 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effects of gender bias in word embeddings on depression prediction
Paper and Code
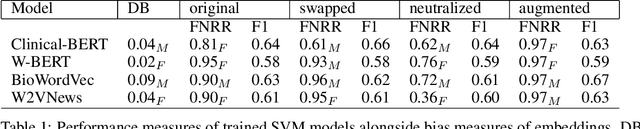
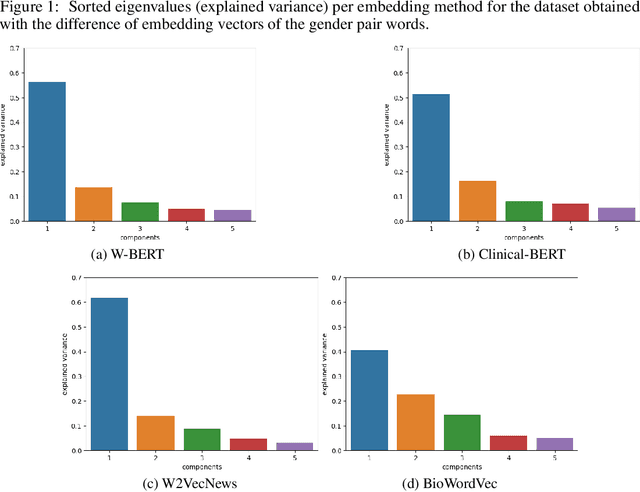
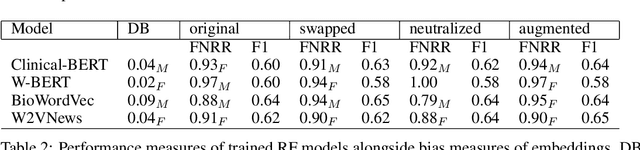
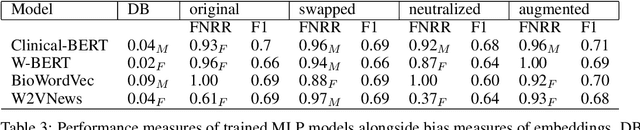
Word embeddings are extensively used in various NLP problems as a state-of-the-art semantic feature vector representation. Despite their success on various tasks and domains, they might exhibit an undesired bias for stereotypical categories due to statistical and societal biases that exist in the dataset they are trained on. In this study, we analyze the gender bias in four different pre-trained word embeddings specifically for the depression category in the mental disorder domain. We use contextual and non-contextual embeddings that are trained on domain-independent as well as clinical domain-specific data. We observe that embeddings carry bias for depression towards different gender groups depending on the type of embeddings. Moreover, we demonstrate that these undesired correlations are transferred to the downstream task for depression phenotype recognition. We find that data augmentation by simply swapping gender words mitigates the bias significantly in the downstream task.