 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effects of gender bias in word embeddings on depression prediction
Dec 15, 2022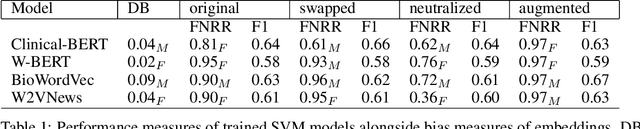
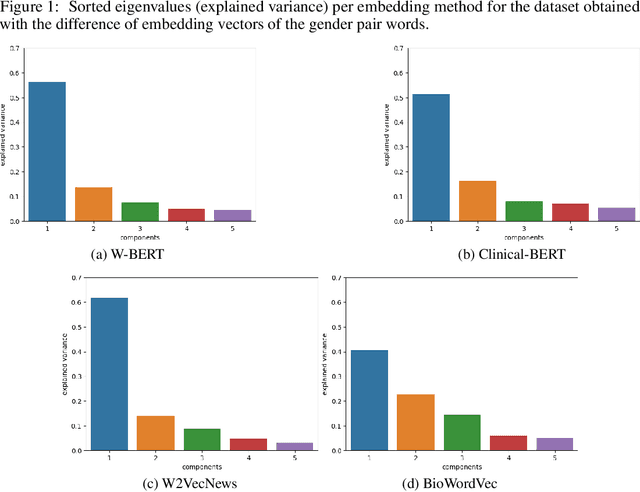
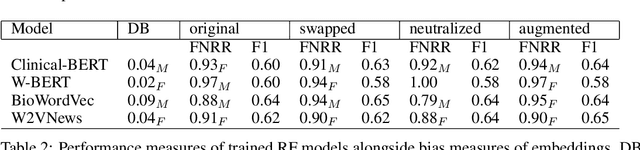
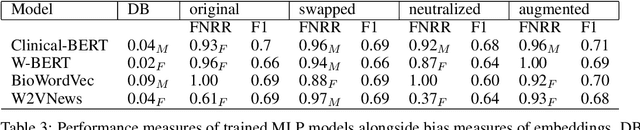
Word embeddings are extensively used in various NLP problems as a state-of-the-art semantic feature vector representation. Despite their success on various tasks and domains, they might exhibit an undesired bias for stereotypical categories due to statistical and societal biases that exist in the dataset they are trained on. In this study, we analyze the gender bias in four different pre-trained word embeddings specifically for the depression category in the mental disorder domain. We use contextual and non-contextual embeddings that are trained on domain-independent as well as clinical domain-specific data. We observe that embeddings carry bias for depression towards different gender groups depending on the type of embeddings. Moreover, we demonstrate that these undesired correlations are transferred to the downstream task for depression phenotype recognition. We find that data augmentation by simply swapping gender words mitigates the bias significantly in the downstream task.
Gender bias in (non)-contextual clinical word embeddings for stereotypical medical categories
Aug 08, 2022Clinical word embeddings are extensively used in various Bio-NLP problems as a state-of-the-art feature vector representation. Although they are quite successful at the semantic representation of words, due to the dataset - which potentially carries statistical and societal bias - on which they are trained, they might exhibit gender stereotypes. This study analyses gender bias of clinical embeddings on three medical categories: mental disorders, sexually transmitted diseases, and personality traits. To this extent, we analyze two different pre-trained embeddings namely (contextualized) clinical-BERT and (non-contextualized) BioWordVec. We show that both embeddings are biased towards sensitive gender groups but BioWordVec exhibits a higher bias than clinical-BERT for all three categories. Moreover, our analyses show that clinical embeddings carry a high degree of bias for some medical terms and diseases which is conflicting with medical literature. Having such an ill-founded relationship might cause harm in downstream applications that use clinical embeddings.
Fact sheet: Automatic Self-Reported Personality Recognition Track
Jul 22, 2022

We propose an informed baseline to help disentangle the various contextual factors of influence in this type of case studies. For this purpose, we analysed the correlation between the given metadata and the self-assigned personality trait scores and developed a model based solely on this information. Further, we compared the performance of this informed baseline with models based on state-of-the-art visual, linguistic and audio features. For the present dataset, a model trained solely on simple metadata features (age, gender and number of sessions) proved to have superior or similar performance when compared with simple audio, linguistic or visual features-based systems.