 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSe-Toolbox: The Multimodal Sentiment Analysis Continuous Annotation Fusion and Discrete Class Transformation Toolbox
Jul 25, 2021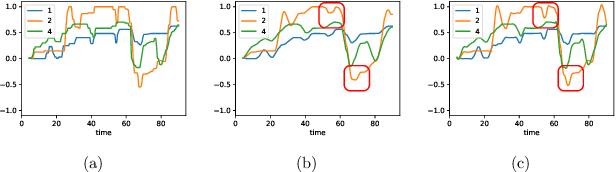
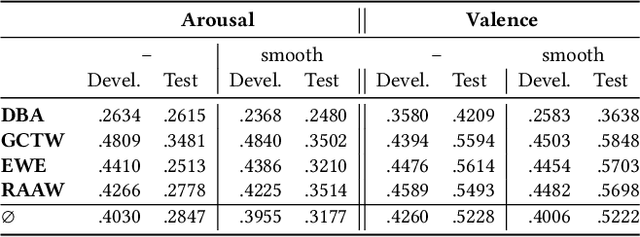


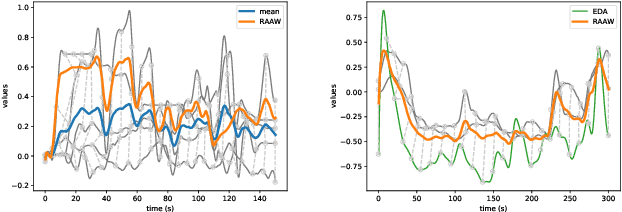
We introduce the MuSe-Toolbox - a Python-based open-source toolkit for creating a variety of continuous and discrete emotion gold standards. In a single framework, we unify a wide range of fusion methods and propose the novel Rater Aligned Annotation Weighting (RAAW), which aligns the annotations in a translation-invariant way before weighting and fusing them based on the inter-rater agreements between the annotations. Furthermore, discrete categories tend to be easier for humans to interpret than continuous signals. With this in mind, the MuSe-Toolbox provides the functionality to run exhaustive searches for meaningful class clusters in the continuous gold standards. To our knowledge, this is the first toolkit that provides a wide selection of state-of-the-art emotional gold standard methods and their transformation to discrete classes. Experimental results indicate that MuSe-Toolbox can provide promising and novel class formations which can be better predicted than hard-coded classes boundaries with minimal human intervention. The implementation (1) is out-of-the-box available with all dependencies using a Docker container (2).
The MuSe 2021 Multimodal Sentiment Analysis Challenge: Sentiment, Emotion, Physiological-Emotion, and Stress
Apr 14, 2021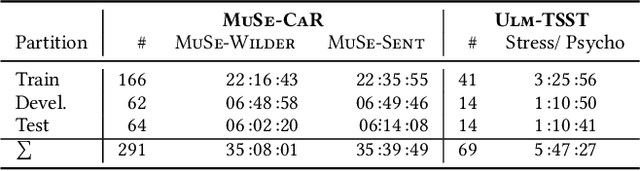

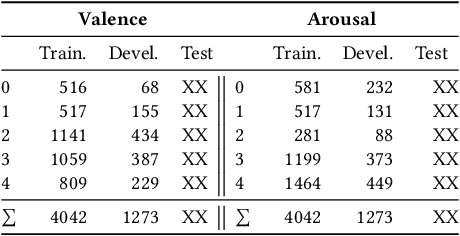
Multimodal Sentiment Analysis (MuSe) 2021 is a challenge focusing on the tasks of sentiment and emotion, as well as physiological-emotion and emotion-based stress recognition through more comprehensively integrating the audio-visual, language, and biological signal modalities. The purpose of MuSe 2021 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), the sentiment analysis community (symbol-based), and the health informatics community. We present four distinct sub-challenges: MuSe-Wilder and MuSe-Stress which focus on continuous emotion (valence and arousal) prediction; MuSe-Sent, in which participants recognise five classes each for valence and arousal; and MuSe-Physio, in which the novel aspect of `physiological-emotion' is to be predicted. For this years' challenge, we utilise the MuSe-CaR dataset focusing on user-generated reviews and introduce the Ulm-TSST dataset, which displays people in stressful depositions. This paper also provides detail on the state-of-the-art feature sets extracted from these datasets for utilisation by our baseline model, a Long Short-Term Memory-Recurrent Neural Network. For each sub-challenge, a competitive baseline for participants is set; namely, on test, we report a Concordance Correlation Coefficient (CCC) of .4616 CCC for MuSe-Wilder; .4717 CCC for MuSe-Stress, and .4606 CCC for MuSe-Physio. For MuSe-Sent an F1 score of 32.82 % is obtained.