 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021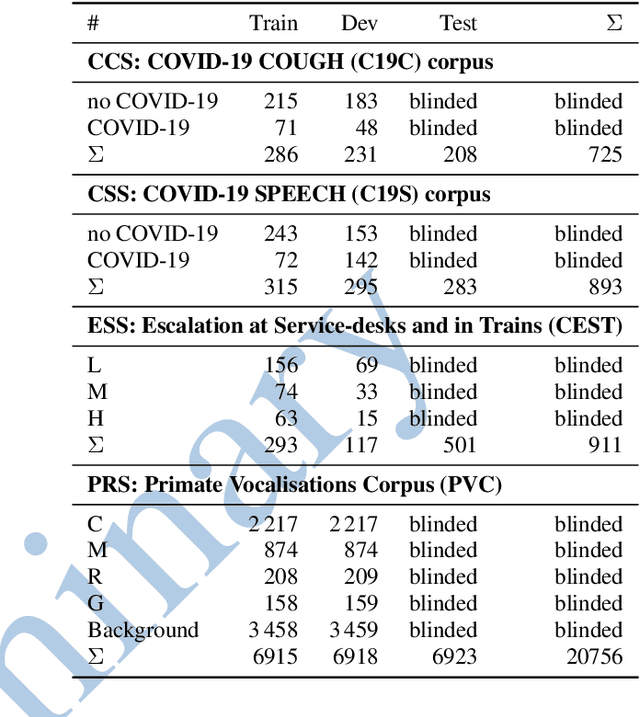
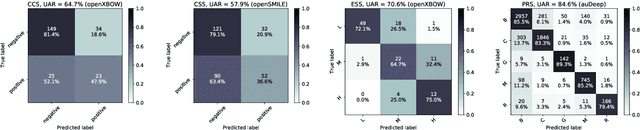
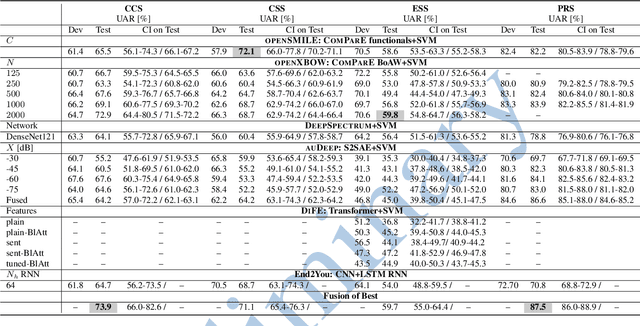
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
Introducing a Central African Primate Vocalisation Dataset for Automated Species Classification
Jan 25, 2021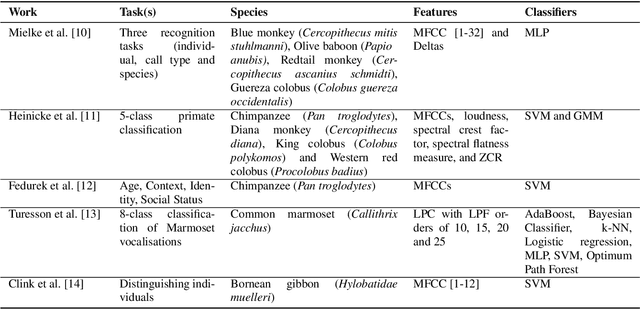
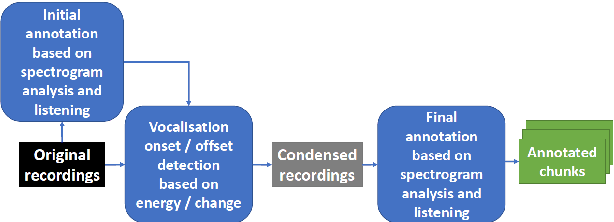
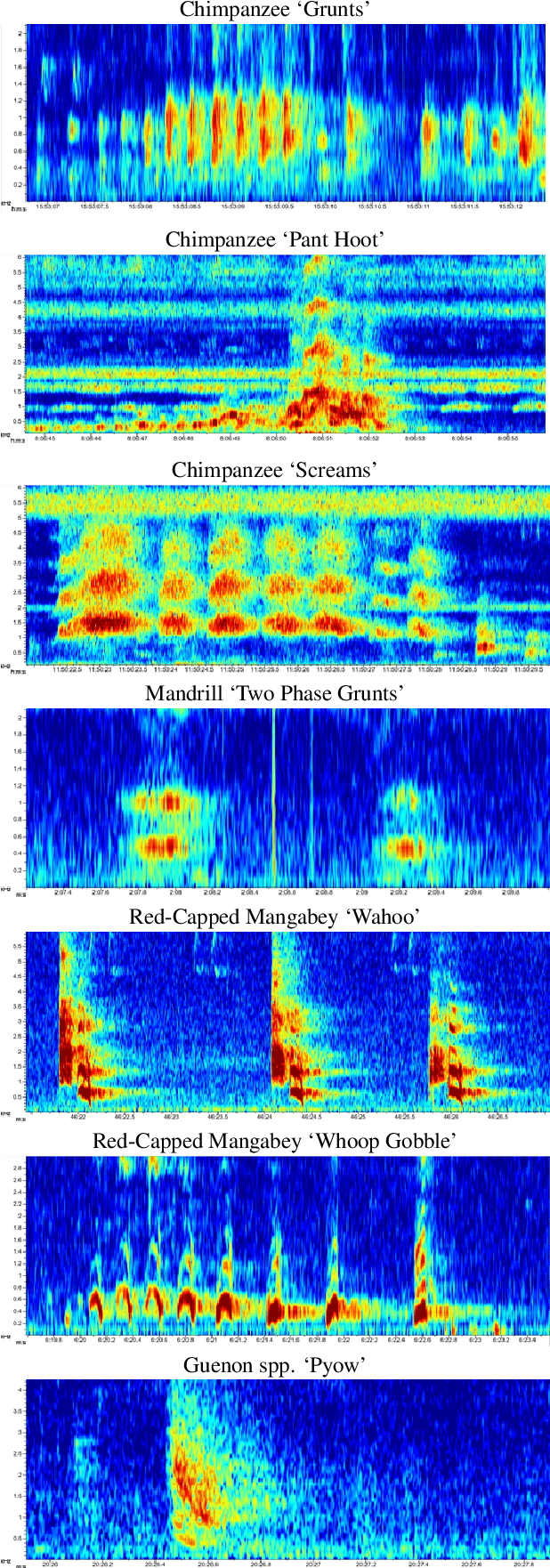
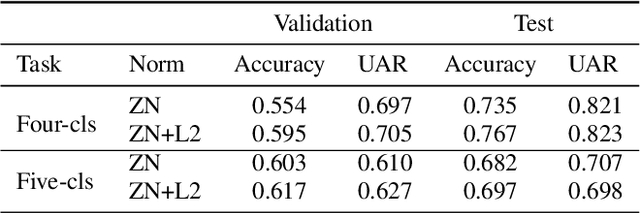
Automated classification of animal vocalisations is a potentially powerful wildlife monitoring tool. Training robust classifiers requires sizable annotated datasets, which are not easily recorded in the wild. To circumvent this problem, we recorded four primate species under semi-natural conditions in a wildlife sanctuary in Cameroon with the objective to train a classifier capable of detecting species in the wild. Here, we introduce the collected dataset, describe our approach and initial results of classifier development. To increase the efficiency of the annotation process, we condensed the recordings with an energy/change based automatic vocalisation detection. Segmenting the annotated chunks into training, validation and test sets, initial results reveal up to 82% unweighted average recall (UAR) test set performance in four-class primate species classification.