 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physiologically-Adapted Gold Standard for Arousal during Stress
Jul 28, 2021
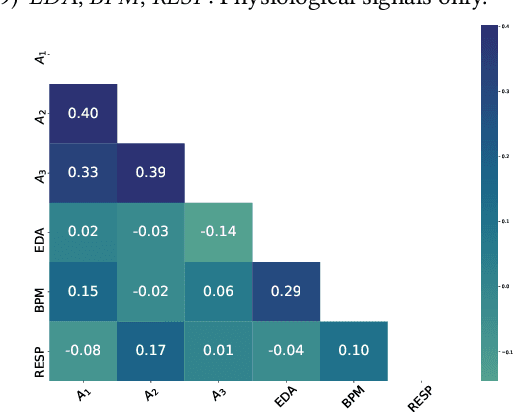
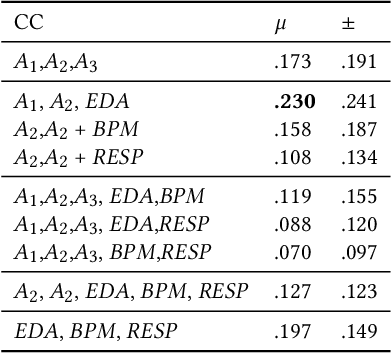
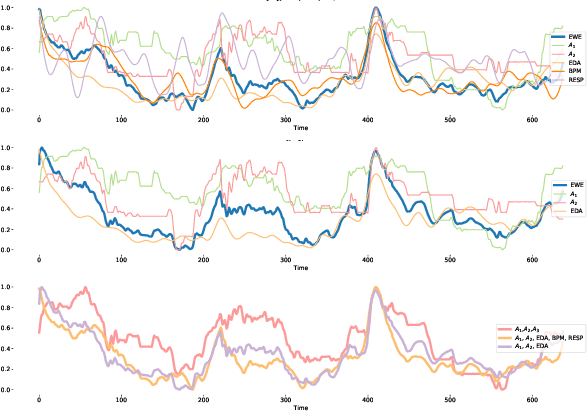
Emotion is an inherently subjective psychophysiological human-state and to produce an agreed-upon representation (gold standard) for continuous emotion requires a time-consuming and costly training procedure of multiple human annotators. There is strong evidence in the literature that physiological signals are sufficient objective markers for states of emotion, particularly arousal. In this contribution, we utilise a dataset which includes continuous emotion and physiological signals - Heartbeats per Minute (BPM), Electrodermal Activity (EDA), and Respiration-rate - captured during a stress inducing scenario (Trier Social Stress Test). We utilise a Long Short-Term Memory, Recurrent Neural Network to explore the benefit of fusing these physiological signals with arousal as the target, learning from various audio, video, and textual based features. We utilise the state-of-the-art MuSe-Toolbox to consider both annotation delay and inter-rater agreement weighting when fusing the target signals. An improvement in Concordance Correlation Coefficient (CCC) is seen across features sets when fusing EDA with arousal, compared to the arousal only gold standard results. Additionally, BERT-based textual features' results improved for arousal plus all physiological signals, obtaining up to .3344 CCC compared to .2118 CCC for arousal only. Multimodal fusion also improves overall CCC with audio plus video features obtaining up to .6157 CCC to recognize arousal plus EDA and BPM.
MuSe-Toolbox: The Multimodal Sentiment Analysis Continuous Annotation Fusion and Discrete Class Transformation Toolbox
Jul 25, 2021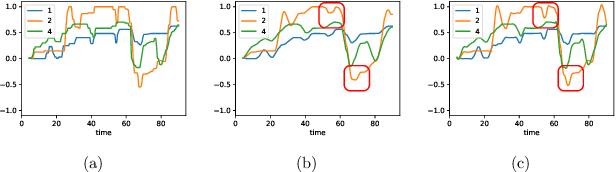
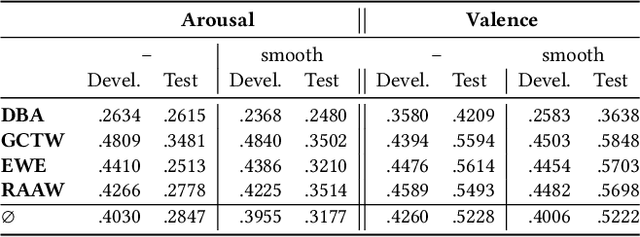


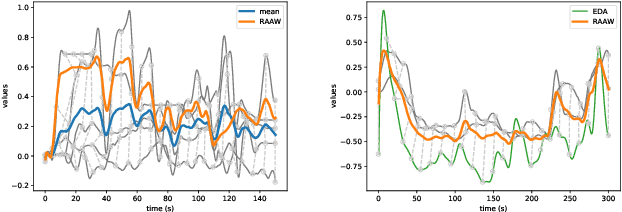
We introduce the MuSe-Toolbox - a Python-based open-source toolkit for creating a variety of continuous and discrete emotion gold standards. In a single framework, we unify a wide range of fusion methods and propose the novel Rater Aligned Annotation Weighting (RAAW), which aligns the annotations in a translation-invariant way before weighting and fusing them based on the inter-rater agreements between the annotations. Furthermore, discrete categories tend to be easier for humans to interpret than continuous signals. With this in mind, the MuSe-Toolbox provides the functionality to run exhaustive searches for meaningful class clusters in the continuous gold standards. To our knowledge, this is the first toolkit that provides a wide selection of state-of-the-art emotional gold standard methods and their transformation to discrete classes. Experimental results indicate that MuSe-Toolbox can provide promising and novel class formations which can be better predicted than hard-coded classes boundaries with minimal human intervention. The implementation (1) is out-of-the-box available with all dependencies using a Docker container (2).
The MuSe 2021 Multimodal Sentiment Analysis Challenge: Sentiment, Emotion, Physiological-Emotion, and Stress
Apr 14, 2021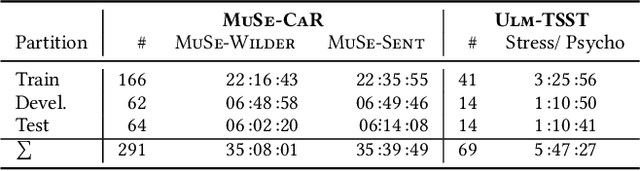

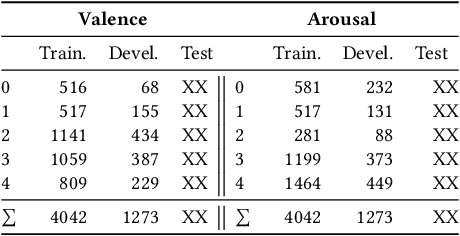
Multimodal Sentiment Analysis (MuSe) 2021 is a challenge focusing on the tasks of sentiment and emotion, as well as physiological-emotion and emotion-based stress recognition through more comprehensively integrating the audio-visual, language, and biological signal modalities. The purpose of MuSe 2021 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), the sentiment analysis community (symbol-based), and the health informatics community. We present four distinct sub-challenges: MuSe-Wilder and MuSe-Stress which focus on continuous emotion (valence and arousal) prediction; MuSe-Sent, in which participants recognise five classes each for valence and arousal; and MuSe-Physio, in which the novel aspect of `physiological-emotion' is to be predicted. For this years' challenge, we utilise the MuSe-CaR dataset focusing on user-generated reviews and introduce the Ulm-TSST dataset, which displays people in stressful depositions. This paper also provides detail on the state-of-the-art feature sets extracted from these datasets for utilisation by our baseline model, a Long Short-Term Memory-Recurrent Neural Network. For each sub-challenge, a competitive baseline for participants is set; namely, on test, we report a Concordance Correlation Coefficient (CCC) of .4616 CCC for MuSe-Wilder; .4717 CCC for MuSe-Stress, and .4606 CCC for MuSe-Physio. For MuSe-Sent an F1 score of 32.82 % is obtained.
The Multimodal Sentiment Analysis in Car Reviews (MuSe-CaR) Dataset: Collection, Insights and Improvements
Jan 15, 2021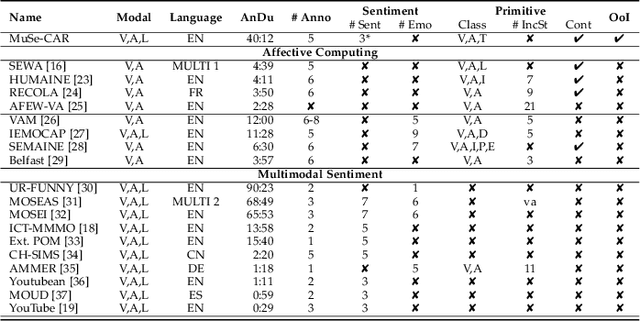


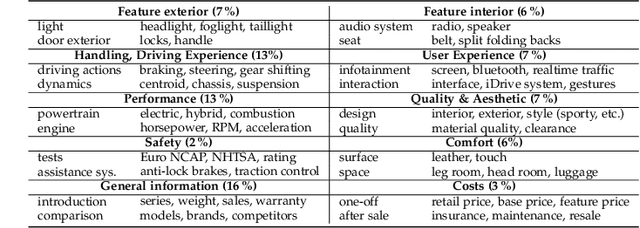
Truly real-life data presents a strong, but exciting challenge for sentiment and emotion research. The high variety of possible `in-the-wild' properties makes large datasets such as these indispensable with respect to building robust machine learning models. A sufficient quantity of data covering a deep variety in the challenges of each modality to force the exploratory analysis of the interplay of all modalities has not yet been made available in this context. In this contribution, we present MuSe-CaR, a first of its kind multimodal dataset. The data is publicly available as it recently served as the testing bed for the 1st Multimodal Sentiment Analysis Challenge, and focused on the tasks of emotion, emotion-target engagement, and trustworthiness recognition by means of comprehensively integrating the audio-visual and language modalities. Furthermore, we give a thorough overview of the dataset in terms of collection and annotation, including annotation tiers not used in this year's MuSe 2020. In addition, for one of the sub-challenges - predicting the level of trustworthiness - no participant outperformed the baseline model, and so we propose a simple, but highly efficient Multi-Head-Attention network that exceeds using multimodal fusion the baseline by around 0.2 CCC (almost 50 % improvement).
MuSe 2020 -- The First International Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop
Apr 30, 2020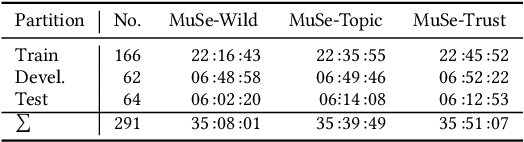
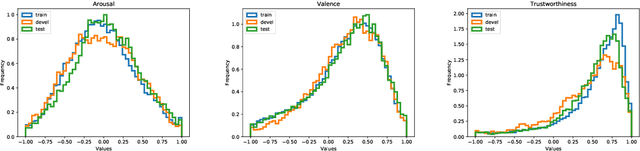
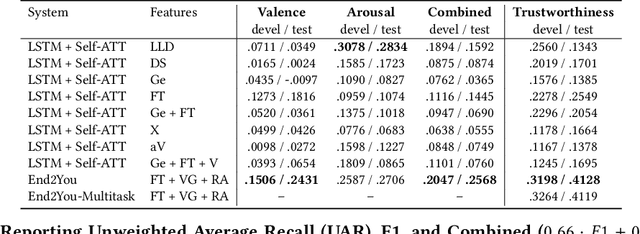
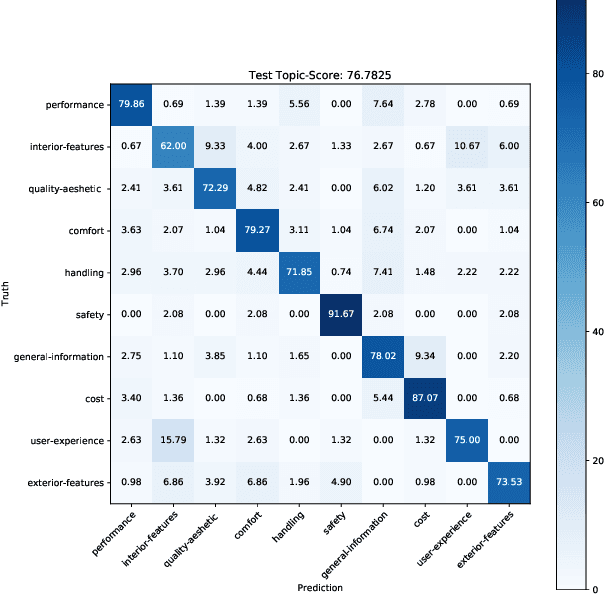
Multimodal Sentiment Analysis in Real-life Media (MuSe) 2020 is a Challenge-based Workshop focusing on the tasks of sentiment recognition, as well as emotion-target engagement and trustworthiness detection by means of more comprehensively integrating the audio-visual and language modalities. The purpose of MuSe 2020 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), and the sentiment analysis community (symbol-based). We present three distinct sub-challenges: MuSe-Wild, which focuses on continuous emotion (arousal and valence) prediction; MuSe-Topic, in which participants recognise domain-specific topics as the target of 3-class (low, medium, high) emotions; and MuSe-Trust, in which the novel aspect of trustworthiness is to be predicted. In this paper, we provide detailed information on MuSe-CaR, the first of its kind in-the-wild database, which is utilised for the challenge, as well as the state-of-the-art features and modelling approaches applied. For each sub-challenge, a competitive baseline for participants is set; namely, on test we report for MuSe-Wild a combined (valence and arousal) CCC of .2568, for MuSe-Topic a score (computed as 0.34$\cdot$ UAR + 0.66$\cdot$F1) of 76.78 % on the 10-class topic and 40.64 % on the 3-class emotion prediction, and for MuSe-Trust a CCC of .4359.