 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Constrained Fairness Estimation for Decision Trees
Dec 13, 2023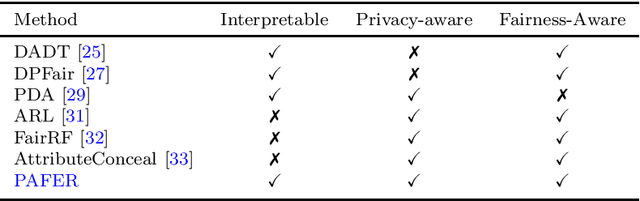
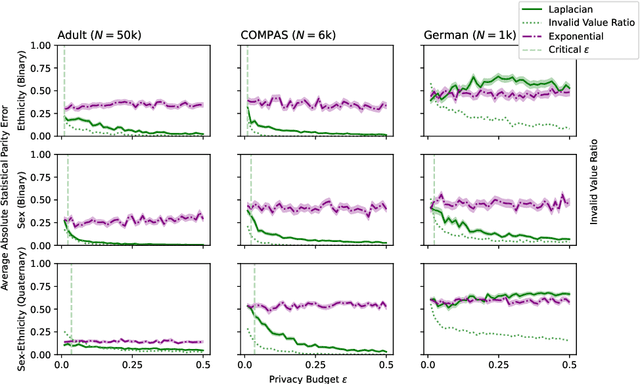


The protection of sensitive data becomes more vital, as data increases in value and potency. Furthermore, the pressure increases from regulators and society on model developers to make their Artificial Intelligence (AI) models non-discriminatory. To boot, there is a need for interpretable, transparent AI models for high-stakes tasks. In general, measuring the fairness of any AI model requires the sensitive attributes of the individuals in the dataset, thus raising privacy concerns. In this work, the trade-offs between fairness, privacy and interpretability are further explored. We specifically examine the Statistical Parity (SP) of Decision Trees (DTs) with Differential Privacy (DP), that are each popular methods in their respective subfield. We propose a novel method, dubbed Privacy-Aware Fairness Estimation of Rules (PAFER), that can estimate SP in a DP-aware manner for DTs. DP, making use of a third-party legal entity that securely holds this sensitive data, guarantees privacy by adding noise to the sensitive data. We experimentally compare several DP mechanisms. We show that using the Laplacian mechanism, the method is able to estimate SP with low error while guaranteeing the privacy of the individuals in the dataset with high certainty. We further show experimentally and theoretically that the method performs better for DTs that humans generally find easier to interpret.
Bursting the Burden Bubble? An Assessment of Sharma et al.'s Counterfactual-based Fairness Metric
Nov 21, 2022Machine learning has seen an increase in negative publicity in recent years, due to biased, unfair, and uninterpretable models. There is a rising interest in making machine learning models more fair for unprivileged communities, such as women or people of color. Metrics are needed to evaluate the fairness of a model. A novel metric for evaluating fairness between groups is Burden, which uses counterfactuals to approximate the average distance of negatively classified individuals in a group to the decision boundary of the model. The goal of this study is to compare Burden to statistical parity, a well-known fairness metric, and discover Burden's advantages and disadvantages. We do this by calculating the Burden and statistical parity of a sensitive attribute in three datasets: two synthetic datasets are created to display differences between the two metrics, and one real-world dataset is used. We show that Burden can show unfairness where statistical parity can not, and that the two metrics can even disagree on which group is treated unfairly. We conclude that Burden is a valuable metric, but does not replace statistical parity: it rather is valuable to use both.