 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
A Physiologically-Adapted Gold Standard for Arousal during Stress
Jul 28, 2021
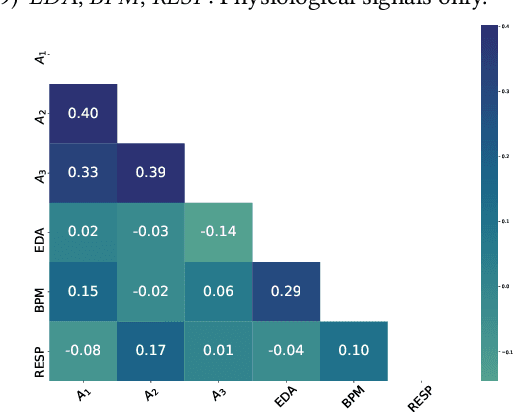
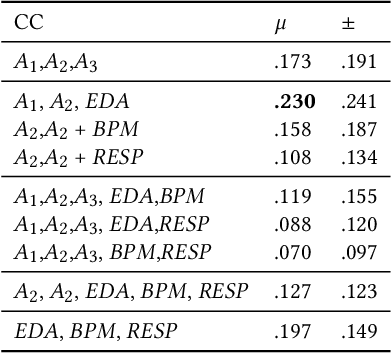
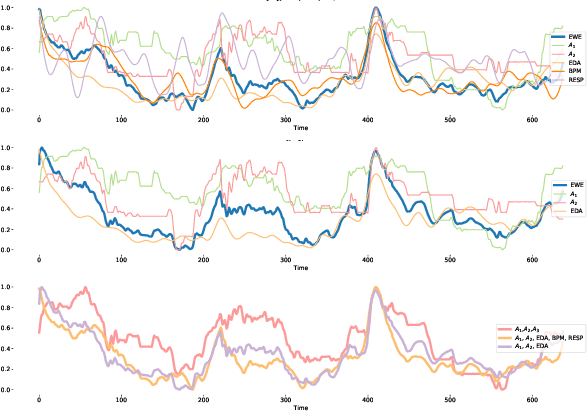
Emotion is an inherently subjective psychophysiological human-state and to produce an agreed-upon representation (gold standard) for continuous emotion requires a time-consuming and costly training procedure of multiple human annotators. There is strong evidence in the literature that physiological signals are sufficient objective markers for states of emotion, particularly arousal. In this contribution, we utilise a dataset which includes continuous emotion and physiological signals - Heartbeats per Minute (BPM), Electrodermal Activity (EDA), and Respiration-rate - captured during a stress inducing scenario (Trier Social Stress Test). We utilise a Long Short-Term Memory, Recurrent Neural Network to explore the benefit of fusing these physiological signals with arousal as the target, learning from various audio, video, and textual based features. We utilise the state-of-the-art MuSe-Toolbox to consider both annotation delay and inter-rater agreement weighting when fusing the target signals. An improvement in Concordance Correlation Coefficient (CCC) is seen across features sets when fusing EDA with arousal, compared to the arousal only gold standard results. Additionally, BERT-based textual features' results improved for arousal plus all physiological signals, obtaining up to .3344 CCC compared to .2118 CCC for arousal only. Multimodal fusion also improves overall CCC with audio plus video features obtaining up to .6157 CCC to recognize arousal plus EDA and BPM.