 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a foundation model for high-resolution remote sensing data of the Netherlands
May 11, 2026We develop a foundation model using 1.2m high resolution satellite images of the Netherlands. By combining a Convolutional Neural Network and a Vision Transformer, the model captures both low- and high-frequency landscape features, such as fine textures, edges, and small objects as well as large terrain structures, elevation patterns, and land-cover distributions. Leveraging temporal data as input, the model learns from broader contextual information across time, allowing the model to exploit the temporal dependencies, such as topographic features, land-cover changes, and seasonal dynamics. These additional constraints reduce feature ambiguity, improve representation learning, and enable better generalization with fewer labeled samples. The foundation model is evaluated on multiple downstream tasks, ranging from use cases within the Netherlands to global benchmarking datasets. On the vegetation monitoring dataset of the Netherlands, the model shows clear performance improvements by incorporating temporal information instead of relying on a single time point. Despite using a smaller model and less pretraining data limited to the Netherlands, it achieves competitive results on global benchmarks when compared to state-of-the-art models. These results demonstrate that the model can learn rich, generalizable representations from limited data, achieving competitive performance on global benchmarks while using a fraction of the parameters of larger state-of-the-art remote sensing models. To maximize reproducibility and reuse, we made the scripts and the model accessible on GitHub.
Audio-Visual Compound Expression Recognition Method based on Late Modality Fusion and Rule-based Decision
Mar 29, 2024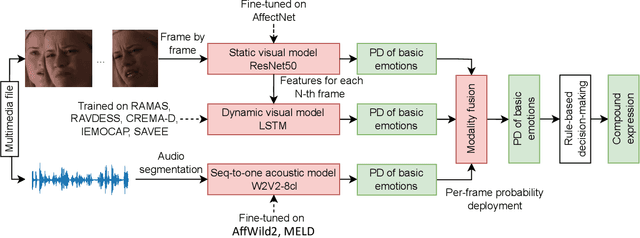
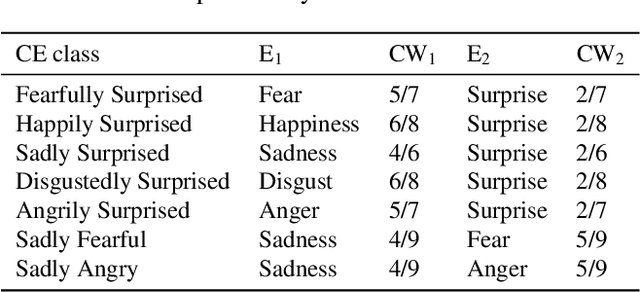
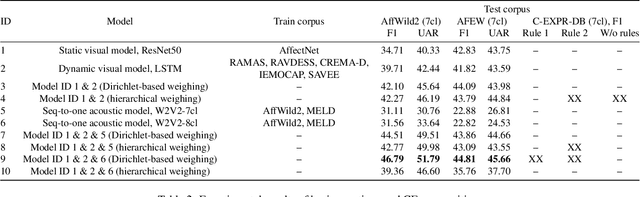
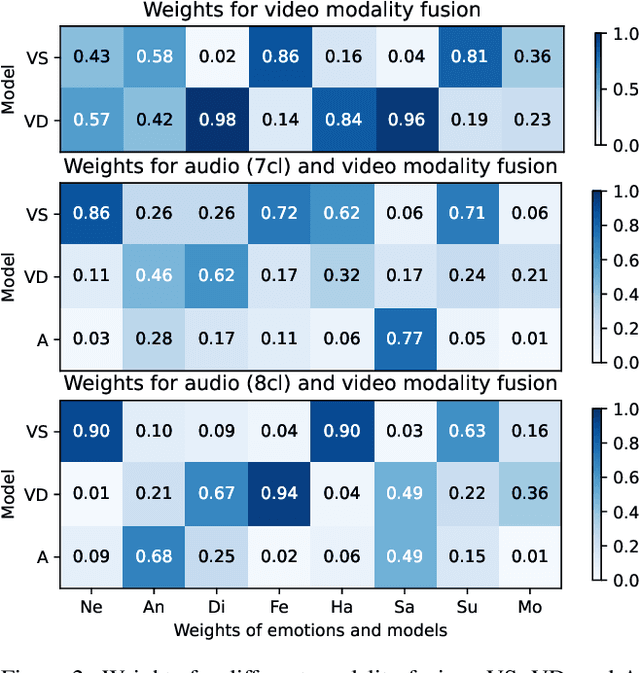
This paper presents the results of the SUN team for the Compound Expressions Recognition Challenge of the 6th ABAW Competition. We propose a novel audio-visual method for compound expression recognition. Our method relies on emotion recognition models that fuse modalities at the emotion probability level, while decisions regarding the prediction of compound expressions are based on predefined rules. Notably, our method does not use any training data specific to the target task. Thus, the problem is a zero-shot classification task. The method is evaluated in multi-corpus training and cross-corpus validation setups. Using our proposed method is achieved an F1-score value equals to 22.01% on the C-EXPR-DB test subset. Our findings from the challenge demonstrate that the proposed method can potentially form a basis for developing intelligent tools for annotating audio-visual data in the context of human's basic and compound emotions.
SUN Team's Contribution to ABAW 2024 Competition: Audio-visual Valence-Arousal Estimation and Expression Recognition
Mar 19, 2024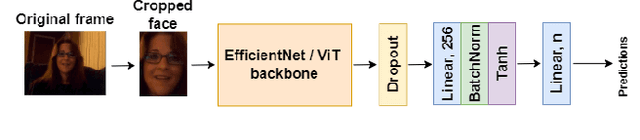
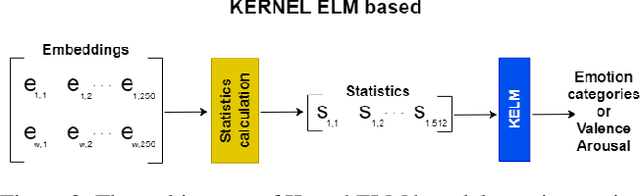
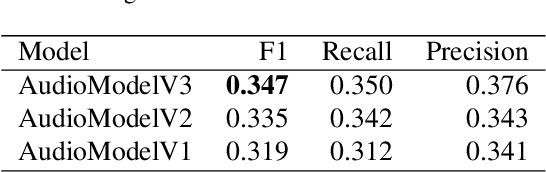
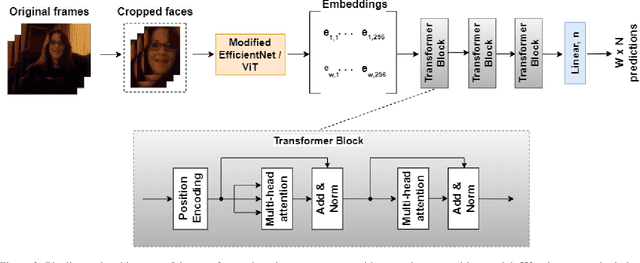
As emotions play a central role in human communication, automatic emotion recognition has attracted increasing attention in the last two decades. While multimodal systems enjoy high performances on lab-controlled data, they are still far from providing ecological validity on non-lab-controlled, namely 'in-the-wild' data. This work investigates audiovisual deep learning approaches for emotion recognition in-the-wild problem. We particularly explore the effectiveness of architectures based on fine-tuned Convolutional Neural Networks (CNN) and Public Dimensional Emotion Model (PDEM), for video and audio modality, respectively. We compare alternative temporal modeling and fusion strategies using the embeddings from these multi-stage trained modality-specific Deep Neural Networks (DNN). We report results on the AffWild2 dataset under Affective Behavior Analysis in-the-Wild 2024 (ABAW'24) challenge protocol.
Privacy Constrained Fairness Estimation for Decision Trees
Dec 13, 2023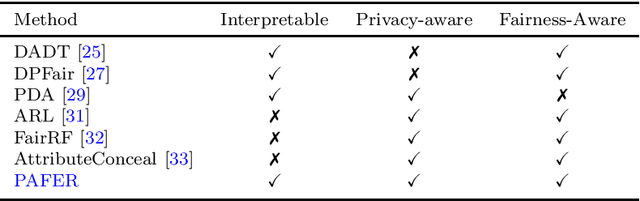
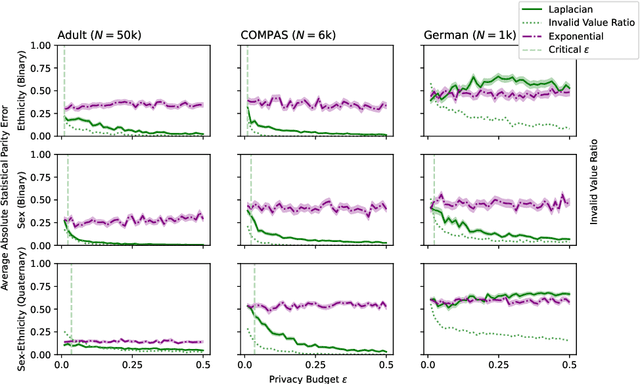


The protection of sensitive data becomes more vital, as data increases in value and potency. Furthermore, the pressure increases from regulators and society on model developers to make their Artificial Intelligence (AI) models non-discriminatory. To boot, there is a need for interpretable, transparent AI models for high-stakes tasks. In general, measuring the fairness of any AI model requires the sensitive attributes of the individuals in the dataset, thus raising privacy concerns. In this work, the trade-offs between fairness, privacy and interpretability are further explored. We specifically examine the Statistical Parity (SP) of Decision Trees (DTs) with Differential Privacy (DP), that are each popular methods in their respective subfield. We propose a novel method, dubbed Privacy-Aware Fairness Estimation of Rules (PAFER), that can estimate SP in a DP-aware manner for DTs. DP, making use of a third-party legal entity that securely holds this sensitive data, guarantees privacy by adding noise to the sensitive data. We experimentally compare several DP mechanisms. We show that using the Laplacian mechanism, the method is able to estimate SP with low error while guaranteeing the privacy of the individuals in the dataset with high certainty. We further show experimentally and theoretically that the method performs better for DTs that humans generally find easier to interpret.
The effects of gender bias in word embeddings on depression prediction
Dec 15, 2022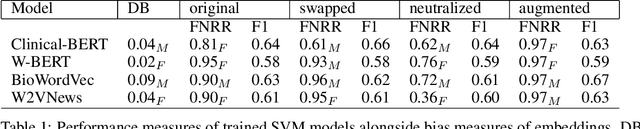
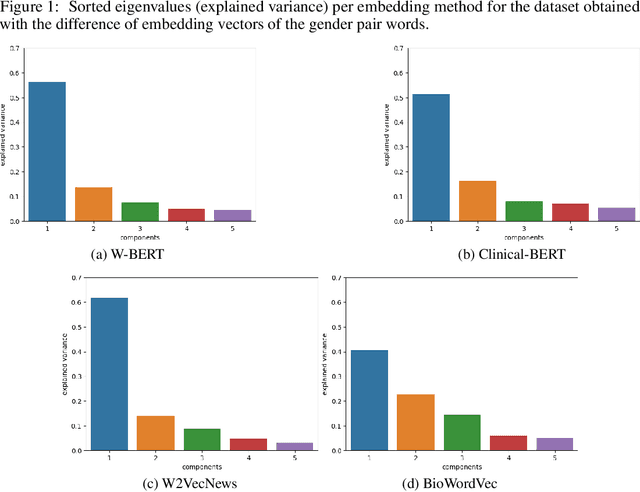
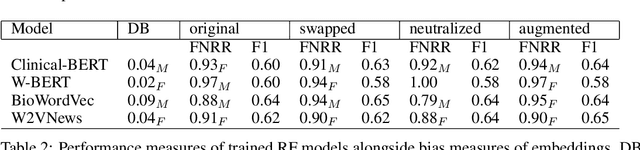
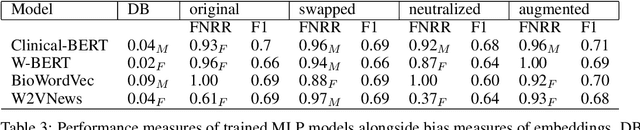
Word embeddings are extensively used in various NLP problems as a state-of-the-art semantic feature vector representation. Despite their success on various tasks and domains, they might exhibit an undesired bias for stereotypical categories due to statistical and societal biases that exist in the dataset they are trained on. In this study, we analyze the gender bias in four different pre-trained word embeddings specifically for the depression category in the mental disorder domain. We use contextual and non-contextual embeddings that are trained on domain-independent as well as clinical domain-specific data. We observe that embeddings carry bias for depression towards different gender groups depending on the type of embeddings. Moreover, we demonstrate that these undesired correlations are transferred to the downstream task for depression phenotype recognition. We find that data augmentation by simply swapping gender words mitigates the bias significantly in the downstream task.
Federated learning for violence incident prediction in a simulated cross-institutional psychiatric setting
May 17, 2022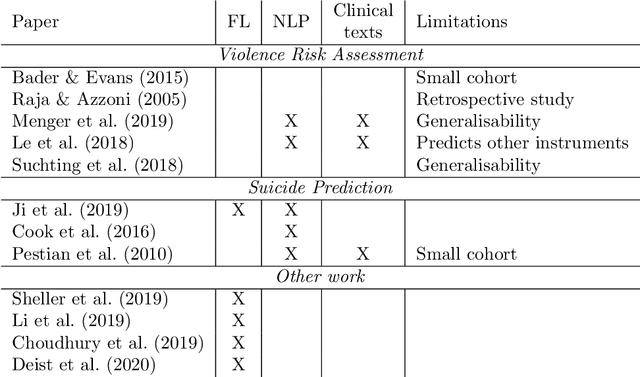
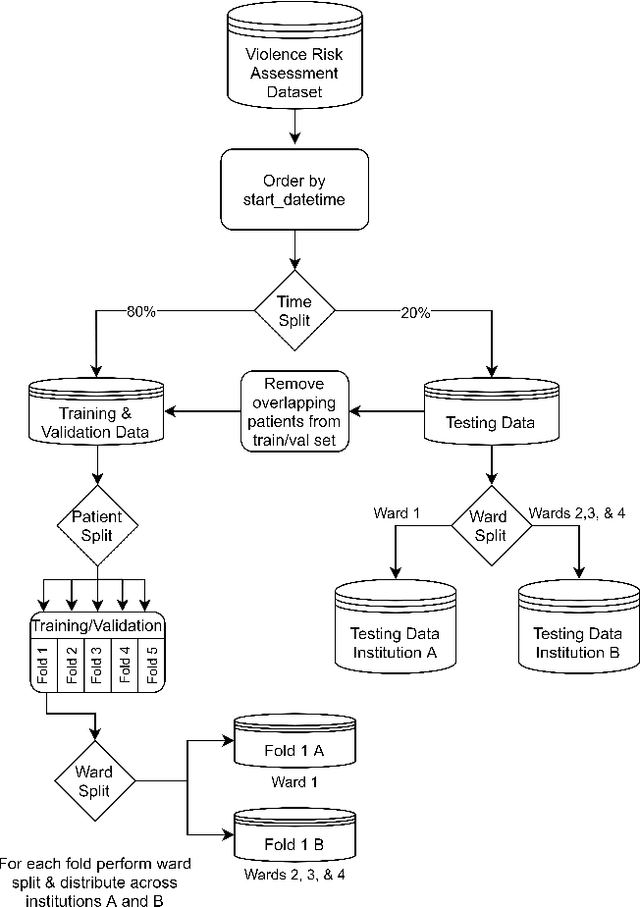

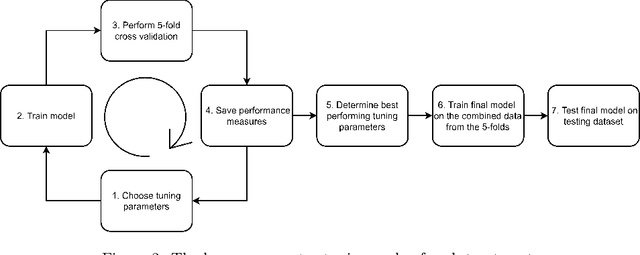
Inpatient violence is a common and severe problem within psychiatry. Knowing who might become violent can influence staffing levels and mitigate severity. Predictive machine learning models can assess each patient's likelihood of becoming violent based on clinical notes. Yet, while machine learning models benefit from having more data, data availability is limited as hospitals typically do not share their data for privacy preservation. Federated Learning (FL) can overcome the problem of data limitation by training models in a decentralised manner, without disclosing data between collaborators. However, although several FL approaches exist, none of these train Natural Language Processing models on clinical notes. In this work, we investigate the application of Federated Learning to clinical Natural Language Processing, applied to the task of Violence Risk Assessment by simulating a cross-institutional psychiatric setting. We train and compare four models: two local models, a federated model and a data-centralised model. Our results indicate that the federated model outperforms the local models and has similar performance as the data-centralised model. These findings suggest that Federated Learning can be used successfully in a cross-institutional setting and is a step towards new applications of Federated Learning based on clinical notes
Speech Analysis for Automatic Mania Assessment in Bipolar Disorder
Feb 05, 2022Bipolar disorder is a mental disorder that causes periods of manic and depressive episodes. In this work, we classify recordings from Bipolar Disorder corpus that contain 7 different tasks, into hypomania, mania, and remission classes using only speech features. We perform our experiments on splitted tasks from the interviews. Best results achieved on the model trained with 6th and 7th tasks together gives 0.53 UAR (unweighted average recall) result which is higher than the baseline results of the corpus.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021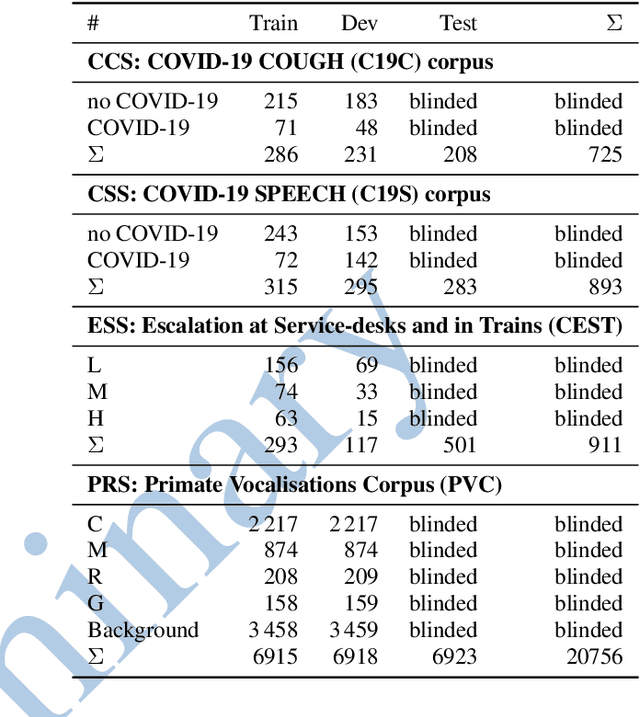
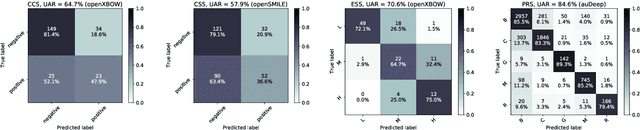
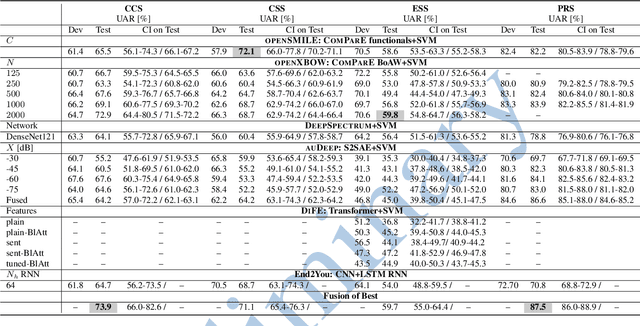
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
Introducing a Central African Primate Vocalisation Dataset for Automated Species Classification
Jan 25, 2021
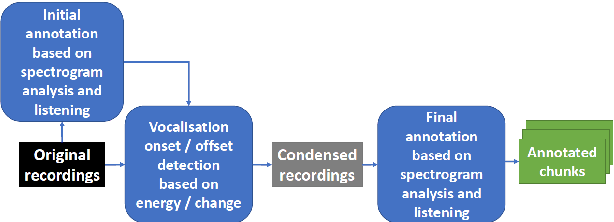
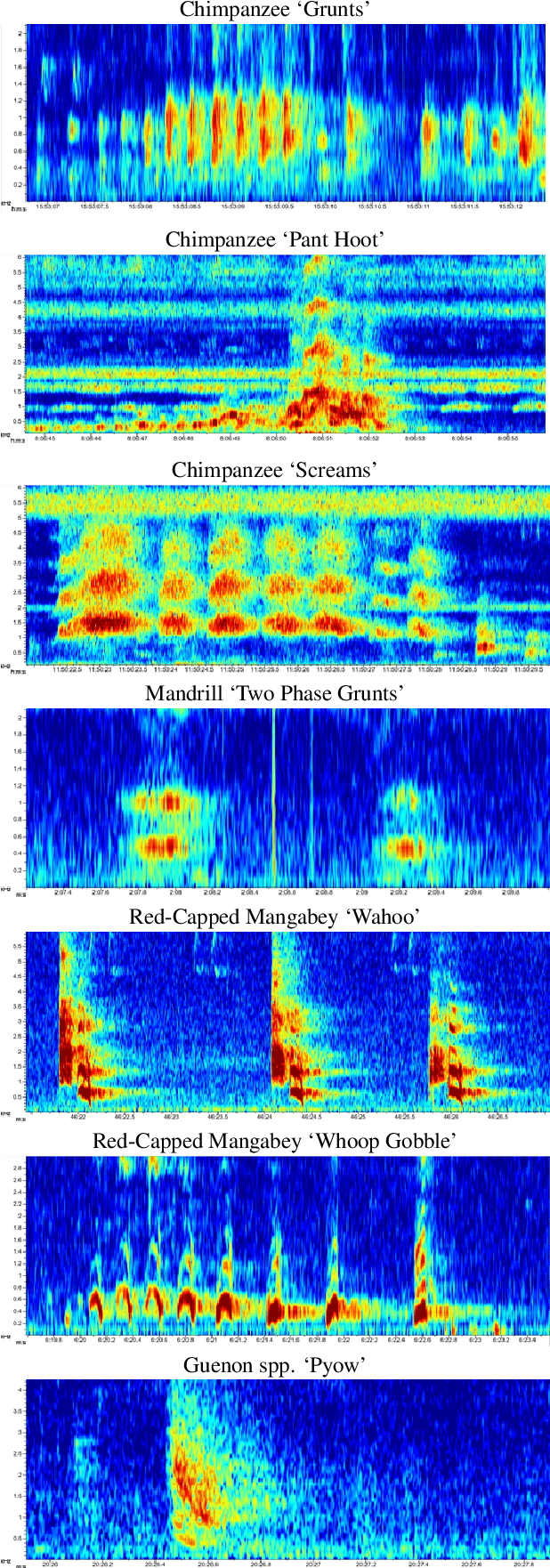
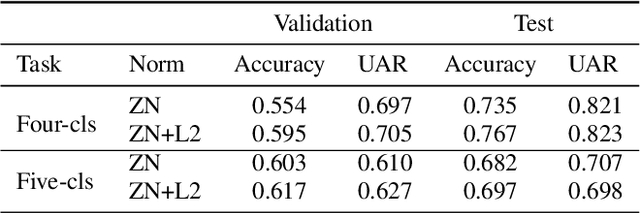
Automated classification of animal vocalisations is a potentially powerful wildlife monitoring tool. Training robust classifiers requires sizable annotated datasets, which are not easily recorded in the wild. To circumvent this problem, we recorded four primate species under semi-natural conditions in a wildlife sanctuary in Cameroon with the objective to train a classifier capable of detecting species in the wild. Here, we introduce the collected dataset, describe our approach and initial results of classifier development. To increase the efficiency of the annotation process, we condensed the recordings with an energy/change based automatic vocalisation detection. Segmenting the annotated chunks into training, validation and test sets, initial results reveal up to 82% unweighted average recall (UAR) test set performance in four-class primate species classification.
An Audio-Video Deep and Transfer Learning Framework for Multimodal Emotion Recognition in the wild
Oct 20, 2020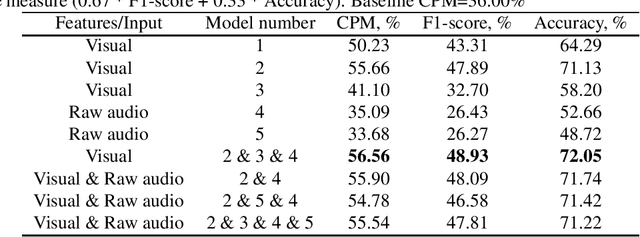
In this paper, we present our contribution to ABAW facial expression challenge. We report the proposed system and the official challenge results adhering to the challenge protocol. Using end-to-end deep learning and benefiting from transfer learning approaches, we reached a test set challenge performance measure of 42.10%.