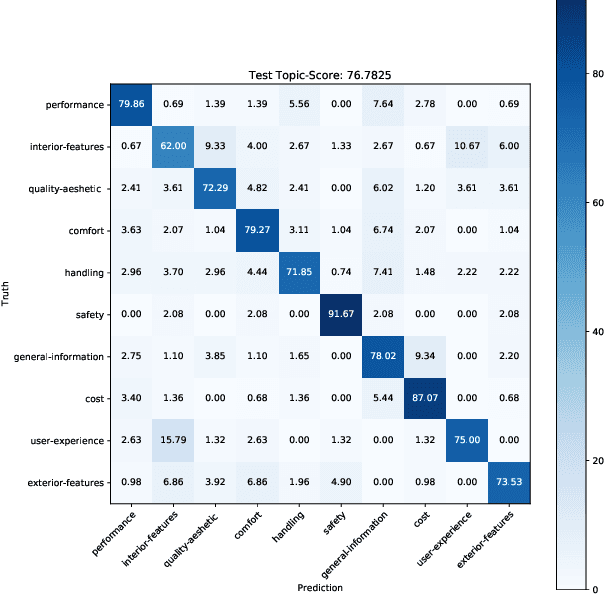
Multimodal Sentiment Analysis in Real-life Media (MuSe) 2020 is a Challenge-based Workshop focusing on the tasks of sentiment recognition, as well as emotion-target engagement and trustworthiness detection by means of more comprehensively integrating the audio-visual and language modalities. The purpose of MuSe 2020 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), and the sentiment analysis community (symbol-based). We present three distinct sub-challenges: MuSe-Wild, which focuses on continuous emotion (arousal and valence) prediction; MuSe-Topic, in which participants recognise domain-specific topics as the target of 3-class (low, medium, high) emotions; and MuSe-Trust, in which the novel aspect of trustworthiness is to be predicted. In this paper, we provide detailed information on MuSe-CaR, the first of its kind in-the-wild database, which is utilised for the challenge, as well as the state-of-the-art features and modelling approaches applied. For each sub-challenge, a competitive baseline for participants is set; namely, on test we report for MuSe-Wild a combined (valence and arousal) CCC of .2568, for MuSe-Topic a score (computed as 0.34$\cdot$ UAR + 0.66$\cdot$F1) of 76.78 % on the 10-class topic and 40.64 % on the 3-class emotion prediction, and for MuSe-Trust a CCC of .4359.