 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam RAS in 9th ABAW Competition: Multimodal Compound Expression Recognition Approach
Jul 02, 2025Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by a Compound Expressions (CE) transformation module that uses Pair-Wise Probability Aggregation (PPA) and Pair-Wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach shows F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, which is comparable to the results of supervised approaches trained on target data. This demonstrates the effectiveness of the proposed approach for capturing CE without domain adaptation. The source code is publicly available.
Audio-Visual Compound Expression Recognition Method based on Late Modality Fusion and Rule-based Decision
Mar 29, 2024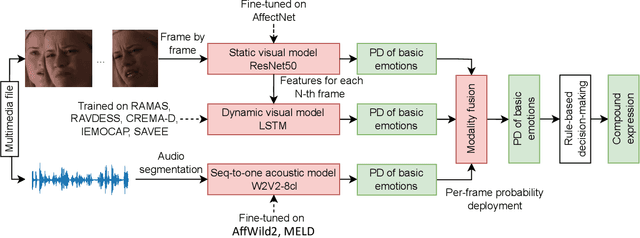
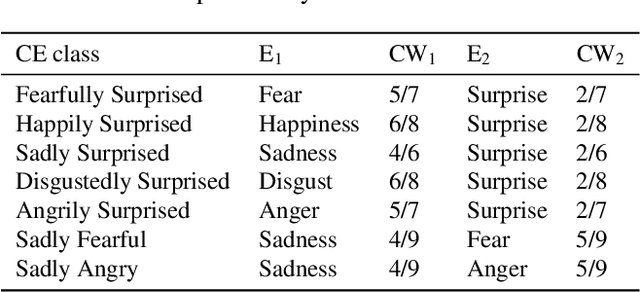
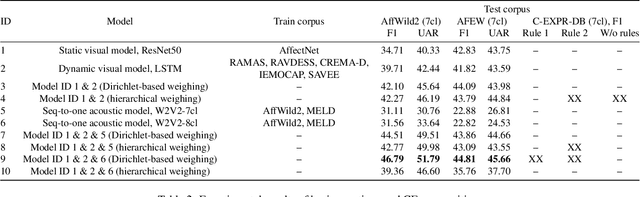
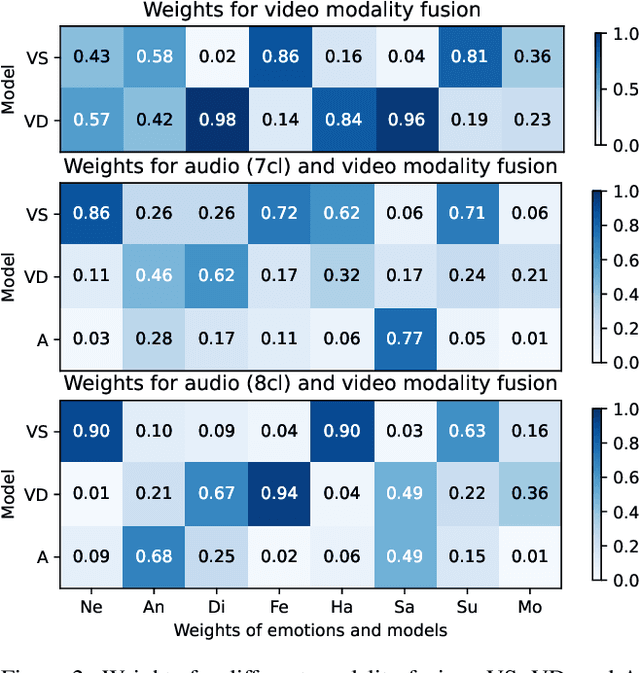
This paper presents the results of the SUN team for the Compound Expressions Recognition Challenge of the 6th ABAW Competition. We propose a novel audio-visual method for compound expression recognition. Our method relies on emotion recognition models that fuse modalities at the emotion probability level, while decisions regarding the prediction of compound expressions are based on predefined rules. Notably, our method does not use any training data specific to the target task. Thus, the problem is a zero-shot classification task. The method is evaluated in multi-corpus training and cross-corpus validation setups. Using our proposed method is achieved an F1-score value equals to 22.01% on the C-EXPR-DB test subset. Our findings from the challenge demonstrate that the proposed method can potentially form a basis for developing intelligent tools for annotating audio-visual data in the context of human's basic and compound emotions.
SUN Team's Contribution to ABAW 2024 Competition: Audio-visual Valence-Arousal Estimation and Expression Recognition
Mar 19, 2024
As emotions play a central role in human communication, automatic emotion recognition has attracted increasing attention in the last two decades. While multimodal systems enjoy high performances on lab-controlled data, they are still far from providing ecological validity on non-lab-controlled, namely 'in-the-wild' data. This work investigates audiovisual deep learning approaches for emotion recognition in-the-wild problem. We particularly explore the effectiveness of architectures based on fine-tuned Convolutional Neural Networks (CNN) and Public Dimensional Emotion Model (PDEM), for video and audio modality, respectively. We compare alternative temporal modeling and fusion strategies using the embeddings from these multi-stage trained modality-specific Deep Neural Networks (DNN). We report results on the AffWild2 dataset under Affective Behavior Analysis in-the-Wild 2024 (ABAW'24) challenge protocol.
An Audio-Video Deep and Transfer Learning Framework for Multimodal Emotion Recognition in the wild
Oct 20, 2020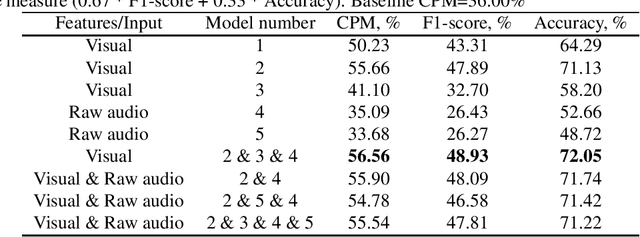
In this paper, we present our contribution to ABAW facial expression challenge. We report the proposed system and the official challenge results adhering to the challenge protocol. Using end-to-end deep learning and benefiting from transfer learning approaches, we reached a test set challenge performance measure of 42.10%.