 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeanTTA: A Backpropagation-Free and Stateless Approach to Quantized Test-Time Adaptation on Edge Devices
Mar 20, 2025While there are many advantages to deploying machine learning models on edge devices, the resource constraints of mobile platforms, the dynamic nature of the environment, and differences between the distribution of training versus in-the-wild data make such deployments challenging. Current test-time adaptation methods are often memory-intensive and not designed to be quantization-compatible or deployed on low-resource devices. To address these challenges, we present LeanTTA, a novel backpropagation-free and stateless framework for quantized test-time adaptation tailored to edge devices. Our approach minimizes computational costs by dynamically updating normalization statistics without backpropagation, which frees LeanTTA from the common pitfall of relying on large batches and historical data, making our method robust to realistic deployment scenarios. Our approach is the first to enable further computational gains by combining partial adaptation with quantized module fusion. We validate our framework across sensor modalities, demonstrating significant improvements over state-of-the-art TTA methods, including a 15.7% error reduction, peak memory usage of only 11.2MB for ResNet18, and fast adaptation within an order-of-magnitude of normal inference speeds on-device. LeanTTA provides a robust solution for achieving the right trade offs between accuracy and system efficiency in edge deployments, addressing the unique challenges posed by limited data and varied operational conditions.
Towards Open Respiratory Acoustic Foundation Models: Pretraining and Benchmarking
Jun 23, 2024



Respiratory audio, such as coughing and breathing sounds, has predictive power for a wide range of healthcare applications, yet is currently under-explored. The main problem for those applications arises from the difficulty in collecting large labeled task-specific data for model development. Generalizable respiratory acoustic foundation models pretrained with unlabeled data would offer appealing advantages and possibly unlock this impasse. However, given the safety-critical nature of healthcare applications, it is pivotal to also ensure openness and replicability for any proposed foundation model solution. To this end, we introduce OPERA, an OPEn Respiratory Acoustic foundation model pretraining and benchmarking system, as the first approach answering this need. We curate large-scale respiratory audio datasets (~136K samples, 440 hours), pretrain three pioneering foundation models, and build a benchmark consisting of 19 downstream respiratory health tasks for evaluation. Our pretrained models demonstrate superior performance (against existing acoustic models pretrained with general audio on 16 out of 19 tasks) and generalizability (to unseen datasets and new respiratory audio modalities). This highlights the great promise of respiratory acoustic foundation models and encourages more studies using OPERA as an open resource to accelerate research on respiratory audio for health. The system is accessible from https://github.com/evelyn0414/OPERA.
Propagating Variational Model Uncertainty for Bioacoustic Call Label Smoothing
Oct 19, 2022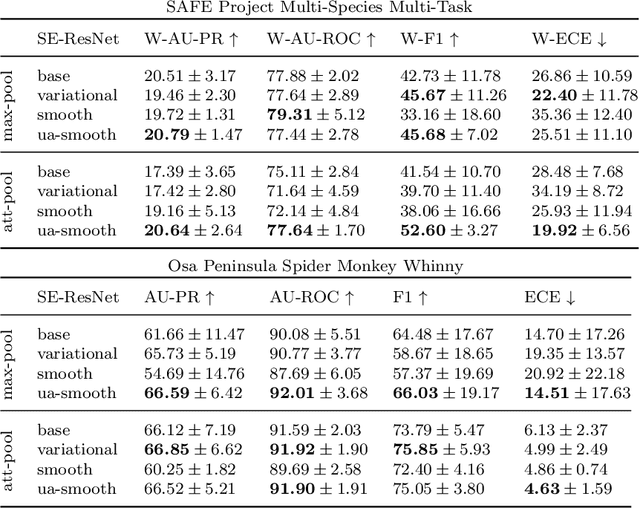


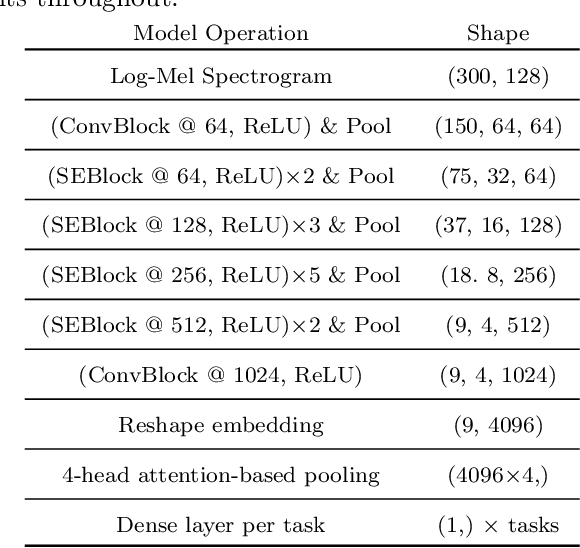
We focus on using the predictive uncertainty signal calculated by Bayesian neural networks to guide learning in the self-same task the model is being trained on. Not opting for costly Monte Carlo sampling of weights, we propagate the approximate hidden variance in an end-to-end manner, throughout a variational Bayesian adaptation of a ResNet with attention and squeeze-and-excitation blocks, in order to identify data samples that should contribute less into the loss value calculation. We, thus, propose uncertainty-aware, data-specific label smoothing, where the smoothing probability is dependent on this epistemic uncertainty. We show that, through the explicit usage of the epistemic uncertainty in the loss calculation, the variational model is led to improved predictive and calibration performance. This core machine learning methodology is exemplified at wildlife call detection, from audio recordings made via passive acoustic monitoring equipment in the animals' natural habitats, with the future goal of automating large scale annotation in a trustworthy manner.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021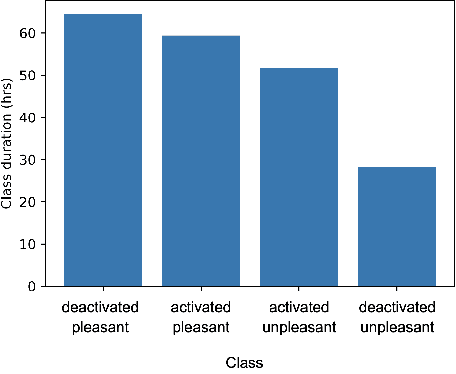
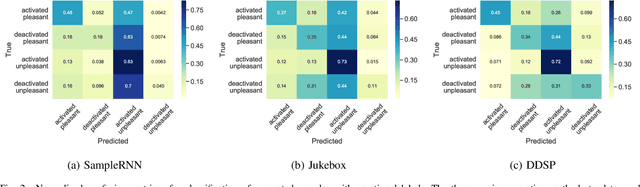
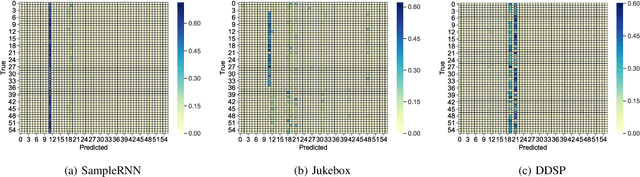
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
An Improved StarGAN for Emotional Voice Conversion: Enhancing Voice Quality and Data Augmentation
Jul 18, 2021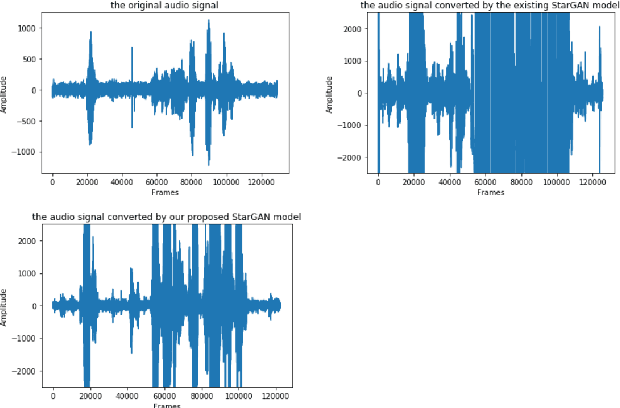



Emotional Voice Conversion (EVC) aims to convert the emotional style of a source speech signal to a target style while preserving its content and speaker identity information. Previous emotional conversion studies do not disentangle emotional information from emotion-independent information that should be preserved, thus transforming it all in a monolithic manner and generating audio of low quality, with linguistic distortions. To address this distortion problem, we propose a novel StarGAN framework along with a two-stage training process that separates emotional features from those independent of emotion by using an autoencoder with two encoders as the generator of the Generative Adversarial Network (GAN). The proposed model achieves favourable results in both the objective evaluation and the subjective evaluation in terms of distortion, which reveals that the proposed model can effectively reduce distortion. Furthermore, in data augmentation experiments for end-to-end speech emotion recognition, the proposed StarGAN model achieves an increase of 2% in Micro-F1 and 5% in Macro-F1 compared to the baseline StarGAN model, which indicates that the proposed model is more valuable for data augmentation.
What Makes a Scientific Paper be Accepted for Publication?
Apr 14, 2021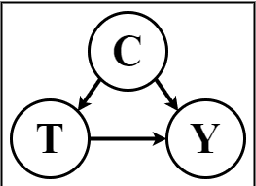
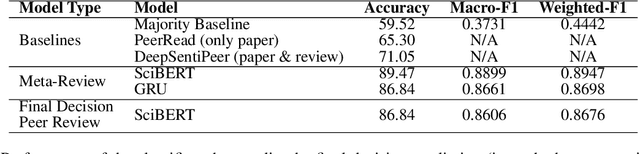

Despite peer-reviewing being an essential component of academia since the 1600s, it has repeatedly received criticisms for lack of transparency and consistency. We posit that recent work in machine learning and explainable AI provide tools that enable insights into the decisions from a given peer review process. We start by extracting global explanations in the form of linguistic features that affect the acceptance of a scientific paper for publication on an open peer-review dataset. Second, since such global explanations do not justify causal interpretations, we provide a methodology for detecting confounding effects in natural language in order to generate causal explanations, under assumptions, in the form of lexicons. Our proposed linguistic explanation methodology indicates the following on a case dataset of ICLR submissions: a) the organising committee follows, for the most part, the recommendations of reviewers, and, b) the paper's main characteristics that led to reviewers recommending acceptance for publication are originality, clarity and substance.
MuSe 2020 -- The First International Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop
Apr 30, 2020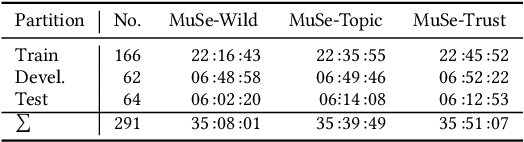
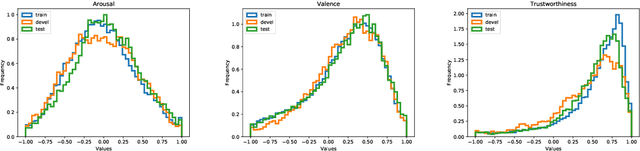
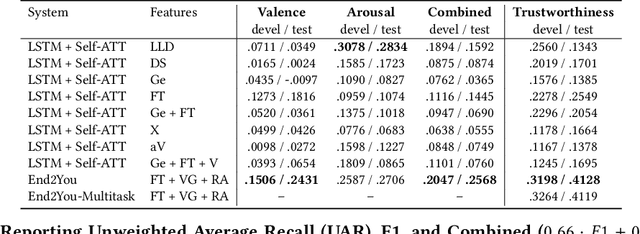
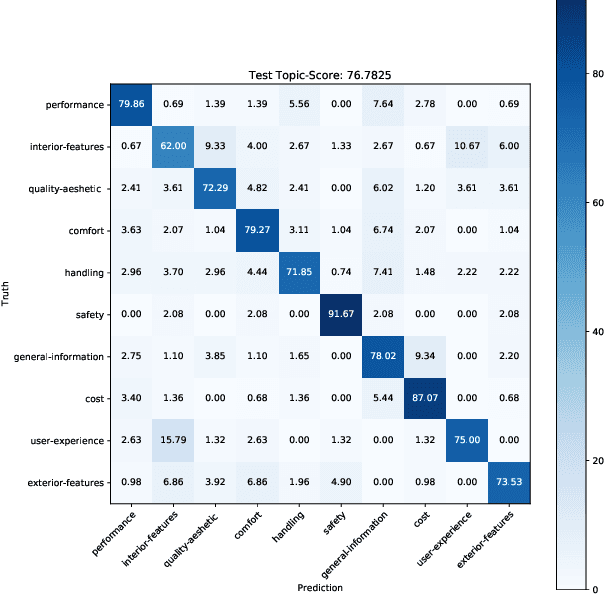
Multimodal Sentiment Analysis in Real-life Media (MuSe) 2020 is a Challenge-based Workshop focusing on the tasks of sentiment recognition, as well as emotion-target engagement and trustworthiness detection by means of more comprehensively integrating the audio-visual and language modalities. The purpose of MuSe 2020 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), and the sentiment analysis community (symbol-based). We present three distinct sub-challenges: MuSe-Wild, which focuses on continuous emotion (arousal and valence) prediction; MuSe-Topic, in which participants recognise domain-specific topics as the target of 3-class (low, medium, high) emotions; and MuSe-Trust, in which the novel aspect of trustworthiness is to be predicted. In this paper, we provide detailed information on MuSe-CaR, the first of its kind in-the-wild database, which is utilised for the challenge, as well as the state-of-the-art features and modelling approaches applied. For each sub-challenge, a competitive baseline for participants is set; namely, on test we report for MuSe-Wild a combined (valence and arousal) CCC of .2568, for MuSe-Topic a score (computed as 0.34$\cdot$ UAR + 0.66$\cdot$F1) of 76.78 % on the 10-class topic and 40.64 % on the 3-class emotion prediction, and for MuSe-Trust a CCC of .4359.
Poisson CNN: Convolutional Neural Networks for the Solution of the Poisson Equation with Varying Meshes and Dirichlet Boundary Conditions
Oct 18, 2019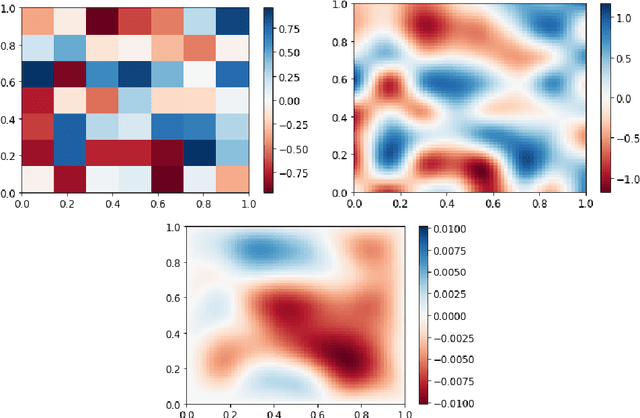

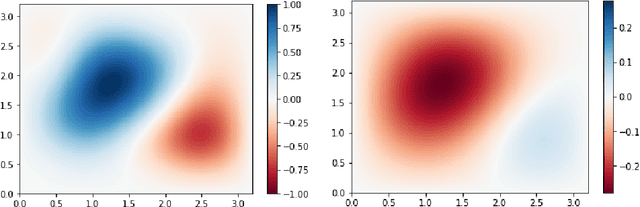

The Poisson equation is commonly encountered in engineering, including in computational fluid dynamics where it is needed to compute corrections to the pressure field. We propose a novel fully convolutional neural network (CNN) architecture to infer the solution of the Poisson equation on a 2D Cartesian grid of varying size and spacing given the right hand side term, arbitrary Dirichlet boundary conditions and grid parameters which provides unprecendented versatility in this application. The boundary conditions are handled using a novel approach by decomposing the original Poisson problem into a homogeneous Poisson problem plus four inhomogeneous Laplace sub-problems. The model is trained using a novel loss function approximating the continuous $L^p$ norm between the prediction and the target. Analytical test cases indicate that our CNN architecture is capable of predicting the correct solution of a Poisson problem with mean percentage errors of 15% and promises improvements in wall-clock runtimes for large problems. Furthermore, even when predicting on meshes denser than previously encountered, our model demonstrates encouraging capacity to reproduce the correct solution profile.